本文作者:likyh
个人主页:https://github.com/likyh
If your favorite DevOps tool is not yet supported by DevLake, don't worry. It's not difficult to implement a DevLake plugin. In this post, we'll go through the basics of DevLake plugins and build an example plugin from scratch together.
What is a plugin?
A DevLake plugin is a shared library built with Go's plugin package that hooks up to DevLake core at run-time.
A plugin may extend DevLake's capability in three ways:
- Integrating with new data sources
- Transforming/enriching existing data
- Exporting DevLake data to other data systems
How do plugins work?
A plugin mainly consists of a collection of subtasks that can be executed by DevLake core. For data source plugins, a subtask may be collecting a single entity from the data source (e.g., issues from Jira). Besides the subtasks, there're hooks that a plugin can implement to customize its initialization, migration, and more. See below for a list of the most important interfaces:
PluginMeta contains the minimal interface that a plugin should implement, with only two functions
- Description() returns the description of a plugin
- RootPkgPath() returns the root package path of a plugin
- PluginInit allows a plugin to customize its initialization
- PluginTask enables a plugin to prepare data prior to subtask execution
- PluginApi lets a plugin exposes some self-defined APIs
- Migratable is where a plugin manages its database migrations
The diagram below shows the control flow of executing a plugin:
flowchart TD
subgraph S4[Step4 sub-task extractor running process]
direction LR
D4[DevLake]
D4 -- Step4.1 create a new\n ApiExtractor\n and execute it --> E["ExtractXXXMeta.\nEntryPoint"];
E <-- Step4.2 read from\n raw table --> RawDataSubTaskArgs.\nTable;
E -- "Step4.3 call with RawData" --> ApiExtractor.Extract
ApiExtractor.Extract -- "decode and return gorm models" --> E
end
subgraph S3[Step3 sub-task collector running process]
direction LR
D3[DevLake]
D3 -- Step3.1 create a new\n ApiCollector\n and execute it --> C["CollectXXXMeta.\nEntryPoint"];
C <-- Step3.2 create\n raw table --> RawDataSubTaskArgs.\nRAW_BBB_TABLE;
C <-- Step3.3 build query\n before sending requests --> ApiCollectorArgs.\nQuery/UrlTemplate;
C <-. Step3.4 send requests by ApiClient \n and return HTTP response.-> A1["HTTP APIs"];
C <-- "Step3.5 call and \nreturn decoded data \nfrom HTTP response" --> ResponseParser;
end
subgraph S2[Step2 DevLake register custom plugin]
direction LR
D2[DevLake]
D2 <-- "Step2.1 function `Init` \nneed to do init jobs" --> plugin.Init;
D2 <-- "Step2.2 (Optional) call \nand return migration scripts" --> plugin.MigrationScripts;
D2 <-- "Step2.3 (Optional) call \nand return taskCtx" --> plugin.PrepareTaskData;
D2 <-- "Step2.4 call and \nreturn subTasks for execting" --> plugin.SubTaskContext;
end
subgraph S1[Step1 Run DevLake]
direction LR
main -- Transfer of control \nby `runner.DirectRun` --> D1[DevLake];
end
S1-->S2-->S3-->S4There's a lot of information in the diagram but we don't expect you to digest it right away, simply use it as a reference when you go through the example below.
A step-by-step guide towards your first plugin
In this guide, we'll walk through how to create a data source plugin from scratch. The example in this tutorial comes from DevLake's own needs of managing CLAs. Whenever DevLake receives a new PR on GitHub, we need to check if the author has signed a CLA by referencing https://people.apache.org/public/icla-info.json. This guide will demonstrate how to collect the ICLA info from Apache API, cache the raw response, and extract the raw data into a relational table ready to be queried.
Step 1: Bootstrap the new plugin
Note: Please make sure you have DevLake up and running before proceeding.
More info about plugin:
Generally, we need these folders in plugin folders:api,modelsandtasks
apiinteracts withconfig-uifor test/get/save connection of data source
connection [example]()
connection model [example]()
modelsstores alldata entitiesanddata migration scripts.entity [example]()
[data migrations]()taskscontains all of oursub tasksfor a plugin
task data [example]()
api client [example]()
Don't worry about seeing so many concepts at once. we'll explain them one by one. DevLake provides a generator to create a plugin conveniently. Let's scaffold our new plugin by running go run generator/main.go create-plugin icla, which would ask for with_api_client and Endpoint.
with_api_clientis used for choosing if we need to request HTTP APIs by api_client.Endpointuse in which site we will request, in our case, it should behttps://people.apache.org/.

