基于Transformer的通用视觉架构:Swin-Transformer带来多任务大范围性能提升
将Transformer引入视觉领域后,研究人员们一直在寻求更好的模型架构来适应视觉领域的通用任务。但将Transformer从NLP领域迁移到CV领域面临着众多挑战,与文本相比图像中的视觉实体尺度变化剧烈、图像分辨率很高,带来了多尺度建模与计算量巨大的严峻问题。
为了解决这些问题,研究人员提出了一种基于移动窗格和层级表达的通用架构。移动窗口将自注意力限制在一定范围内大幅度削减了计算量,同时也使得非局域窗口间的交互成为可能。
这一灵活架构适用于多种视觉任务并具有 (与图像大小的) 线性复杂度。实验表明这一架构在图像分类、目标检测和图像分割等多个任务上达到了目前的最领先水平,显示出了其作为视觉任务基础模型的强大潜力。

论文链接:
https://arxiv.org/abs/2103.14030
项目网站:
https://github.com/microsoft/Swin-Transformer

从CNNs迈向Transformer
自从AlexNet在ImageNet上取得重大突破后,CNNs便主导着各个视觉领域的研究,从架构规模、卷积结构等方向持续演进,在深度学习的发展历史中大放异彩,作为基础网络为各式各样的视觉任务提供了强有力的特征抽取和表达,极大地促进了整个视觉领域的繁荣发展。
另一方面在自然语言处理领域也诞生了以Transformer为代表的序列模型架构,利用attention机制为数据的长程依赖性建模大幅度提升了语言模型的性能。在自然语言领域取得的巨大成功让科学家们开始探索Transformer在计算机视觉领域应用的可能性,最近的研究展示了广阔的应用前景。
拓展Transformer的实用性、使其成为通用的视觉架构是本研究的努力方向。Transformer在视觉领域的应用挑战相比于自然语言处理主要体现在两方面。
其一是图像领域的实体尺度变化剧烈在目标检测任务中尤其如此,而现有transformer架构固定的token尺度无法适应如此大范围变化的目标尺寸;
其二是图像的像素分辨率远远高于文本中的单词,像语义分割这样涉及像素级稠密预测的视觉任务,Transformer中自注意力机制会带来非常庞大的计算(像素数的平方复杂度)。
为了克服这些问题,研究人员提出了一种新的视觉Transformer架构Swin Transformer,在线性计算复杂度的基础上构建了图像的层级特征图。下图展示了Swin Transformer架构以及与ViT的基本区别。其中Swin Transformer通过小图像片元和逐层进行邻域合并的方式构建层级特征表达,这样的架构使得模型可以实现与U-Net和FPN等架构类似的稠密预测任务。
而这一高效模型的线性计算复杂度则由图中非重叠窗口内的局域自注意力机制实现,由于每层窗口中的片元固定,所以与图像大小具有线性复杂度关系。而ViT中的特征图大小是固定的,且需要进行(对图像大小)二次复杂度的计算。
 Swin Transformer和ViT的架构区别
Swin Transformer和ViT的架构区别
Swin Transformer最为关键的设计在于连续自注意力层间,特征图上的窗划分口实现了半个窗宽的移动。这使得前一层的窗口间可以实现交互和联系,大幅度提升了模型的表达能力。同时在同一窗口内的查询都拥有相同的key序列,使得硬件内存更容易实现大大提升了模型运行的速度,降低延时。
这一架构在多种视觉任务上都实现了最先进的性能,也再一次展示了CV和NLP领域的相互促进,和视觉与-文本信号的融合建模的广阔前景,并为统一框架的提出打下了坚实的基础。下面就让我们一起来分析Swin Transformer的详细结构与实现吧。

Swin Transformer
Swin Transformer以原始图像片元像素作为输入,通过编码后得到像素的特征而后逐级传递最终获取图像的特征表达。在本研究中使用了4x4的片元作为输入,每个片元作为一个token,输入的维度为W/4xH/4x48,而后通过一次线性变换得到了W/4xH/4xC的特征表达。
通过本文提出的Swin Transformer block单元对输入特征进行计算。后续的层一方面将相邻的2x2片元特征进行衔接融合得到4C维度的特征,并输入2C的融合特征,而另一方面,在水平方向上图像分辨率也变成了W/8xH/8,最终生成了W/8xH/8x4C的特征。
以此类推,随着blcok的叠加,特征的维度依次变成了W/16xH/16x8C和W/32xH/32x16C,与VGG和ResNet等典型卷积模型的特征图分辨率一致,使其可便捷的成为相关模型的基础架构。
 Swin Transformer的基础架构示意图
Swin Transformer的基础架构示意图
Swin Transformer中最重要的模块是基于移动窗口构建的注意力模块,其内部结构如下图所示,包含了一个基于移动窗口的多头自注意力模块(shifted windows multi-head self attention, SW-MSA)和基于窗口的多头自注意力模块(W-MSA),其他的归一化层和两层的MLP与原来保持一致,并使用了GELU激活函数。
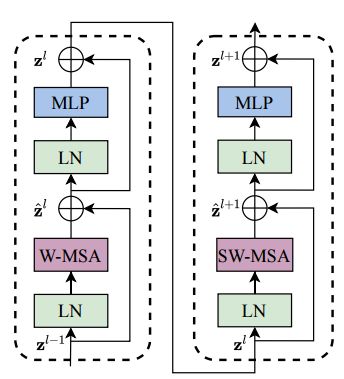
基于移动窗口的W-MSA和基于窗口的SW-MSA模块前后相连,实现不同窗格内特征的传递与交互
基于移动窗口的自注意力模块是本研究的关键所在,下面将详细介绍这一部分的原理和实现方法。

