Redis Key-Value数据库 【高级】
Redis Key-Value数据库 【高级】
文章目录
- Redis Key-Value数据库 【高级】
-
- 一、Redis持久化RDB
-
- 1、RDB是什么
- 2、RDB持久化流程
- 3、RDB保持策略
- 4、RDB备份
- 5、RDB优劣
- 二、Redis持久化AOF
-
- 1、AOF是什么
- 2、AOF持久化流程
- 3、AOF保持策略
- 4、AOF优劣
- 5、RDB/AOF如何选择
- 三、Redis主从复制
-
- 1、什么是redis主从复制
- 2、如何实现redis主从
-
- 2.1、一主二从
- 2.2、薪火相传
- 2.3、反客为主
- 3、复制原理
- 4、哨兵模式
-
- 4.1、什么是哨兵模式
- 4.2、如何实现sentinel
- 4.3、故障恢复
- 四、Redis集群
-
- 1、什么是redis集群
- 2、如何实现redis集群
- 3、slot
- 4、故障恢复
- 5、redis集群优劣
- 五、Redis6新功能
-
- 1、ACL
- 2、IO多线程
- 3、其它新功能
相关链接:
Redis Key-Value数据库【初级】:https://blog.csdn.net/qq_41822345/article/details/125527045
Redis Key-Value数据库【高级】:https://blog.csdn.net/qq_41822345/article/details/125568007
Redis Key-Value数据库【实战】:https://blog.csdn.net/qq_41822345/article/details/125568012
一、Redis持久化RDB
Redis 提供了2个不同形式的持久化方式。
-
RDB(Redis DataBase)
-
AOF(Append Of File)
1、RDB是什么
在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
2、RDB持久化流程
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件(dump.rdb)。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。但是最后一次持久化后的数据可能会丢失。
- Fork
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会被exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”。
一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
3、RDB保持策略
RDB是整个内存的压缩过的Snapshot。RDB的数据结构,可以配置复合的快照触发条件。
save #save时只管保存,其它不管,全部阻塞。手动保存。不建议。
save 3600 1 #格式:save 秒钟 写操作次数
save 300 100 #默认是1分钟内改了1万次,或5分钟内改了10次,或15分钟内改了1次。
save 60 10000
redis-cli config set save "" #禁用保存策略 不设置save指令,或者给save传入空字符串
stop-writes-on-bgsave-error #当Redis无法写入磁盘的话,直接关掉Redis的写操作。推荐yes.
rdbcompression #对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。推荐yes.
rdbchecksum #在存储快照后,可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。推荐yes.
bgsave #Redis会在后台异步进行快照操作, 快照同时还可以响应客户端请求。
lastsave #可以通过该命令获取最后一次成功执行快照的时间
flushall #该命令也会产生dump.rdb文件,但里面是空的,无意义
4、RDB备份
-
rdb的备份:
先通过config get dir查询rdb文件的目录;
将*.rdb的文件拷贝其它目录。 -
rdb的恢复:
关闭Redis;
先把备份的文件拷贝到工作目录下 cp dump2.rdb dump.rdb;
启动Redis,备份数据会直接加载。
5、RDB优劣
- 优势
适合大规模的数据恢复;
对数据完整性和一致性要求不高更适合使用;
节省磁盘空间;
恢复速度快。
- 劣势
Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑;
虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能;
在备份周期按一定间隔时间做一次备份,所以如果Redis意外down掉,就会丢失最后一次快照后的所有修改。
二、Redis持久化AOF
1、AOF是什么
Redis的 AOF 类似 mysql 的 binlog 日志。
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
2、AOF持久化流程
(1)客户端的请求写命令会被append追加到AOF缓冲区内;
(2)AOF缓冲区根据 AOF 持久化策略 [always,everysec,no] 将操作sync同步到磁盘的AOF文件中;
(3)AOF文件大小超过重写策略阈值或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;
(4)Redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的。
- Rewrite重写压缩
当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩, 只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof。
Rewrite重写原理:fork出一条新进程来将文件重写(也是先写临时文件最后再rename)。
no-appendfsync-on-rewrite yes #不写入aof文件只写入缓存,用户请求不会阻塞,但是在这段时间如果宕机会丢失这段时间的缓存数据。(降低数据安全性,提高性能)
no-appendfsync-on-rewrite no #还是会把数据往磁盘里刷,但是遇到重写操作,可能会发生阻塞。(数据安全,但是性能降低)