Now we have three files in our plugin. api_client.go and task_data.go are in tasks/.
Have a try to run this plugin by function main in plugin_main.go, and the result maybe look as follows:
$go run plugins/icla/plugin_main.go
[2022-06-02 18:07:30] INFO failed to create dir logs: mkdir logs: file exists
press `c` to send cancel signal
[2022-06-02 18:07:30] INFO [icla] start plugin
invalid ICLA_TOKEN, but ignore this error now
[2022-06-02 18:07:30] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
[2022-06-02 18:07:30] INFO [icla] total step: 0How exciting. It works! The plugin defined and initiated in plugin_main.go use some options in task_data.go. They are made up as the most straightforward plugin in Apache DevLake, and api_client.go will be used in the next step to request HTTP APIs.
Step 2: Create a sub-task for data collection
Before we start, there is a small thing we need to know.
This is how the collection task will be executed:
- First, Apache DevLake would call
plugin_main.PrepareTaskData()to prepare needed data before any sub-tasks. We need to create an API client here. - Then Apache DevLake will call the sub-tasks returned by
plugin_main.SubTaskMetas(). Sub-task is an independent task to do some job, like requesting API, processing data, etc.
Each sub-task must be defined as a [SubTaskMeta](), and implement [SubTaskEntryPoint]() of SubTaskMeta. SubTaskEntryPoint is defined as
type SubTaskEntryPoint func(c SubTaskContext) errorMore info at: https://devlake.apache.org/bl...
Step 2.1 Create a sub-task(Collector) for data collection
Let's run go run generator/main.go create-collector icla committer and confirm it. This sub-task activated by registering in plugin_main.go/SubTaskMetas auto.

- Collector will collect data from HTTP or other data sources and save them into the raw layer.
- Inside the func
SubTaskEntryPointofCollector, we usehelper.NewApiCollectorto create an object of [ApiCollector](), then callexecute()to do the job. Please refer to the [example]()
Now Notice data.ApiClient inited in plugin_main.go/PrepareTaskData.ApiClient. PrepareTaskData create a new ApiClient, and it's a tool Apache DevLake suggests to request data from HTTP Apis. This tool support some valuable feathers for HttpApi, like rateLimit, proxy and retry. We can use the lib http instead, but it will be more tedious.
Let's do some things to use it.
- To collect data from
https://people.apache.org/public/icla-info.json,
we have filledhttps://people.apache.org/intotasks/api_client.go/ENDPOINTin Step 1.

- And fill
public/icla-info.jsonintoUrlTemplate, delete unnecessary iterator and addprintln("receive data:", res)inResponseParserto see if collection was successful.

Ok, now the collector sub-task has been added to the plugin, and we can kick it off by running main again. then the output of Davlake may look like this:
[2022-06-06 12:24:52] INFO [icla] start plugin
invalid ICLA_TOKEN, but ignore this error now
[2022-06-06 12:24:52] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
[2022-06-06 12:24:52] INFO [icla] total step: 1
[2022-06-06 12:24:52] INFO [icla] executing subtask CollectCommitter
[2022-06-06 12:24:52] INFO [icla] [CollectCommitter] start api collection
receive data: 0x140005763f0
[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] finished records: 1
[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] end api collection
[2022-06-06 12:24:55] INFO [icla] finished step: 1 / 1Great! Now we can see data pulled from the server without problem. The last step is to decode the response body in ResponseParser and return it to the framework so it can be saved in the database.
ResponseParser: func(res *http.Response) ([]json.RawMessage, error) {
body := &struct {
LastUpdated string `json:"last_updated"`
Committers json.RawMessage `json:"committers"`
}{}
err := helper.UnmarshalResponse(res, body)
if err != nil {
return nil, err
}
println("receive data:", len(body.Committers))
return []json.RawMessage{body.Committers}, nil
},
Ok, run the function main once again, then it turned out like this, and we should see some records show up in the table _raw_icla_committer.
……
receive data: 272956 /* <- the number means 272956 models received */
[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] finished records: 1
[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] end api collection
[2022-06-06 13:46:57] INFO [icla] finished step: 1 / 1
Step 2.2 Create a sub-task(Extractor) to extract data from the raw layer
- Extractor will extract data from raw layer and save it into tool db table.
- Except for some pre-processing, the main flow is similar to the collector. Please refer to the [example]()
We have already collected data from HTTP API and saved them into the DB table _raw_XXXX. This section will extract the names of committers from raw data. You know, raw tables are temporary and not easy to use.
Now Apache DevLake suggests to save data by gorm, so we will create a model by grom and add it into plugin_main.go/AutoSchemas.Up().
plugins/icla/models/committer.go
package models
import (
"github.com/apache/incubator-devlake/models/common"
)
type IclaCommitter struct {
UserName string `gorm:"primaryKey;type:varchar(255)"`
Name string `gorm:"primaryKey;type:varchar(255)"`
common.NoPKModel
}
func (IclaCommitter) TableName() string {
return "_tool_icla_committer"
}plugins/icla/plugin_main.go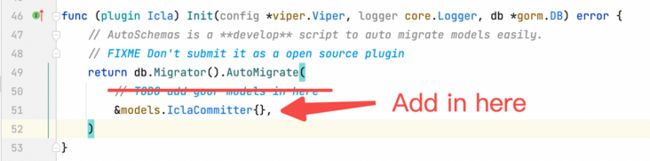
Ok, run the plugin and table _tool_icla_committer will be created automatically as this snapshot:
Next, let's run go run generator/main.go create-extractor icla committer and input the UI needed.

