Selenium+Pytest自动化测试框架实战-入门到精通
前言#
selenium自动化+ pytest测试框架
本章你需要
-
一定的python基础——至少明白类与对象,封装继承
-
一定的selenium基础——本篇不讲selenium,不会的可以自己去看selenium中文翻译网
测试框架简介#
Page Object模式图
正在上传…重新上传取消
通过上图我们可以看出,通过POM模型思想,我们把:
以上四种代码主体进行了拆分,虽然在用例很少的情况下做会增加代码,但是当用例多的时候意义很大,代码量会在用例增加的时候显著减少。我们维护代码变得更加直观明显,代码可读性也变得比工厂模式强很多,代码复用率也极大的得到了提高。
简单学习元素定位#
在日常的工作中,我见过很多在浏览器中直接在浏览器中右键Copy Xpath复制元素的同学。这样获得的元素表达式放在 webdriver 中去运行往往是不够稳定的,像前端的一些微小改动,都会引起元素无法定位的NoSuchElementException报错。
所以在实际工作和学习中我们应该加强自己的元素定位能力,尽可能的采用xpath和CSS selector 这种相对稳定的定位语法。由于CSS selector的语法生硬难懂,对新手很不友好,而且相比xpath缺少一些定位语法。所以我们选择xpath进行我们的元素定位语法。
xpath#
语法规则
菜鸟教程中对于 xpath 的介绍是一门在 XML 文档中查找信息的语言。
-
测试框架有什么优点呢:
- 代码复用率高,如果不使用框架的话,代码会很冗余
- 可以组装日志、报告、邮件等一些高级功能
- 提高元素等数据的可维护性,元素发生变化时,只需要更新一下配置文件
- 使用更灵活的PageObject设计模式
-
测试框架的整体目录
-

这样一个简单的框架结构就清晰了。
知道了以上这些我们就开始吧!
我们在项目中先按照上面的框架指引,建好每一项目录。
注意:python包为是的,都需要添加一个
__init__.py文件以标识此目录为一个python包。首先管理时间#
首先呢,因为我们很多的模块会用到时间戳,或者日期等等字符串,所以我们先单独把时间封装成一个模块。
然后让其他模块来调用即可。在
utils目录新建times.py模块 -

添加配置文件#
配置文件总是项目中必不可少的部分!
将固定不变的信息集中在固定的文件中
conf.py#
项目中都应该有一个文件对整体的目录进行管理,我也在这个python项目中设置了此文件。
在项目
config目录创建conf.py文件,所有的目录配置信息写在这个文件里面。 -

注意:QQ邮箱授权码:点击查看生成教程
这个conf文件我模仿了Django的settings.py文件的设置风格,但是又有些许差异。
在这个文件中我们可以设置自己的各个目录,也可以查看自己当前的目录。
遵循了约定:不变的常量名全部大写,函数名小写。看起来整体美观。
config.ini#
在项目
config目录新建一个config.ini文件,里面暂时先放入我们的需要测试的URL -

读取配置文件#
配置文件创建好了,接下来我们需要读取这个配置文件以使用里面的信息。
我们在
common目录中新建一个readconfig.py文件 -
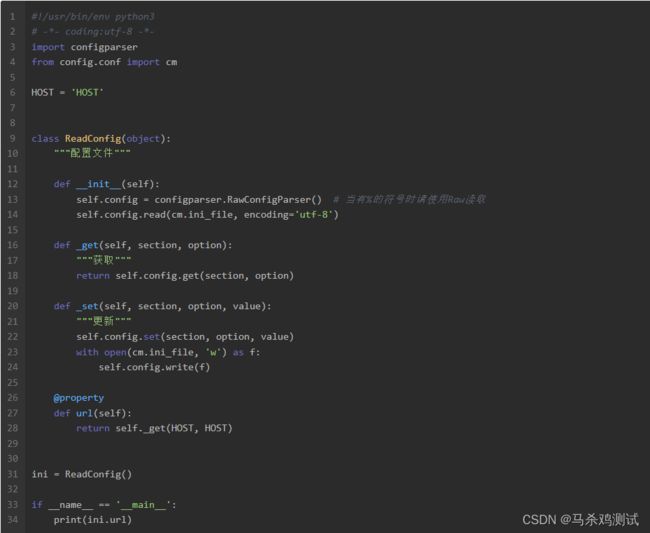
可以看到我们用python内置的configparser模块对
config.ini文件进行了读取。对于url值的提取,我使用了高阶语法
@property属性值,写法更简单。记录操作日志#
日志,大家应该都很熟悉这个名词,就是记录代码中的动作。
在
utils目录中新建logger.py文件。这个文件就是我们用来在自动化测试过程中记录一些操作步骤的。
-