Rewrite触发机制:重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
auto-aof-rewrite-percentage #设置重写的基准值,文件达到100%时开始重写(文件是原来重写后文件的2倍时触发)
auto-aof-rewrite-min-size #设置重写的基准值,最小文件64MB。达到这个值开始重写。
3、AOF保持策略
AOF默认不开启,默认文件名:appendonly.aof。但当AOF和RDB同时开启,系统默认取AOF的数据(数据不会存在丢失)。
AOF的备份与恢复方式通RDB。
异常恢复:遇到 AOF文件损坏时,执行redis-check-aof --fix appendonly.aof可以修复adf文件。
类似MySQL的innodb_flush_log_at_trx_commit和sync_binlog
appendfsync always #始终同步,每次Redis的写入都会立刻记入日志;性能较差但数据完整性比较好
appendfsync everysec #每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
appendfsync no #redis不主动进行同步,把同步时机交给操作系统。
4、AOF优劣
- 优势
备份机制更稳健,丢失数据概率更低。
可读的日志文本,通过操作AOF文件,可以处理误操作。
- 劣势
比起RDB占用更多的磁盘空间。
恢复备份速度要慢。
每次读写都同步的话,有一定的性能压力。
存在个别Bug,造成恢复不能。
5、RDB/AOF如何选择
RDB持久化方式能够在指定的时间间隔能对数据进行快照存储。
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾。
Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
只做缓存:如果只希望数据在服务器运行的时候存在,你也可以不使用任何持久化方式。
同时开启两种持久化方式。在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整,
RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?
建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份), 快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
性能建议
因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则。
如果使用AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了。
代价,一是带来了持续的IO,二是AOF rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。
只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上。
默认超过原大小100%大小时重写可以改到适当的数值。
总结:
开启两个:官方推荐两个都启用。
开启一个:如果对数据不敏感,可以选单独用RDB。不建议单独用 AOF,因为可能会出现Bug。
开启0个:如果只是做纯内存缓存,可以都不用。
三、Redis主从复制
1、什么是redis主从复制
master/slaver机制:主机master数据更新后根据配置和策略, 自动同步到备机slave的一种机制。Master以写为主,Slave以读为主。
主从复制可以实现:读写分离,性能扩展;容灾快速恢复。
2、如何实现redis主从
- step1:创建redis服务6379配置文件【从库】
[root@k8s101 myredis]# cat redis6379.conf
include /opt/redis-6.2.6/redis.conf
pidfile "/var/run/redis_6379.pid"
port 6379
dbfilename "dump6379.rdb"
- step2:创建redis服务6380配置文件【从库】
[root@k8s101 myredis]# cat redis6380.conf
include /opt/redis-6.2.6/redis.conf
pidfile "/var/run/redis_6380.pid"
port 6380
dbfilename "dump6380.rdb"
- step3:创建redis服务6381配置文件【主库】
[root@k8s101 myredis]# cat redis6381.conf
include /opt/redis-6.2.6/redis.conf
pidfile "/var/run/redis_6381.pid"
port 6381
dbfilename "dump6381.rdb"
- step4:启动并检验
[root@k8s101 myredis]# redis-server /root/myredis/redis6379.conf
[root@k8s101 myredis]# redis-server /root/myredis/redis6380.conf
[root@k8s101 myredis]# redis-server /root/myredis/redis6381.conf
[root@k8s101 myredis]# ps -ef|grep redis
root 109532 51679 0 17:20 pts/2 00:00:00 redis-cli
root 117623 1 0 17:23 ? 00:00:00 redis-server *:6379
root 117901 1 0 17:23 ? 00:00:00 redis-server *:6380
root 118090 1 0 17:23 ? 00:00:00 redis-server *:6381
[root@k8s101 myredis]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6381
... ...
[root@k8s101 myredis]# redis-cli -p 6381
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:2
... ...
