【AI周报】2021图灵奖揭晓;字节开源veGiantModel;阿里开源EPL;谷歌AI框架Pathways论文放出
01 行业大事件
2021图灵奖揭晓:
高性能计算先驱、超算TOP500榜单创始人之一Jack Dongarra获奖
他曾说过:未来的计算架构会是 CPU 和 GPU 的结合。
守了一天,终于揭晓!

刚刚,2021 图灵奖公布。ACM 官方宣布 2021 年的图灵奖授予美国田纳西大学电气工程和计算机科学杰出教授,现年 71 岁的 Jack Dongarra,以表彰他对数值算法和工具库的开创性贡献,其使得高性能计算软件能够跟上四十多年来的指数级硬件改进。

Dongarra 的算法和软件推动了高性能计算(HPC)的发展,并在从人工智能到计算机图形学的许多计算科学领域产生了重大影响。由于他的软件被用做超级计算机性能测评标准,并且由此诞生了超级计算机 TOP500 排行榜。
谷歌下一代AI架构、Jeff Dean宣传大半年的Pathways终于有论文了
「当前的 AI 模型只做一件事。Pathways 使我们能够训练一个模型,做成千上万件事情。」
在谈及当前的 AI 系统所面临的问题时,低效是经常被提及的一个。
谷歌人工智能主管 Jeff Dean 曾在一篇博文中写道,「今天的人工智能系统总是从头开始学习新问题 —— 数学模型的参数从随机数开始。就像每次学习一项新技能(例如跳绳),你总会忘记之前所学的一切,包括如何平衡、如何跳跃、如何协调手的运动等,然后从无到有重新学习。这或多或少是我们今天训练大多数机器学习模型的方式:我们不是扩展现有模型来学习新任务,而是从无到有训练新模型来做一件事(或者我们有时将通用模型专门用于特定任务)。结果是我们最终为数千个单独的任务开发了数千个模型。以这种方式学习每项新任务不仅需要更长的时间,而且还需要更多的数据。」
为了改变这种局面,Jeff Dean 等人去年提出了一种名叫「Pathways」的通用 AI 架构。他介绍说,Pathways 旨在用一个架构同时处理多项任务,并且拥有快速学习新任务、更好地理解世界的能力。

该架构的特点可以概括为:
-
能够训练一个模型来做成千上万件事情;
-
当前模型只注重一种感官,Pathways 可做到多种;
-
当前模型密集且效率低下,Pathways 会把模型变得稀疏而高效。
-
在发布想法大半年之后,Jeff Dean 终于公布了 Pathways 的论文,其中包含很多技术细节。

