Kubernetes 1.19.3
OS: CentOS 7.9.2009
Kernel: 5.4.94-1.el7.elrepo.x86_64
Docker: 20.10.6
先说结论,runc v1.0.0-rc93 有 bug,会导致 docker hang 住。
发现问题
线上告警提示集群中存在 2-3 个 K8s 节点处于 NotReady 的状态,并且 NotReady 状态一直持续。
- kubectl describe node,有 NotReady 相关事件。
![]()
- 登录问题机器后,查看节点负载情况,一切正常。
- 查看 kubelet 日志,发现 PLEG 时间过长,导致节点被标记为 NotReady。

- docker ps 正常。
- 执行 ps 查看进程,发现存在几个 runc init 的进程。runc 是 containerd 启动容器时调用的 OCI Runtime 程序。初步怀疑是 docker hang 住了。
![]()
要解决这个问题可以通过两种方法,首先来看一下 A 方案。
解决方案 A
针对 docker hang 住这样的现象,通过搜索资料后发现了以下两篇文章里也遇到了相似的问题:
- docker hang 问题排查[https://www.likakuli.com/post...]
- Docker hung 住问题解析系列(一):pipe 容量不够[https://juejin.cn/post/689155...]
这两篇文章都提到了是由于 pipe 容量不够导致 runc init 往 pipe 写入卡住了,将 /proc/sys/fs/pipe-user-pages-soft 的限制放开,就能解决问题。
于是,查看问题主机上 /proc/sys/fs/pipe-user-pages-soft 设置的是 16384。所以将它放大 10 倍 echo 163840 > /proc/sys/fs/pipe-user-pages-soft,然而 kubelet 还是没有恢复正常,pleg 报错日志还在持续,runc init 程序也没有退出。
考虑到 runc init 是 kubelet 调用 CRI 接口创建的,可能需要将 runc init 退出才能使 kubelet 退出。而根据文章中的说明,只需要将对应的 pipe 中的内容读取掉,runc init 就能退出。因为读取 pipe 的内容可以利用「UNIX/Linux 一切皆文件」的原则,通过 lsof -p 查看 runc init 打开的句柄信息,获取写入类型的 pipe 对应的编号(可能存在多个),依次执行 cat /proc/$pid/fd/$id 的方式,读取 pipe 中的内容。尝试了几个后,runc init 果然退出了。
再次检查,节点状态切换成 Ready,pleg 报错日志也消失了,观察一天也没有出现节点 NotReady 的情况,问题(临时)解决。
对解决方案 A 疑问
虽然问题解决了,但是仔细读 /proc/sys/fs/pipe-user-pages-soft 参数的说明文档,不难发现这个参数跟本次问题的根本原因不太对得上。
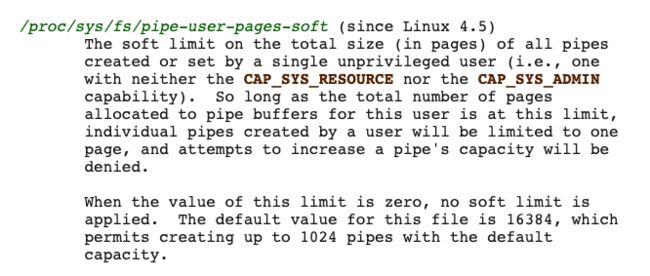
pipe-user-pages-soft 含义是对没有 CAP_SYS_RESOURCE CAP_SYS_ADMIN 权限的用户使用 pipe 容量大小做出限制,默认最多只能使用 1024 个 pipe,一个 pipe 容量大小为 16k。
那这里就有了疑问:
- dockerd/containerd/kubelet 等组件均通过 root 用户运行,并且 runc init 处于容器初始化阶段,理论上不会将 1024 个 pipe 消耗掉。因此,pipe-user-pages-soft 不会对 docker hang 住这个问题产生影响,但是实际参数放大后问题就消失了,解释不通。
- pipe 容量是固定,用户在创建 pipe 时无法声明容量。从线上来看,pipe 的确被建出来了,容量是固定的话,不应该因为用户使用 pipe 总量超过 pipe-user-pages-soft 限制,而导致无法写入的问题。是不是新创建的 pipe 容量变小了,导致原先可以写入的数据,本次无法写入了?