如果主机6381挂掉,重启就行。
2.1、一主二从
前面搭建的这种就属于最简单的一主二从模型。
几个问题:
切入点问题,slave1、slave2是从头开始复制还是从切入点开始复制?比如从k4进来,那之前的k1、k2、k3是否也可以复制?→ 从头开始复制
从机是否可以写?set可否?→ 不可以写
主机shutdown后情况如何?从机是上位还是原地待命?→ 原地待命
主机又回来了后,主机新增记录,从机还能否顺利复制?→ 可以
其中一台从机down后情况如何?依照原有它能跟上大部队吗?→ 可以
2.2、薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他 slaves的连接和同步请求,那么该slave作为链条中下一个的master,可以有效减轻master的写压力,去中心化降低风险。
用 slaveof
中途变更转向:会清除之前的数据,重新建立拷贝最新的。
风险是一旦某个slave宕机,后面的slave都没法备份。如果主机挂了,从机还是从机,无法写数据。
2.3、反客为主
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。
需要手动执行 slaveof no one 将从机变为主机。
3、复制原理
复制延时:由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
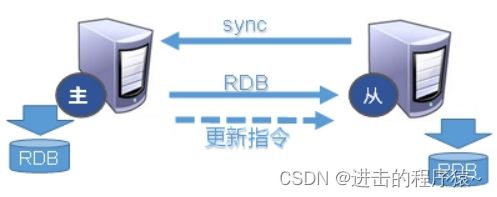
- Slave启动成功连接到master后会发送一个sync命令。
- Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行【即持久化】完毕之后,master将传送整个RDB数据文件到slave,以完成一次完全同步。
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步。
- 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行。
4、哨兵模式
4.1、什么是哨兵模式
哨兵模式下需要启动哨兵服务提供自动选主服务。
哨兵模式是反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
4.2、如何实现sentinel
-
step1:调整为一主两仆模式。
-
step2:创建redis服务6381哨兵配置文件
sentinel.conf,文件名字绝不能错。 -
step3:启动哨兵服务。
#文件内容如下:其中mymaster为监控对象起的服务器名称, 1 为至少有多少个哨兵同意迁移的数量。
[root@k8s101 myredis]# vim /root/myredis/sentinel.conf
[root@k8s101 myredis]# cat /root/myredis/sentinel.conf
sentinel monitor mymaster 127.0.0.1 6381 1
[root@k8s101 myredis]# redis-sentinel /root/myredis/sentinel.conf
84661:X 03 Jul 2022 00:32:55.049 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
84661:X 03 Jul 2022 00:32:55.049 # Redis version=6.2.6, bits=64, commit=00000000, modified=0, pid=84661, just started
84661:X 03 Jul 2022 00:32:55.049 # Configuration loaded
84661:X 03 Jul 2022 00:32:55.050 * Increased maximum number of open files to 10032 (it was originally set to 1024).
84661:X 03 Jul 2022 00:32:55.050 * monotonic clock: POSIX clock_gettime
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 6.2.6 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 84661
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | https://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
84661:X 03 Jul 2022 00:32:55.053 # Sentinel ID is 26c0ceda67142eacef06bc99a3d12d84550cf615
84661:X 03 Jul 2022 00:32:55.053 # +monitor master mymaster 127.0.0.1 6381 quorum 1
84661:X 03 Jul 2022 00:32:55.054 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:32:55.056 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
#step1:kill掉6381之后,新主登基
84661:X 03 Jul 2022 00:49:42.737 # +sdown master mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:42.737 # +odown master mymaster 127.0.0.1 6381 #quorum 1/1
84661:X 03 Jul 2022 00:49:42.737 # +new-epoch 1
84661:X 03 Jul 2022 00:49:42.737 # +try-failover master mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:42.743 # +vote-for-leader 26c0ceda67142eacef06bc99a3d12d84550cf615 1