在终端中运行该文件,就看到命令行打印出了:
-

然后在项目logs目录下生成了当月的日志文件。
简单理解POM模型#
由于下面要讲元素相关的,所以首先理解一下POM模型
Page Object模式具有以下几个优点。
该观点来自 《Selenium自动化测试——基于Python语言》
- 抽象出对象可以最大程度地降低开发人员修改页面代码对测试的影响, 所以, 你仅需要对页
面对象进行调整, 而对测试没有影响; - 可以在多个测试用例中复用一部分测试代码;
- 测试代码变得更易读、 灵活、 可维护
-
Page Object模式图
-

- basepage ——selenium的基类,对selenium的方法进行封装
- pageelements——页面元素,把页面元素单独提取出来,放入一个文件中
- searchpage ——页面对象类,把selenium方法和页面元素进行整合
- testcase ——使用pytest对整合的searchpage进行测试用例编写
- selenium方法
- 页面元素
- 页面对象
- 测试用例
-
以上四种代码主体进行了拆分,虽然在用例很少的情况下做会增加代码,但是当用例多的时候意义很大,代码量会在用例增加的时候显著减少。我们维护代码变得更加直观明显,代码可读性也变得比工厂模式强很多,代码复用率也极大的得到了提高。
简单学习元素定位#
在日常的工作中,我见过很多在浏览器中直接在浏览器中右键
Copy Xpath复制元素的同学。这样获得的元素表达式放在 webdriver 中去运行往往是不够稳定的,像前端的一些微小改动,都会引起元素无法定位的NoSuchElementException报错。所以在实际工作和学习中我们应该加强自己的元素定位能力,尽可能的采用
xpath和CSS selector这种相对稳定的定位语法。由于CSS selector的语法生硬难懂,对新手很不友好,而且相比xpath缺少一些定位语法。所以我们选择xpath进行我们的元素定位语法。xpath#
语法规则
菜鸟教程中对于 xpath 的介绍是一门在 XML 文档中查找信息的语言。

定位工具
- chropath
- 优点:这是一个Chrome浏览器的测试定位插件,类似于firepath,本人试用了一下整体感觉非常好。对小白的友好度很好。
- 缺点:安装这个插件需要FQ。
- Katalon录制工具
- 录制出来的脚本里面也会有定位元素的信息
- 自己写——本人推荐这种
- 优点:本人推荐的方式,因为当熟练到一定程度的时候,写出来的会更直观简洁,并且在运行自动化测试中出现问题时,能快速定位。
- 缺点:需要一定
xpath和CSS selector语法积累,不太容易上手。
管理页面元素#
本教程选择的测试地址是百度首页,所以对应的元素也是百度首页的。
项目框架设计中有一个目录page_element就是专门来存放定位元素的文件的。
通过对各种配置文件的对比,我在这里选择的是YAML文件格式。其易读,交互性好。
我们在page_element中新建一个search.yaml文件。

元素定位文件创建好了,下来我们需要读取这个文件。
在common目录中创建readelement.py文件。

通过特殊方法__getitem__实现调用任意属性,读取yaml中的值。
这样我们就实现了定位元素的存储和调用。
但是还有一个问题,我们怎么样才能确保我们写的每一项元素不出错,人为的错误是不可避免的,但是我们可以通过代码来运行对文件的审查。当前也不能所有问题都能发现。
所以我们编写一个文件,在script脚本文件目录中创建inspect.py文件,对所有的元素yaml文件进行审查。

执行该文件:
![]()
可以看到,很短的时间内,我们就对所填写的YAML文件进行了审查。
现在我们基本所需要的组件已经大致完成了。
接下来我们将进行最重要的一环,封装selenium。
封装Selenium基类#
在工厂模式种我们是这样写的:

很直白,简单,又明了。
创建driver对象,打开百度网页,搜索selenium,点击搜索,然后停留5秒,查看结果,最后关闭浏览器。
那我们为什么要封装selenium的方法呢。首先我们上述这种较为原始的方法,基本不适用于平时做UI自动化测试的,因为在UI界面实际运行情况远远比较复杂,可能因为网络原因,或者控件原因,我们元素还没有显示出来,就进行点击或者输入。所以我们需要封装selenium方法,通过内置的显式等待或一定的条件语句,才能构建一个稳定的方法。而且把selenium方法封装起来,有利于平时的代码维护。
我们在page目录创建webpage.py文件。



在文件中我们对主要用了显式等待对selenium的click,send_keys等方法,做了二次封装。提高了运行的成功率。
好了我们完成了POM模型的一半左右的内容。接下来我们们进入页面对象。
创建页面对象#
在page_object目录下创建一个searchpage.py文件。