基于移动窗口的自注意力模块
标准的全局自注意机制需要计算每一个token和其他所有token的相关性,全局计算带来了与token数量二次方的复杂度。这一机制的计算量对于具有大量像素的稠密视觉预测任务十分庞大,很多时候巨大的计算量对于目前的硬件来说不易实现。
为了高效的实现这一模型,研究人员提出仅仅在局域窗口内进行自注意力计算,而窗口则来自于对图像的非重叠均匀划分。假设每个窗口中包含M x M个片元,整张图像共包含h x w个片元,那么标准的和基于窗口的全局注意力模块的计算复杂度如下:

可以看到标准的全局注意力计算方式与片元数量的二次关系带来了庞大的计算量,而基于窗格的方式由于M固定则仅仅成线性关系,使得高效计算成为可能。
但这种基于窗格的方式缺乏窗格间的交互,限制了模型的表达能力。为了实现窗格间的交互,研究人员提出了一种在连续特征层间移动窗口的方式来实现。这种机制中,第一个特征图窗格按照正常的方式将8x8的特征图分割为了4x4个窗格(M=4)。而后在下一层中将窗格整体移动(M/2,M/2),以此来实现窗格间的交互。

其中z为第l层的输出特征,W-MSA和SW-MSA分别代表了基于窗格的多头注意力机制和基于移动窗格的多头注意力机制。下图中展示了窗格移动带来的信息交互,前一层中不同窗格间的信息在下一层中被有效的链接在了一起。原来四个独立的窗格内的特征图在移动后都被部分分入新的窗格,从而实现了更为复杂的交互机制。
 基于移动窗格的自注意力机制计算
基于移动窗格的自注意力机制计算
虽然这种方式可以有效实现窗格间的交互和全局注意力,但却会带来窗格数量增加的问题。在移动后所有的窗格数量增加到了9个会带来相应计算量的提升。
一种简单方法的是将外围的小窗格都padding成与原来MxM大小,但这会带来(3x3)/(2x2)=2.25倍的计算量提升。为此研究人员提出了更为高效的解决方案,利用像左上角的循环移位操作(cyclic-shifting)来实现。
 基于circle shift的移动窗格计算
基于circle shift的移动窗格计算
此时9个窗格通过循环移位后由重新变回了4个窗格,保持了计算量的一致。此时每个窗格中包含了来自原来不同窗格中的特征图,此时要计算自注意力则需要引入一定的mask机制将不同窗格子窗格中的计算去除掉,仅仅计算同一个子窗格中的自注意力。实验表明这个机制使得模型的延时大大降低。

网络架构和实验结果
为了比较不同的模型容量及其性能,研究人员分别实现了Swin-Tiny、Swin-Small、Swin-Base、Swin-Large四种不同的模型,其配置主要区别在于C的维度和每个stage的层数上。

实验分别在图像分类ImageNet-1K、目标检测COCO、和语义分割ADE20K数据集上进行。下面的表格展示了Swin Transformer的强大能力。
首先在图像分类任务中,可以看到这一架构大幅超越了先前基于transformer的DeiT架构,与最先进的卷积模型相比也实现了速度与精度的平衡。值得注意的是下表中的卷积模型来自于架构搜索,而这里使用的基础型Swin-Base则还有很大的提升空间。

同样在目标检测任务中,本文提出的架构不仅超过了DeiT,同时也大幅优于各种基于卷积的先进架构。在COCO test-dev上实现了58.7 box AP 和 51.1 mask AP,分别超过了先前最好模型2.7和2.6个点。

最后在语义分割任务上,这一模型在ADE20k上比先前最好的SETR模型高出了3.2的mIoU,实现了最先进的性能。

如果想要了解更多细节和实验原理,请参考论文和项目网站。
编译: T.R From: MSRA
Illustrastion by Oleg Shcherba from Icons8

备注:综合

计算机视觉交流群
图像分割、姿态估计、智能驾驶、超分辨率、自监督、无监督、2D、3D目标检测等最新资讯,若已为CV君其他账号好友请直接私信。