84661:X 03 Jul 2022 00:49:42.743 # +elected-leader master mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:42.743 # +failover-state-select-slave master mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:42.834 # +selected-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:42.834 * +failover-state-send-slaveof-noone slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:42.896 * +failover-state-wait-promotion slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:43.232 # +promoted-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:43.232 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:43.291 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:43.867 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:43.868 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:43.931 # +failover-end master mymaster 127.0.0.1 6381
84661:X 03 Jul 2022 00:49:43.931 # +switch-master mymaster 127.0.0.1 6381 127.0.0.1 6379
#step2:群仆俯首
84661:X 03 Jul 2022 00:49:43.931 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
84661:X 03 Jul 2022 00:49:43.931 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
84661:X 03 Jul 2022 00:50:13.950 # +sdown slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
#step3:旧主俯首
84661:X 03 Jul 2022 00:50:54.402 # -sdown slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
84661:X 03 Jul 2022 00:51:04.422 * +convert-to-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
- step4:验证:当主机挂掉,从机选举中产生新的主机。
哪个从机会被选举为主机呢?根据优先级别:slave-priority 。原主机重启后会变为从机。
4.3、故障恢复
当主机宕机之后,哨兵模式下会在从机中重新选举出主机的过程就是故障恢复。
step1:新主登基。主服务下线之后,从所有从服务中挑选一个从服务,将其转成主服务。选择条件依次为:
1、选择优先级靠前的【即slave-priority最小的】;→2、选择偏移量最大的【即数据最全的】;→3、选择runid最小的【每个redis实例启动后都会随机生成一个40位的runid】
step2:群仆俯首。挑选出新主之后,sentinel哨兵向原主服务的从服务发送slaveof 新主命令。复制新master。
step3:旧主俯首。原主重新上线之后,sentinel哨兵向原主发送slaveof新主命令,原主变为从。
四、Redis集群
Redis主从并不能解决如下场景问题:
1、容量问题,redis如何进行扩容?
2、并发写场景下,redis如何分摊?
3、无论是哪种主从模式,都需要手动修改对应的主机ip:端口信息。
Redis集群,就是 无中心化集群 配置。它可以解决上述问题。
1、什么是redis集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
2、如何实现redis集群
- step1:初始化环境【将rdb,aof文件都删除掉,或者直接新建一个文件夹】
[root@k8s101 myredis]# mkdir /root/myredis/cluster
/root/myredis/cluster
[root@k8s101 myredis]# cd /root/myredis/cluster
[root@k8s101 cluster]# pwd
/root/myredis/cluster
- step2:创建redis6379.conf
[root@k8s101 cluster]# vim redis6379.conf
[root@k8s101 cluster]# cat redis6379.conf
include /opt/redis-6.2.6/redis.conf
port 6379
pidfile "/var/run/redis_6379.pid"
dbfilename "dump6379.rdb"
dir "/root/myredis/cluster"
logfile "/root/myredis/cluster/redis_err_6379.log"
cluster-enabled yes # 打开集群模式
cluster-config-file nodes-6379.conf # 设定节点配置文件名【自动生成】
cluster-node-timeout 15000 #设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
- step3:拷贝多个redis63xx.conf文件。
[root@k8s101 cluster]# cp redis6379.conf redis6380.conf
[root@k8s101 cluster]# cp redis6379.conf redis6381.conf
[root@k8s101 cluster]# cp redis6379.conf redis6389.conf
[root@k8s101 cluster]# cp redis6379.conf redis6390.conf
[root@k8s101 cluster]# cp redis6379.conf redis6391.conf
[root@k8s101 cluster]# vim redis6380.conf