在该文件中我们对,输入搜索关键词,点击搜索,搜索联想,进行了封装。
并配置了注释。
在平时中我们应该养成写注释的习惯,因为过一段时间后,没有注释,代码读起来很费劲。
好了我们的页面对象此时业已完成了。下面我们开始编写测试用例。在开始测试用了之前我们先熟悉一下pytest测试框架。
简单了解Pytest#
打开pytest框架的官网。pytest: helps you write better programs — pytest documentation

官方教程我认为写的并不适合入门阅读,而且没有汉化版。
推荐看一下上海悠悠的pytest教程。
pytest.ini#
pytest项目中的配置文件,可以对pytest执行过程中操作做全局控制。
在项目根目录新建pytest.ini文件。

- addopts 指定执行时的其他参数说明:
--html=report/report.html --self-contained-html生成pytest-html带样式的报告-s输出我们用例中的调式信息-q安静的进行测试-v可以输出用例更加详细的执行信息,比如用例所在的文件及用例名称等
编写测试用例#
我们将使用pytest编写测试用例。
在TestCase目录中创建test_search.py文件。

我们测试用了就编写好了。
-
pytest.fixture 这个实现了和unittest的setup,teardown一样的前置启动,后置清理的装饰器。
-
第一个测试用例:
- 我们实现了在百度selenium关键字,并点击搜索按钮,并在搜索结果中,用正则查找结果页源代码,返回数量大于10我们就认为通过。
-
第二个测试用例:
- 我们实现了,搜索selenium,然后断言搜索候选中的所有结果有没有selenium关键字。
最后我们的在下面写一个执行启动的语句。
这时候我们应该进入执行了,但是还有一个问题,我们还没有把driver传递。
conftest.py#
我们在项目根目录下新建一个conftest.py文件。
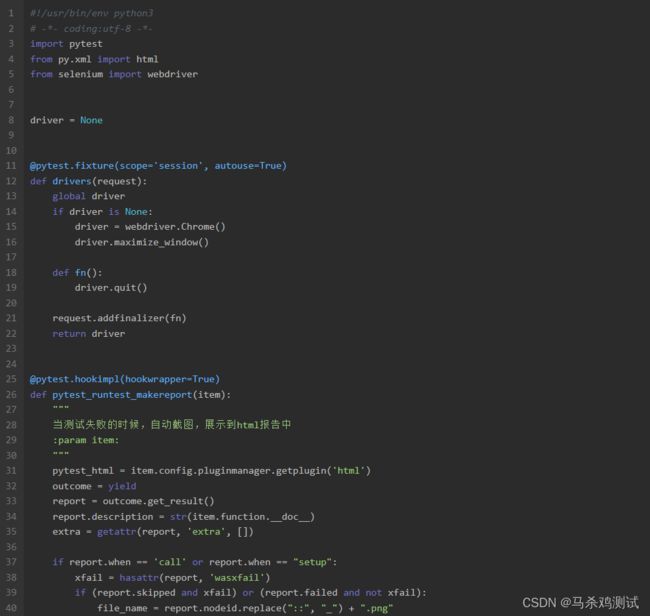

conftest.py测试框架pytest的胶水文件,里面用到了fixture的方法,封装并传递出了driver。
执行用例#
以上我们已经编写完成了整个框架和测试用例。
我们进入到当前项目的主目录执行命令:
![]()
命令行输出:
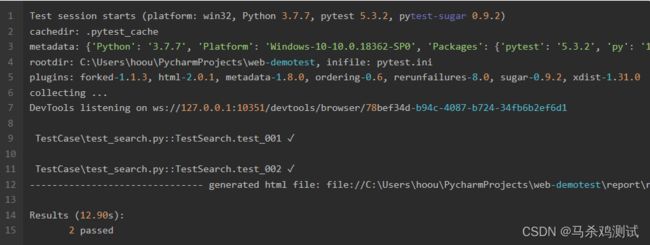
可以看到两条用例已经执行成功了。
项目的report目录中生成了一个report.html文件。
这就是生成的测试报告文件。
发送邮件#
当项目执行完成之后,需要发送到自己或者其他人邮箱里查看结果。
我们编写发送邮件的模块。
在utils目录中新建send_mail.py文件

执行该文件:
![]()
可以看到测试报告邮件已经发送成功了。打开邮箱。


成功收到了邮件。
这个demo项目就算是整体完工了;是不是很有心得,在发送邮件的那一刻很有成就感。
最后,想必你已经对pytest+selenium框架有了一个整体的认知了,在自动化测试的道路上又上了一层台阶。