- 目前对 pipe-user-pages-soft 放大了 10 倍,放大 2 倍够不够,哪个值是最合适的值?
探索
定位问题最直接的方法,就是阅读源码。
先查看下 Linux 内核跟 pipe-user-pages-soft 相关的代码。线上内核版本为 5.4.94-1,切换到对应的版本进行检索。
static bool too_many_pipe_buffers_soft(unsigned long user_bufs)
{
unsigned long soft_limit = READ_ONCE(pipe_user_pages_soft);
return soft_limit && user_bufs > soft_limit;
}
struct pipe_inode_info *alloc_pipe_info(void)
{
...
unsigned long pipe_bufs = PIPE_DEF_BUFFERS; // #define PIPE_DEF_BUFFERS 16
...
if (too_many_pipe_buffers_soft(user_bufs) && is_unprivileged_user()) {
user_bufs = account_pipe_buffers(user, pipe_bufs, 2);
pipe_bufs = 2;
}
if (too_many_pipe_buffers_hard(user_bufs) && is_unprivileged_user())
goto out_revert_acct;
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),
GFP_KERNEL_ACCOUNT);
...
}在创建 pipe 时,内核会通过 too_many_pipe_buffers_soft 检查是否超过当前用户可使用 pipe 容量大小。如果发现已经超过,则将容量大小从 16 个 PAGE_SIZE 调整成 2 个 PAGE_SIZE。通过机器上执行 getconf PAGESIZE 可以获取到 PAGESIZE 是 4096 字节,也就是说正常情况下 pipe 大小为 164096 字节,但是由于超过限制,pipe 大小被调整成 24096 字节,这就有可能出现数据无法一次性写入 pipe 的问题,基本可以验证问题 2 的猜想。
至此,pipe-user-pages-soft 相关的逻辑也理顺了,相对还是比较好理解的。
那么,问题就回到了「为什么容器 root 用户 pipe 容量会超过限制」。
百分百复现
找到问题根本原因的第一步,往往是在线下环境复现问题。
由于线上环境已经都通过方案 A 做了紧急修复,因此,已经无法在线上分析问题了,需要找到一种必现的手段。
功夫不负有心人,在 issue 中找到了相同的问题,并且可以通过以下方法复现。
https://github.com/containerd...

echo 1 > /proc/sys/fs/pipe-user-pages-soft
while true; do docker run -itd --security-opt=no-new-privileges nginx; done执行以上命令之后,立刻就出现 runc init 卡住的情况,跟线上的现象是一致的。通过 lsof -p 查看 runc init 打开的文件句柄情况:
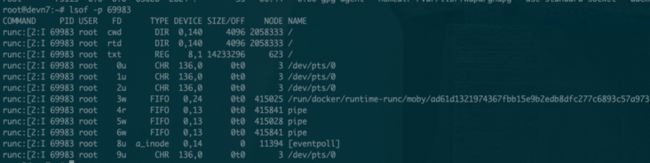
可以看到 fd4、fd5、fd6 都是 pipe 类型,其中,fd4 跟 fd6 编号都是 415841,是同一个 pipe。那么,如何来获取 pipe 大小来实际验证下「疑问 2」中的猜想呢?Linux 下没有现成的工具可以获取 pipe 大小,但是内核开放了系统调用 fcntl(fd, F_GETPIPE_SZ)可以获取到,代码如下:
#include
#include
#include
// Must use Linux specific fcntl header.
#include
int main(int argc, char *argv[]) {
int fd = open(argv[1], O_RDONLY);
if (fd < 0) {
perror("open failed");
return 1;
}
long pipe_size = (long)fcntl(fd, F_GETPIPE_SZ);
if (pipe_size == -1) {
perror("get pipe size failed.");
}
printf("pipe size: %ld\\n", pipe_size);
close(fd);
} 编译好之后,查看 pipe 大小情况如下:
重点看下 fd4 跟 fd6,两个句柄对应的是同一个 pipe,获取到的容量大小是 8192 = 2 PAGESIZE。所以的确是因为 pipe 超过软限制导致 pipe 容量被调整成了 2 PAGESIZE。
使用 A 方案解决问题后,我们来看一下 B 方案。
解决方案 B
https://github.com/opencontai...