[root@k8s101 cluster]# vim redis6381.conf
[root@k8s101 cluster]# vim redis6389.conf
[root@k8s101 cluster]# vim redis6390.conf
[root@k8s101 cluster]# vim redis6391.conf
# 快捷集体替换所有字符串
:%s/6379/6380
5 次替换,共 5 行
- step4:启动所有节点。
[root@k8s101 cluster]# redis-server redis6379.conf
[root@k8s101 cluster]# redis-server redis6380.conf
[root@k8s101 cluster]# redis-server redis6381.conf
[root@k8s101 cluster]# redis-server redis6389.conf
[root@k8s101 cluster]# redis-server redis6390.conf
[root@k8s101 cluster]# redis-server redis6391.conf
[root@k8s101 cluster]# ps -ef|grep redis
root 34613 1 0 10:09 ? 00:00:00 redis-server *:6379 [cluster]
root 35146 1 0 10:09 ? 00:00:00 redis-server *:6380 [cluster]
root 35273 1 0 10:09 ? 00:00:00 redis-server *:6381 [cluster]
root 35596 1 0 10:10 ? 00:00:00 redis-server *:6389 [cluster]
root 35754 1 0 10:10 ? 00:00:00 redis-server *:6390 [cluster]
root 35897 1 0 10:10 ? 00:00:00 redis-server *:6391 [cluster]
root 36119 13526 0 10:10 pts/0 00:00:00 grep --color=auto redis
[root@k8s101 cluster]# ll
总用量 72
-rw-r--r-- 1 root root 0 7月 3 10:09 appendonly.aof
-rw-r--r-- 1 root root 114 7月 3 10:09 nodes-6379.conf
-rw-r--r-- 1 root root 114 7月 3 10:09 nodes-6380.conf
-rw-r--r-- 1 root root 114 7月 3 10:09 nodes-6381.conf
-rw-r--r-- 1 root root 114 7月 3 10:10 nodes-6389.conf
-rw-r--r-- 1 root root 114 7月 3 10:10 nodes-6390.conf
-rw-r--r-- 1 root root 114 7月 3 10:10 nodes-6391.conf
-rw-r--r-- 1 root root 268 7月 3 10:04 redis6379.conf
-rw-r--r-- 1 root root 268 7月 3 10:05 redis6380.conf
-rw-r--r-- 1 root root 268 7月 3 10:08 redis6381.conf
-rw-r--r-- 1 root root 268 7月 3 10:08 redis6389.conf
-rw-r--r-- 1 root root 268 7月 3 10:09 redis6390.conf
-rw-r--r-- 1 root root 268 7月 3 10:09 redis6391.conf
-rw-r--r-- 1 root root 1028 7月 3 10:09 redis_err_6379.log
-rw-r--r-- 1 root root 1028 7月 3 10:09 redis_err_6380.log
-rw-r--r-- 1 root root 1028 7月 3 10:09 redis_err_6381.log
-rw-r--r-- 1 root root 1028 7月 3 10:10 redis_err_6389.log
-rw-r--r-- 1 root root 1028 7月 3 10:10 redis_err_6390.log
-rw-r--r-- 1 root root 1028 7月 3 10:10 redis_err_6391.log
- step5:组合6个节点形成一个集群【–replicas 1 采用最简单的方式配置集群,一台主机,一台从机,正好三组】
[root@k8s101 cluster]# redis-cli --cluster create --cluster-replicas 1 192.168.168.101:6379 192.168.168.101:6380 192.168.168.101:6381 192.168.168.101:6389 192.168.168.101:6390 192.168.168.101:6391
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.168.101:6390 to 192.168.168.101:6379
Adding replica 192.168.168.101:6391 to 192.168.168.101:6380
Adding replica 192.168.168.101:6389 to 192.168.168.101:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: c240407b244675710aac7896690ca29de603310b 192.168.168.101:6379
slots:[0-5460] (5461 slots) master
M: 57d3925a5e3ec7a9d96b881feb66097094a9ce07 192.168.168.101:6380
slots:[5461-10922] (5462 slots) master
M: 15f774ab47d7bc37ef4cb453d346992f41757c56 192.168.168.101:6381
slots:[10923-16383] (5461 slots) master