Let's look at the function extract in committer_extractor.go created just now, and some codes need to be written here. It's obviously resData.data is raw data, so we could decode them by json and add new IclaCommitter to save them.
Extract: func(resData *helper.RawData) ([]interface{}, error) {
names := &map[string]string{}
err := json.Unmarshal(resData.Data, names)
if err != nil {
return nil, err
}
extractedModels := make([]interface{}, 0)
for userName, name := range *names {
extractedModels = append(extractedModels, &models.IclaCommitter{
UserName: userName,
Name: name,
})
}
return extractedModels, nil
},Ok, run it then we will get:
[2022-06-06 15:39:40] INFO [icla] start plugin
invalid ICLA_TOKEN, but ignore this error now
[2022-06-06 15:39:40] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
[2022-06-06 15:39:40] INFO [icla] total step: 2
[2022-06-06 15:39:40] INFO [icla] executing subtask CollectCommitter
[2022-06-06 15:39:40] INFO [icla] [CollectCommitter] start api collection
receive data: 272956
[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] finished records: 1
[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] end api collection
[2022-06-06 15:39:44] INFO [icla] finished step: 1 / 2
[2022-06-06 15:39:44] INFO [icla] executing subtask ExtractCommitter
[2022-06-06 15:39:46] INFO [icla] [ExtractCommitter] finished records: 1
[2022-06-06 15:39:46] INFO [icla] finished step: 2 / 2Now committer data have been saved in _tool_icla_committer.
Step 2.3 Convertor
Notes: There are two ways here (open source or using it yourself). It is unnecessary, but we encourage it because convertors and the domain layer will significantly help build dashboards. More info about the domain layer at: https://devlake.apache.org/do...
- Convertor will convert data from the tool layer and save it into the domain layer.
- We use
helper.NewDataConverterto create an object of [DataConvertor](), then callexecute(). Please refer to the [example]()
Step 2.4 Let's try it
Sometimes OpenApi will be protected by token or other auth types, and we need to log in to gain a token to visit it. For example, We can only gather the data if contributors have signed icla after login [email protected]. But now we just describe how to do this briefly.
Let's look at api_client.go. NewIclaApiClient load config ICLA_TOKEN by .env, so we can add ICLA_TOKEN=XXXXXX in .env and use it in apiClient.SetHeaders() to mock the login status. Code as below:
Of course, we can use username/password to get a token after login mockery. Just try and adjust according to the actual situation.
Look for more related details at https://github.com/apache/inc...
Final step: Submit the code as opensource code
Good ideas~ But it might be a little challenging to write normative codes for those who lack the knowledge of migration scripts and domain layers. More info at https://......... or contact us for ebullient help.
Done!
Congratulations! The first plugin has been created!
了解更多最新动态
官网:https://devlake.incubator.apache.org/
GitHub:https://github.com/apache/incubator-devlake/
Slack:通过 Slack 联系我们