论文链接 https://arxiv.org/pdf/2203.12533.pdf
论文写道,PATHWAYS 使用了异步算子的一个分片数据流图(sharded dataflow graph),这些算子消耗并产生 futures,并在数千个加速器上高效地对异构并行计算进行 gang-schedule,同时在它们专用的 interconnect 上协调数据传输。PATHWAYS 使用了一种新的异步分布式数据流设计,它允许控制平面并行执行,尽管数据平面中存在依赖关系。这种设计允许 PATHWAYS 采用单控制器模型,从而更容易表达复杂的新并行模式。
实验结果表明,当在 2048 个 TPU 上运行 SPMD(single program multiple data)计算时,PATHWAYS 的性能(加速器利用率接近 100%)可以媲美 SOTA 系统,同时吞吐量可媲美跨越 16 个 stage 或者被分割成两个通过数据中心网络连接的加速器岛的 Transformer 模型的 SPMD 案例。
性能最高提升 6.9 倍,字节跳动开源大模型训练框架 veGiantModel
背景
近些年,NLP 应用方面有所突破,Bert、GPT、GPT-3 等超大模型横扫各种 NLP 测试后,人们发现参数量越大的模型,在算法方面表现越好,于是纷纷开始迅速向大模型方向发展,模型体积爆炸式增长。而大模型训练给现有的训练系统带来的主要挑战为显存压力,计算压力和通信压力。
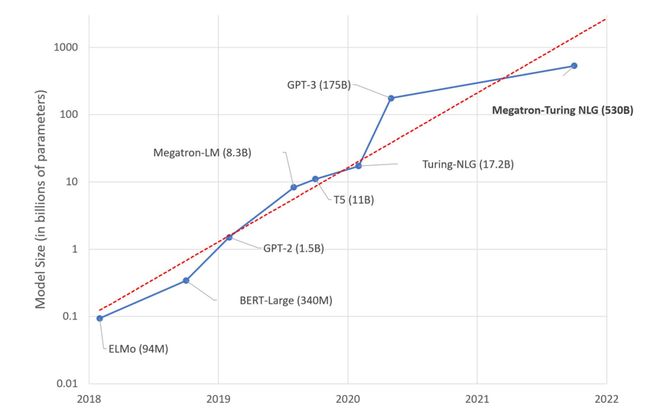
The size of language model is growing at an exponential rate
来源:https://huggingface.co/blog/large-language-models
火山引擎大模型训练框架 veGiantModel
针对这个需求,字节跳动 AML 团队内部开发了火山引擎大模型训练框架 veGiantModel。基于 PyTorch 框架,veGiantModel 是以 Megatron 和 DeepSpeed 为基础的高性能大模型训练框架。其特点包括:
-
同时支持数据并行、算子切分、流水线并行 3 种分布式并行策略,同时支持自动化和定制化的并行策略;
-
基于 ByteCCL 高性能异步通讯库,训练任务吞吐相比其他开源框架有 1.2x-3.5x 的提升;
-
提供了更友好、灵活的流水线支持,降低了模型开发迭代所需要的人力;
-
可在 GPU上高效地支持数十亿至上千亿参数量的大模型;
-
对带宽要求低,在私有化部署无 RDMA 强依赖。
其中,ByteCCL 为字节跳动自研的 BytePS 的升级版,针对 A100/V100 等各种机型拓扑做了分层规约优化,并支持了 allgather、alltoall 等更全面的通讯原语。
veGiantModel 性能表现
硬件配置
为了展示 VeGiantModel 的性能,veGiantModel 团队使用了自建机房的物理机,分别在 A100 和 V100 机型上做了测试,实验配置分别如下:
-
V100 测试:每个机器 8 张 Tesla V100 32G 型号 GPU,网络带宽 100G
-
A100 测试:每个机器 8 张 Ampere A100 40G 型号 GPU,网络带宽 800G
模型和对照组选择veGiantModel 选择了 GPT-13B 模型进行评估,seq length 是 256, global batch size 是 1536。GPT 为目前市面上最为流行的 transformer based 语言模型。性能对照组选择了开源社区最流行的 Megatron 和 DeepSpeed。
测试结果
模型:GPT-13B
-
Megatron:v2.4,tensor-model-parallel-size 设置为 4, pipeline-model-parallel-size 设置为 4
-
DeepSpeed:v0.4.2,使用 DeepSpeedExamples 开源社区中默认的 zero3 的配置
运行环境
-
V100/TCP :100Gb/s TCP 网络带宽,4 机,每机 8 张 Tesla V100 32G GPU
-
V100/RDMA:100Gb/s RDMA 网络带宽,4 机,每机 8 张 Tesla V100 32G GPU
-
A100/TCP:800Gb/s TCP 网络带宽,4 机,每机 8 张 Tesla A100 40G GPU
-
A100/RDMA:800Gb/s RDMA 网络带宽,4 机,每机 8 张 Tesla A100 40G GPU
统计值:Throughtput (samples/s)