S: e6417879a08183b37df8108e4e66781bdcbc4ea9 192.168.168.101:6389
replicates c240407b244675710aac7896690ca29de603310b
S: 61cfc3fc6393594e9a4e7172d5362cb105d2e717 192.168.168.101:6390
replicates 57d3925a5e3ec7a9d96b881feb66097094a9ce07
S: fe9b00713383327a4d50043f6b7ae3ff8e23cf2c 192.168.168.101:6391
replicates 15f774ab47d7bc37ef4cb453d346992f41757c56
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 192.168.168.101:6379)
M: c240407b244675710aac7896690ca29de603310b 192.168.168.101:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: fe9b00713383327a4d50043f6b7ae3ff8e23cf2c 192.168.168.101:6391
slots: (0 slots) slave
replicates 15f774ab47d7bc37ef4cb453d346992f41757c56
M: 15f774ab47d7bc37ef4cb453d346992f41757c56 192.168.168.101:6381
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: e6417879a08183b37df8108e4e66781bdcbc4ea9 192.168.168.101:6389
slots: (0 slots) slave
replicates c240407b244675710aac7896690ca29de603310b
M: 57d3925a5e3ec7a9d96b881feb66097094a9ce07 192.168.168.101:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 61cfc3fc6393594e9a4e7172d5362cb105d2e717 192.168.168.101:6390
slots: (0 slots) slave
replicates 57d3925a5e3ec7a9d96b881feb66097094a9ce07
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
- step6:要以集群方式登录验证【-c 采用集群策略连接,再录入、查询键值对可以自动重定向切换到相应的主机】
[root@k8s101 cluster]# redis-cli -p 6379
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set k1 v1
(error) MOVED 12706 192.168.168.101:6381 #普通方式登录,存储数据时,会出现MOVED重定向操作
127.0.0.1:6379>
[root@k8s101 cluster]# redis-cli -c -p 6379 #集群方式登录
127.0.0.1:6379> set k1 v1
-> Redirected to slot [12706] located at 192.168.168.101:6381
OK
192.168.168.101:6381> CLUSTER NODES #查看集群信息【一个集群至少要有三个主节点】
c240407b244675710aac7896690ca29de603310b 192.168.168.101:6379@16379 master - 0 1656814420157 1 connected 0-5460
fe9b00713383327a4d50043f6b7ae3ff8e23cf2c 192.168.168.101:6391@16391 slave 15f774ab47d7bc37ef4cb453d346992f41757c56 0 1656814420000 3 connected
57d3925a5e3ec7a9d96b881feb66097094a9ce07 192.168.168.101:6380@16380 master - 0 1656814422175 2 connected 5461-10922
15f774ab47d7bc37ef4cb453d346992f41757c56 192.168.168.101:6381@16381 myself,master - 0 1656814421000 3 connected 10923-16383
61cfc3fc6393594e9a4e7172d5362cb105d2e717 192.168.168.101:6390@16390 slave 57d3925a5e3ec7a9d96b881feb66097094a9ce07 0 1656814419149 2 connected
e6417879a08183b37df8108e4e66781bdcbc4ea9 192.168.168.101:6389@16389 slave c240407b244675710aac7896690ca29de603310b 0 1656814421167 1 connected
192.168.168.101:6381>
3、slot
在执行组合集群命令之后会输出:All 16384 slots covered
[root@k8s101 cluster]# redis-cli --cluster create --cluster-replicas 1 192.168.168.101:6379 192.168.168.101:6380 192.168.168.101:6381 192.168.168.101:6389 192.168.168.101:6390 192.168.168.101:6391
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460 #节点 0 负责处理 0 号至 5460 号插槽。
Master[1] -> Slots 5461 - 10922 #节点 1 负责处理 5461 号至 10922 号插槽。
Master[2] -> Slots 10923 - 16383 #节点 2 负责处理 10923 号至 16383 号插槽。
.... ....