该 bug 是在 runc v1.0.0-rc93 中引入的,并且在 v1.0.0-rc94 中通过上面的 PR 修复。那么,线上应该如何做修复呢?是不是需要把 docker 所有组件都升级呢?
如果把 dockerd/containerd/runc 等组件都升级的话,就需要将业务切走然后才能升级,整个过程相对比较复杂,并且风险较高。而且在本次问题中,出问题的只有 runc,并且只有新创建的容器受到影响。因此顺理成章考虑是否可以单独升级 runc?
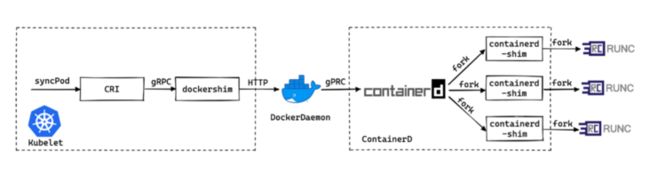
因为在 Kubernetes v1.19 版本中还没有弃用 dockershim,因此运行容器整个调用链为:kubelet → dockerd → containerd → containerd-shim → runc → container。不同于 dockerd/containerd 是后台运行的服务端,containerd-shim 调用 runc,实际是调用了 runc 二进制来启动容器。因此,我们只需要升级 runc,对于新创建的容器,就会使用新版本的 runc 来运行容器。
在测试环境验证了下,的确不会出现 runc init 卡住的情况了。最终,逐步将线上 runc 升级成 v1.1.1,并将 /proc/sys/fs/pipe-user-pages-soft 调整回原默认值。runc hang 住的问题圆满解决。
分析&总结
PR 做了什么修复?
Bug 的缘由。当容器开启 no-new-privileges 后,runc 会需要去卸载一段已经加载的 bpf 代码,然后重新加载 patch 后的 bpf 代码。在 bpf 的设计中,需要先获取已经加载的 bpf 代码,然后才能利用这段代码调用卸载接口。在获取 bpf 代码,内核开放了 seccomp_export_bpf 函数,runc 采用了 pipe 作为 fd 句柄传参来获取代码,由于 seccomp_export_bpf 函数是同步阻塞的,内核会将代码写入到 fd 句柄中,因此,如果 pipe 大小太小的话,就会出现 pipe 数据写满后无法写入 bpf 代码导致卡住的情况。
PR 中的解决方案。启动一个 goroutine 来及时读取 pipe 中的内容,而不是等数据写入完成后再读取。
为什么超过限制?
容器的 root 用户 UID 为 0,而宿主机的 root 用户 UID 也是 0。在内核统计 pipe 使用量时,认为是同一用户,没有做区分。所以,当 runc init 申请 pipe 时,内核判断当前用户没有特权,就查询 UID 为 0 的用户 pipe 使用量,由于内核统计的是所有 UID 为 0 用户(包括容器内) pipe 使用量的总和,所以已经超过了 /proc/sys/fs/pipe-user-pages-soft 中的限制。而实际容器 root 用户 pipe 使用量并没有超过限制。这就解释了前面提到的疑问 2。
所以我们最后做个总结,本次故障的原因是,操作系统对 pipe-user-pages-soft 有软限制,但是由于容器 root 用户的 UID 与宿主机一致都是 0,内核统计 pipe 使用量时没有做区分,导致当 UID 为 0 的用户 pipe 使用量超过软限制后,新分配的 pipe 容量会变小。而 runc 1.0.0-rc93 正好会因为 pipe 容量太小,导致数据无法完整写入,写入阻塞,一直同步等待,进而 runc init 卡住,kubelet pleg 状态异常,节点 NotReady。
修复方案,runc 通过 goroutine 及时读取 pipe 内容,防止写入阻塞。
参考资料
https://iximiuz.com/en/posts/...
https://medium.com/@mccode/un...
https://man7.org/linux/man-pa...
https://gist.github.com/cyfde...
https://github.com/containerd...
https://github.com/opencontai...