Opencv实战——OCR文档扫描
文章目录
- 前言
- 一、安装Tesseract-OCR
- 二、文档扫描
-
- 1.需要透视变换的图像
- 2.直接Tesseract-OCR
- 总结
前言
这里实现文档扫描主要是依靠Tesseract,Tesseract是一个光学字符识别引擎。支持多种操作系统,基于Apache许可证的自由软件,由Google赞助开发。 Tesseract被认为是最精准的开源光学字符识别引擎之一。是一个光学字符识别引擎。支持多种操作系统,基于Apache许可证的自由软件,由Google赞助开发。 Tesseract被认为是最精准的开源光学字符识别引擎之一。
一、安装Tesseract-OCR
首先下载Tesseract安装包
链接:https://pan.baidu.com/s/1NGnl_ZOpUQ2403G9PPTjyg
提取码:2333
因为要识别中文,所以要勾选支持中文的语言包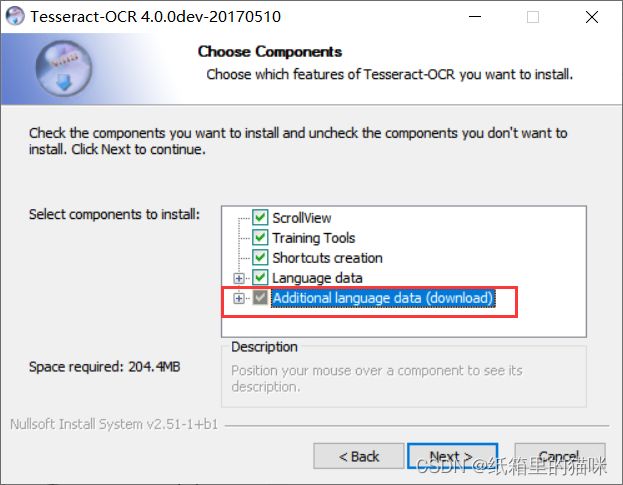

chi_sim包含了简化汉字和英文字符,需要用到中文繁体的可以勾选Chinese(Traditional)
为了避免使用Tesseract-OCR报错,安装完成后需要将安装路径添加到环境变量中
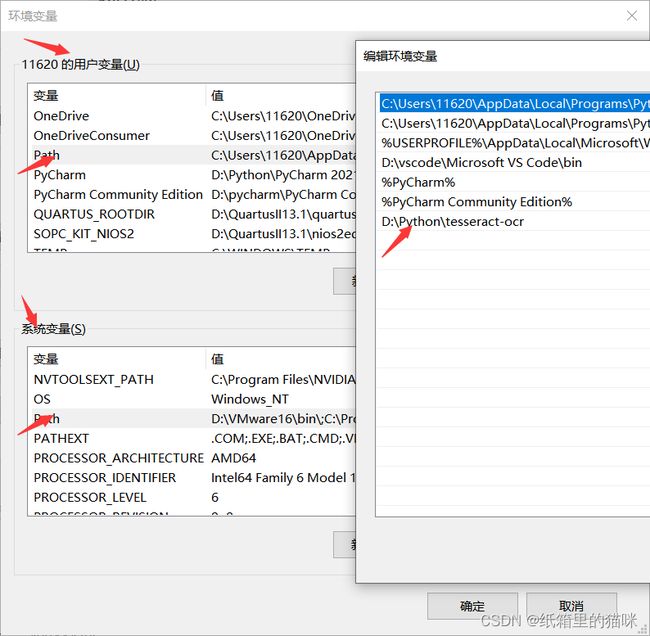
Tesseract-OCR安装完成后还需要安装pytesseract包,直接pip就行
pip install pytesseract
安装完成后需要将tesseract_cmd的路径改为绝对路径,也就是安装Tesseract-OCR的路径
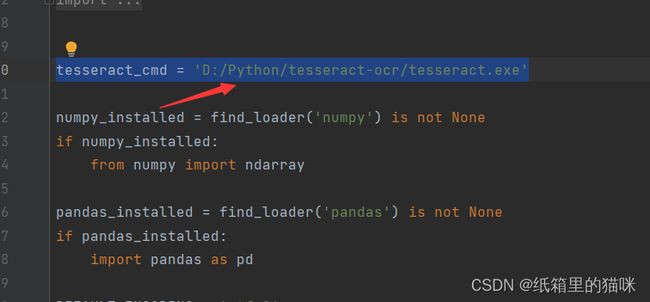
这样Tesseract-OCR的环境配置就完成了
二、文档扫描
经过我摸爬滚打踩坑过来发现,可以将扫描归为两大类,一类是图像中文档的文字位置不是水平(也就是倾斜,或者什么乱七八糟的),这一类在使用Tesseract-OCR之前需要进行图像预处理(比如透视变换);另外一类就是图像文字水平,这类图像直接使用Tesseract-OCR的效果要比图像预处理后再使用Tesseract-OCR要好。最后将识别到的内容保存到文档中。
1.需要透视变换的图像
透视变换就是将看起来歪歪扭扭的图像转换成规规矩矩的图像。类似这种图像的需要经过图像预处理后在使用Tesseract-OCR。

首先读入图像,因为图像太大了需要resize一下在处理,将图像转为灰度图,然后检测小票的轮廓,cv2.CHAIN_APPROX_SIMPLE是只保留轮廓的四个点,这样我们就得到了小票4个顶点的轮廓,在经过four_point_transform透视变换后就的到了适合Tesseract-OCR的图像。
透视变换(Perspective Transformation)的本质是将图像投影到一个新的视平面,其通用变换公式为:
(u,v)为原始图像像素坐标,(x=x’/w’,y=y’/w’)为变换之后的图像像素坐标。透视变换矩阵图解如下:
代码
#导入工具包
import cv2
import argparse
import func
import pytesseract
#设置参数
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True,
help = "Path to the image to be scanned")
args = vars(ap.parse_args())
#读取图像
image = cv2.imread(args["image"])
#复制图像
orig = image.copy()
#修改图像大小
image = cv2.resize(image,(0,0),fx=0.2,fy=0.2)
#图像预处理
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)#灰度图
gray = cv2.GaussianBlur(gray,(5,5),0)#高斯滤波
edg =cv2.Canny(gray,100,255)#边缘检测