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。
举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5460 号插槽。
节点 B 负责处理 5461 号至 10922 号插槽。
节点 C 负责处理 10923 号至 16383 号插槽。
不在一个slot下的键值,是不能使用mget,mset等多键操作。
可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。
192.168.168.101:6381> mset k1 v1 k2 v2 k3 v3
(error) CROSSSLOT Keys in request don't hash to the same slot
192.168.168.101:6381> mset k1{group1} v1 k2{group1} v2 k3{group1} v3
-> Redirected to slot [7859] located at 192.168.168.101:6380
OK
192.168.168.101:6380> CLUSTER KEYSLOT group1 # 获取其slot
(integer) 7859
192.168.168.101:6380> cluster countkeysinslot 7859 # 获取该slot槽中的键的个数
(integer) 3
192.168.168.101:6380>
4、故障恢复
如果主节点下线?从节点能否自动升为主节点?注意:cluster-node-timeout 为15秒超时。
主节点恢复后,主从关系会如何?主节点回来变成从机。
如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
如果某一段插槽的主从都挂掉,而 cluster-require-full-coverage 为yes ,那么 ,整个集群都挂掉
如果某一段插槽的主从都挂掉,而 cluster-require-full-coverage 为no ,那么,该插槽数据全都不能使用,也无法存储。
5、redis集群优劣
- Redis集群提供以下好处:
实现扩容
分摊压力
无中心配置相对简单
- Redis 集群的不足:
多键操作是不被支持的。
多键的Redis事务是不支持的。lua脚本不支持。
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
五、Redis6新功能
1、ACL
ACL是Access Control List(访问控制列表)的缩写,该功能允许根据可以执行的命令和可以访问的键来限制某些连接。
在Redis 5版本之前,Redis 安全规则只有密码控制 还有通过rename 来调整高危命令比如 flushdb , KEYS* , shutdown 等。Redis 6 则提供ACL的功能对用户进行更细粒度的权限控制:接入权限-用户名和密码;可以执行的命令 ;可以操作的 KEY。
127.0.0.1:6379> acl list #查看用户权限列表
1) "user default on nopass sanitize-payload ~* &* +@all"
# 用户名 启用 无密码 可操作key 可执行命令
127.0.0.1:6379> acl whoami #查看当前用户
"default"
127.0.0.1:6379> acl setuser user1 #创建新用户默认权限
OK
127.0.0.1:6379> acl setuser user2 on >password ~cached:* +get #设置有用户名、密码、ACL权限、并启用的用户
OK
127.0.0.1:6379> acl list
1) "user default on nopass sanitize-payload ~* &* +@all"
2) "user user1 off &* -@all"
3) "user user2 on #5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8 ~cached:* &* -@all +get"
127.0.0.1:6379> auth user2 password #切换用户,验证权限
OK
127.0.0.1:6379> acl whoami
(error) NOPERM this user has no permissions to run the 'acl' command or its subcommand
2、IO多线程
IO多线程其实指客户端交互部分的网络IO交互处理模块多线程,而非执行命令多线程。Redis6执行命令依然是单线程。
Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。之所以这么设计是不想因为多线程而变得复杂,需要去控制 key、lua、事务,LPUSH/LPOP 等等的并发问题。整体的设计大体如下:
相关链接:https://blog.csdn.net/qq_41822345/article/details/124653958
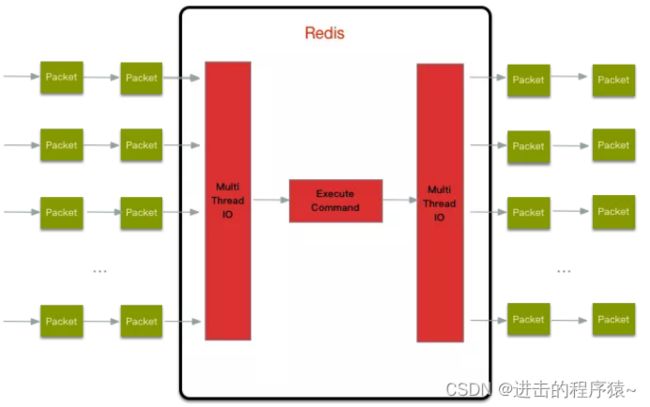
另外,多线程IO默认也是不开启的,需要在配置文件中配置。
io-threads-do-reads yes #开启多线程
io-threads 4
3、其它新功能
- 工具支持 Cluster
之前老版Redis想要搭集群需要单独安装 ruby 环境,Redis 5 将 redis-trib.rb 的功能集成到 redis-cli 。另外官方 redis-benchmark 工具开始支持 cluster 模式了,通过多线程的方式对多个分片进行压测。
- RESP3新的 Redis 通信协议
优化服务端与客户端之间通信。
- Client side caching客户端缓存
基于 RESP3 协议实现的客户端缓存功能。为了进一步提升缓存的性能,将客户端经常访问的数据cache到客户端。减少TCP网络交互。
- proxy集群代理模式
Proxy 功能,让 Cluster 拥有像单实例一样的接入方式,降低大家使用cluster的门槛。不过需要注意的是代理不改变 Cluster 的功能限制,不支持的命令还是不会支持,比如跨 slot 的多Key操作。
- Modules API
Redis 6中模块API开发进展非常大,因为Redis Labs为了开发复杂的功能,从一开始就用上Redis模块。Redis可以变成一个框架,利用Modules来构建不同系统,而不需要从头开始写然后还要BSD许可。Redis一开始就是一个向编写各种系统开放的平台。