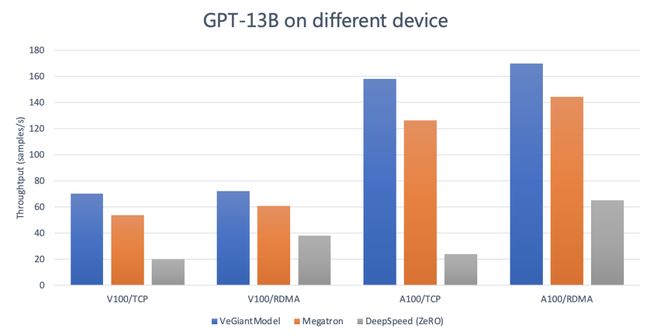
从上述数据可以看出:
veGiantModel 性能更优:无论是在高带宽还是低带宽的场下,veGiantModel 在 V100 和 A100 上均胜出 Megatron 和 DeepSpeed,最高可达 6.9 倍提升。
veGiantModel 对网络带宽要求低:veGiantModel 在带宽变化对吞吐的影响相对最小 (<10%),而 DeepSpeed(ZeRO) 是对带宽要求最高的,最高可达将近 5 倍的差距。
阿里开源 支持10万亿模型的自研分布式训练框架EPL(Easy Parallel Library)
最近阿里云机器学习PAI平台和达摩院智能计算实验室一起发布“低碳版”巨模型M6-10T,模型参数已经从万亿跃迁到10万亿,规模远超业界此前发布的万亿级模型,成为当前全球最大的AI预训练模型。
EPL是什么
EPL(Easy Parallel Library)是阿里最近开源的,统一多种并行策略的、灵活易用的自研分布式深度学习训练框架。
项目背景
随着近些年深度学习的火爆,模型的参数规模也增长迅速,OpenAI数据显示:
2012年以前,模型计算耗时每2年增长一倍,和摩尔定律保持一致;
2012年后,模型计算耗时每3.4个月翻一倍,远超硬件发展速度;
特别最近一年模型参数规模飞速增长,谷歌、英伟达、阿里、智源研究院都发布了万亿参数模型,有大厂也发布了百亿、千亿参数模型。随着模型参数规模增大,模型效果也在逐步提高,但同时也为训练框架带来更大的挑战。当前已经有一些分布式训练框架,例如:Horovod、Tensorflow Estimator、PyTorch DDP等支持数据并行,Gpipe、PipeDream、PipeMare等支持流水并行,Mesh Tensorflow、FlexFlow、OneFlow、MindSpore等支持算子拆分,但当我们要训练一个超大规模的模型时会面临一些挑战:
如何简洁易用:
-
接入门槛高:用户实现模型分布式版本难度大、成本高,需要有领域专家经验才能实现高效的分布式并行策略;
-
最优策略难:随着研究人员设计出越来越灵活的模型,以及越来越多的并行加速方法,如果没有自动并行策略探索支持,用户很难找到最适合自身的并行策略;
-
迁移代价大:不同模型适合不同的混合并行策略,但切换并行策略时可能需要切换不同的框架,迁移成本高;
主要特性
-
多种并行策略统一:在一套分布式训练框架中支持多种并行策略(数据/流水/算子/专家并行)和其各种组合、嵌套使用;
-
接口灵活易用:用户只需添加几行代码就可以使用EPL丰富的分布式并行策略,模型代码无需修改;
-
自动并行策略探索:算子拆分时自动探索拆分策略,流水并行时自动探索模型切分策略;
-
分布式性能更优:提供了多维度的显存优化、计算优化,同时结合模型结构和网络拓扑进行调度和通信优化,提供高效的分布式训练;
开源地址
EPL(Easy Parallel Library)的开源地址是:
https://github.com/alibaba/EasyParallelLibrary
同时提供了model zoo:
https://github.com/alibaba/FastNN
02 程序员专区
近期优质论文分享
1.只用ViT做主干也可以做好目标检测
论文题目:
Exploring Plain Vision Transformer Backbones for Object Detection
论文地址:
https://arxiv.org/pdf/2203.16527.pdf
论文摘要:
当前的目标检测器通常由一个与检测任务无关的主干特征提取器和一组包含检测专用先验知识的颈部和头部组成。颈部 / 头部中的常见组件可能包括感兴趣区域(RoI)操作、区域候选网络(RPN)或锚、特征金字塔网络(FPN)等。如果用于特定任务的颈部 / 头部的设计与主干的设计解耦,它们可以并行发展。从经验上看,目标检测研究受益于对通用主干和检测专用模块的大量独立探索。长期以来,由于卷积网络的实际设计,这些主干一直是多尺度、分层的架构,这严重影响了用于多尺度(如 FPN)目标检测的颈 / 头的设计。
在这项工作中,何恺明等研究者追求的是一个不同的方向:探索仅使用普通、非分层主干的目标检测器。如果这一方向取得成功,仅使用原始 ViT 主干进行目标检测将成为可能。在这一方向上,预训练设计将与微调需求解耦,上游与下游任务的独立性将保持,就像基于 ConvNet 的研究一样。这一方向也在一定程度上遵循了 ViT 的理念,即在追求通用特征的过程中减少归纳偏置。由于非局部自注意力计算可以学习平移等变特征,它们也可以从某种形式的监督或自我监督预训练中学习尺度等变特征。
研究者表示,在这项研究中,他们的目标不是开发新的组件,而是通过最小的调整克服上述挑战。具体来说,他们的检测器仅从一个普通 ViT 主干的最后一个特征图构建一个简单的特征金字塔(如图 1 所示)。这一方案放弃了 FPN 设计和分层主干的要求。为了有效地从高分辨率图像中提取特征,他们的检测器使用简单的非重叠窗口注意力(没有 shifting)。他们使用少量的跨窗口块来传播信息,这些块可以是全局注意力或卷积。这些调整只在微调过程中进行,不会改变预训练。
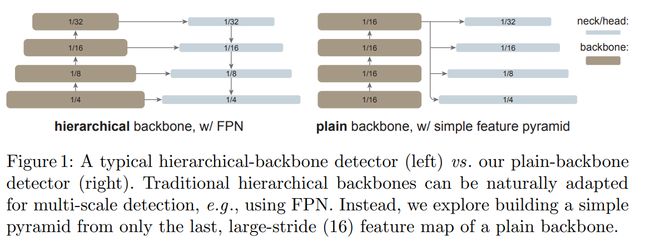
这种简单的设计收获了令人惊讶的结果。研究者发现,在使用普通 ViT 主干的情况下,FPN 的设计并不是必要的,它的好处可以通过由大步幅 (16)、单一尺度图构建的简单金字塔来有效地获得。他们还发现,只要信息能在少量的层中很好地跨窗口传播,窗口注意力就够用了。
更令人惊讶的是,在某些情况下,研究者开发的名为「ViTDet」的普通主干检测器可以媲美领先的分层主干检测器(如 Swin、MViT)。通过掩蔽自编码器(MAE)预训练,他们的普通主干检测器可以优于在 ImageNet-1K/21K 上进行有监督预训练的分层检测器(如下图所示)。

在较大尺寸的模型上,这种增益要更加显著。该检测器的优秀性能是在不同的目标检测器框架下观察到的,包括 Mask R-CNN、Cascade Mask R-CNN 以及它们的增强版本。
在 COCO 数据集上的实验结果表明,一个使用无标签 ImageNet-1K 预训练、带有普通 ViT-Huge 主干的 ViTDet 检测器的 AP^box 可以达到 61.3。他们还在长尾 LVIS 检测数据集上展示了 ViTDet 颇具竞争力的结果。虽然这些强有力的结果可能部分来自 MAE 预训练的有效性,但这项研究表明,普通主干检测器可能是有前途的,这挑战了分层主干在目标检测中的根深蒂固的地位。

极链AI云是极链科技集团下属专为AI科研与学习而设计的一站式开发平台。为开发者提供全流程的AI科研服务,让每一位用户都能拥有撬动AI变革的力量