#展示处理结果
print("SETP 1:边缘检测")
func.cv_show("edg", edg)
#轮廓检测
cnt,hierarchy =cv2.findContours(edg,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)#只保留顶点
cnts =sorted(cnt,key = cv2.contourArea,reverse = True)[:5]#轮廓由大到小排序,只保留五个
#遍历轮廓
for c in cnts:
#计算轮廓近似
peri = cv2.arcLength(c,True)
# C表示输入的点集
# epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
# True表示封闭的
approx = cv2.approxPolyDP(c, 0.02 * peri, True)#轮廓近似
# 4个点的时候就拿出来
if len(approx) == 4:
screenCnt = approx
break
#展示结果
print("SETP 2:获取轮廓")
cv2.drawContours(image,[screenCnt],-1,(0,0,255),2)
func.cv_show("ima",image)
# 透视变换
warped = func.four_point_transform(orig, screenCnt.reshape(4, 2)*5)
# 二值处理
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1]
print("STEP 3: 透视变换")
ref = cv2.resize(ref,(0,0),fx=0.2,fy=0.2)
cv2.imwrite('scan.jpg', ref)
func.cv_show("ref",ref)
print("STEP 4: OCR文档识别")
text = pytesseract.image_to_string(gray,'chi_sim')
print(text)
#将文档保存
file_handle=open('test.docx',mode='w',encoding='utf-8')
file_handle.write(text)
效果:
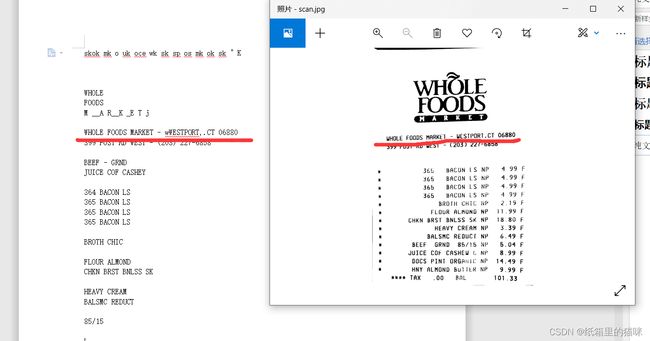
可以看出基本识别还是可以识别出来的,效果就有点差强人意了。
2.直接Tesseract-OCR
类似这样的图像就可以直接使用Tesseract-OCR,因为我们之前安装了中文包,所以可以识别到中文。
代码:
#导入工具包
import cv2
import argparse
import func
import pytesseract
#设置参数
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True,
help = "Path to the image to be scanned")
args = vars(ap.parse_args())
#读取图像
image = cv2.imread(args["image"])
#复制图像
orig = image.copy()
#修改图像大小
image = cv2.resize(image,(0,0),fx=0.5,fy=0.5)
text = pytesseract.image_to_string(orig,'chi_sim')
print(text)
#将文档保存
file_handle=open('test.docx',mode='w',encoding='utf-8')
file_handle.write(text)
效果:
这个识别效果也是半斤八两,后续可以自己训练一个中文包,可以会有更好的效果。
总结
完整代码放到gitee上面了总的来说Tesseract还是很好用的,识别效果差很大原因是图像本来效果就差,用清晰的图片识别效果会更好。