使用IntelliJ Idea开发Spark Streaming流应用程序
使用IntelliJ Idea开发Spark Streaming流应用程序
- 一、实验目的
- 二、实验内容
- 三、实验原理
- 四、实验环境
- 五、实验步骤
-
- 5.1 启动IntelliJ Idea并创建spark项目
- 5.2 编写spark代码
- 5.3 打包程序
- 5.4 集群运行jar包
未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计2178字,阅读大概需要3分钟
一、实验目的
掌握IntelliJ Idea创建Spark Streaming流应用程序的过程。
熟悉在spark上提交运行Spark Streaming作业的方式。
二、实验内容
1、使用IntelliJ Idea创建Spark Streaming流应用程序。
2、打包Spark Streaming流应用程序并提交执行。
三、实验原理
Spark Streaming内部的基本工作原理如下:接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的

四、实验环境
硬件:x86_64 ubuntu 16.04服务器
软件:JDK1.8,Scala-2.11.8,Spark-2.3.2,Hadoop-2.7.3,IntelliJ Idea
五、实验步骤
5.1 启动IntelliJ Idea并创建spark项目
1、启动IntelliJ Idea。在终端窗口下,执行以下命令:
1. $ cd /opt/idea-IC-191.7479.19/bin
2. $ ./idea.sh
2、在idea中创建scala项目,并命名为”sparkstreaming”,其它都默认即可,然后点击”Finish”按钮。如下图所示:

3、点击【File】菜单,选择【Project structure】选项,进入项目结构界面。如下图所示:

4、按图中所示依次选择,导入spark的jar包到项目中。如下图所示:
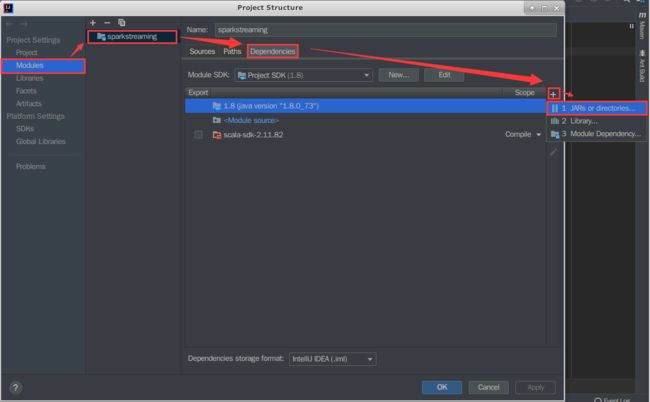
5、jar包所在目录为”/opt/spark/jars/“,之后一直点击【OK】按钮即可导包成功。如下图所示:

6、查看成功导入的部分jar包。如下图所示:
5.2 编写spark代码
1、选中spark_project1项目的src目录右键依次选择【New】-【Scala Class】,创建WordCount类。如下图所示:

2、与上述方法一样,在弹出的对话框中命名为”WordCount”,并选择”Object”类型。如下图所示:

图片10
3、编写流程序代码,读取指定端口中的数据,对来自端口的数据进行单词统计。代码如下所示:
1. import org.apache.spark.SparkConf
2. import org.apache.spark.streaming.Seconds
3. import org.apache.spark.streaming.StreamingContext
4.
5. object WordCount {
6.
7. def main(args: Array[String]): Unit = {
8. val conf = new SparkConf()
9. .setMaster("local[*]")
10. .setAppName("WordCount")
11.
12. val ssc = new StreamingContext(conf, Seconds(20))
13.
14. val lines = ssc.socketTextStream("localhost", 9999)
15. val words = lines.flatMap { _.split(" ") }
16. val pairs = words.map { word => (word, 1) }
17. val wordCounts = pairs.reduceByKey(_ + _)
18.
19. wordCounts.print()
20.
21. ssc.start()
22. ssc.awaitTermination()
23. }
24.
25. }
5.3 打包程序
1、点击【File】菜单,选择【Project structure】选项,进入项目结构界面。如下图所示:
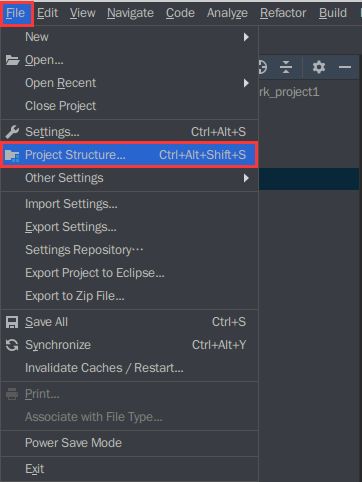
2、按图中选择依次点击进行打包。如下图所示:

3、弹出对话框,Main Class框中选择 WordCount,其它保持默认即可,点击【OK】。如下图所示:
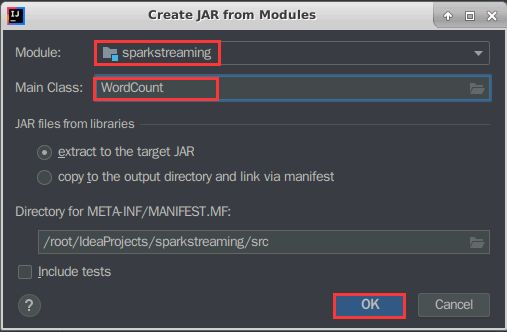
4、返回到项目结构界面,把项目依赖的所有jar包都删除,只导出类文件,点击【OK】按钮。如下图所示:

5、点击【Build】菜单下的Build Artifacts选项进行编译。如下图所示:

6、按图中所示选择即开始编译。如下图所示:

5.4 集群运行jar包
1、启动Spark集群。在终端窗口下,执行以下命令:
1. $ cd /opt/spark
2. $ ./sbin/start-all.sh
2、启动nc服务器。在终端窗口下,执行以下命令:
1. $ nc -lp 9999
3、另打开一个终端窗口,执行如下命令,提交jar包到spark中运行程序:
1. $ spark-submit --class WordCount /root/IdeaProjects/sparkstreaming/out/artifacts/sparkstreaming_jar/sparkstreaming.jar
执行过程如下图所示:

4、切换到nc服务器所在终端窗口,输入以下内容:
1. hello sparkstreaming
2. hello scala
5、切换到Spark流程序提交窗口。在终端中可以看出单词统计的输出结果。如下图所示:

— END —