「Python数据分析」社会网络:networkx批量计算网络指标案例
从原始数据一步步得到合作网络之后,需要计算一些网络指标才能的到一些有意义的分析结论。
networkx是python中常用的社会网络分析包,里面支持各种图以及非常多指标计算函数。
官网:https://networkx.org
中文网站:https://www.osgeo.cn/networkx/index.html
案例
接下来是由合作网络中的边作为原始数据,计算各种网络指标的一个简单示例。
包括:生成网络图、计算指标、提取计算结果、存储五个基本步骤。有更多、更复杂的需求也都可以在这个框架基础上进行二次开发。
#* 随便编的原始数据
edges = [['a','b',2],
['a','c',1],
['a','d',2],
['b','d',3],
['c','d',2]]
#* 生成网络图
G = nx.Graph() # 创建一个图
G.add_weighted_edges_from(edges) # 添加合作关系
#* 计算指标
centrality = [nx.degree_centrality(G), # 这些函数的返回值是字典
nx.closeness_centrality(G),
nx.betweenness_centrality(G),
nx.clustering(G),
nx.eigenvector_centrality(G)]
average_shortest_path = nx.average_shortest_path_length(G, weight='weight') # 这个函数的返回值是浮点值
#* 提取计算结果
results = []
nodes = G.nodes() # 提取网络中节点列表 ['a', 'b', 'c', 'd']
for node in nodes: # 遍历所有节点,提取每个节点度中心性计算结果,并存储为[[节点1,结果],[节点2,结果],...]的形式
results.append([node,
centrality[0][node],
centrality[1][node],
centrality[2][node],
centrality[3][node],
centrality[4][node]])
#* 存储
with open("./test.csv","w",encoding="UTF-8",newline="") as csvfile: writer = csv.writer(csvfile)
writer.writerow(['node','degree','closeness','betweenness','clustering','eigenvector'])
writer.writerows(results)
writer.writerow(['average_shortest_path={}'.format(average_shortest_path)])
运行结果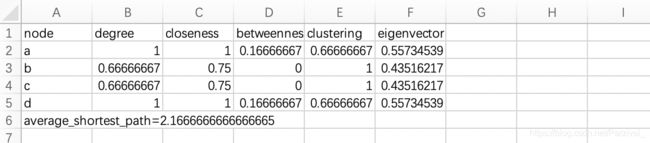
P.S. 再记录一下数shortest_path系列的另两个函数
shortest_path()返回最短路径
shortest_path_length()返回最短路径长度
# 返回值是一个字典
shortest_path = dict(nx.shortest_path(G, weight='weight'))
# 返回值是一个迭代器iterator
shortest_path_length = dict(nx.shortest_path_length(G, weight='weight'))
print(shortest_path,'\n',shortest_path_length)
结果
shortest_path:
{'a': {'a': ['a'], 'b': ['a', 'b'], 'c': ['a', 'c'], 'd': ['a', 'd']}, 'b': {'b': ['b'], 'a': ['b', 'a'], 'd': ['b', 'd'], 'c': ['b', 'a', 'c']}, 'c': {'c': ['c'], 'a': ['c', 'a'], 'd': ['c', 'd'], 'b': ['c', 'a', 'b']}, 'd': {'d': ['d'], 'a': ['d', 'a'], 'b': ['d', 'b'], 'c': ['d', 'c']}}
shortest_path_length:
{'a': {'a': 0, 'c': 1, 'b': 2, 'd': 2}, 'b': {'b': 0, 'a': 2, 'd': 3, 'c': 3}, 'c': {'c': 0, 'a': 1, 'd': 2, 'b': 3}, 'd': {'d': 0, 'a': 2, 'c': 2, 'b': 3}}