Nginx 作为一款高性能的代理软件,在工作中常被用做负载均衡器、正向反向代理。最近在看了一个关于 Nginx 的视频,老师讲得很不错。笔者也记录了一下整套课程的一些重点和自己的理解。
上篇:https://segmentfault.com/a/11...
上篇主要跟大家讲述了一下如果使用 Nginx,也是为下篇进行铺垫。接下来的内容能让读者手上的 Nginx 发挥最大作用。
那我们开始吧!
sticky 维持状态
上篇介绍了几种调度算法,我们一起回顾一下里面的 ip_hash 和 url_hash
ip_hash:对于紧急扩容场景,使用这种策略能够快速引入新节点,但如果后端服务突然宕机会造成状态丢失,可以使用 Global Session 的方式解决(引入 Spring Session + Redis)。但后端服务数量太多也会对外置的 Redis 造成压力。
upstream flask { ip_hash; server 172.20.0.11:80; server 172.20.0.12:80; }比如 ERP 系统使用 URL 哈希比较合适,因为对于一个企业,多个用户发出的请求到达路由器后都会转换成同一个 IP,容易造成流量倾斜。考试系统也是相同道理。
url_hash:对于不支持 Cookies 的场景,一般会把 JSESSION_ID 放到 URL 中,这时候可以使用 url_hash 进行调度
- $cookie_jsessioni 基于 SSESION ID 的 hash
- $request_uri; 基于 url 的 hash
upstream flask { # hash $cookie_jsession; hash $request_uri; server 172.20.0.11:80; server 172.20.0.12:80; }不难发现,如果希望一个用户的所有请求都路由到一台上游服务时,必须依赖于
SESSION_ID。如果客户端不支持 Cookie、URL 长度还受限制,或者上游服务器压根是一台静态服务器,那么记录用户和上游服务器映射关系的工作就要前置到 Nginx 上了。sticky 模块就是专门用作这样的场景。- Bitbucket:https://bitbucket.org/nginx-g...
下载后解压,在
ngx_http_sticky_misc.c添加两个头文件定义#include#include
重新编译、尝试运行、备份、替换
./configure --prefix=/usr/local/nginx --add-module=/root/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d
mnake
make upgrade
cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak
cp objs/nginx /usr/local/nginx/sbin/nginx修改配置并重新加载配置文件
upstream flask {
sticky name=route expires=6h;
server 172.20.0.11:80;
server 172.20.0.12:80;
}刷新一下页面,发现同一个用户的多次访问会被调度到同一台主机上,且 Cookie 中多出了一个 route 字段。
sticky 的字段不能与后端服务器的 cookie 字段冲突
keepalive 提升性能
使用 Nginx 作为网关能够很好的保护内网服务的安全性,引入了代理节点难免会带来转发的损耗,对于需要持续转发的场景,开启 keepalive 能够减少频繁三次握手的开销。
时间同步的场景就不太适合开启 keepalive,静态资源服务也不适合开启 keepalive
通常情况下,浏览器发起请求时会在每一个请求中主动加上 Connection: keep-alive,服务器根据自己的意愿响应 Connection: keep-alive 或者 Connection: close
比如下面这个配置,
server {
keepalive_time 65;
keepalive_requests 15;
}
upstream demo {
keepalive_time 65;
...
}- keepalive_time:在某次请求后开始计时,这要在这段时间内有请求,会继续保持连接,并重置定时器
- keepalive_timeout:连接维持的总时长
- send_timeout:keepavlive 保持时间
- keepalive_disable:对某些浏览器禁用 keepalive,默认
msie6 - keepalive_requests:一次连接可以处理多少个请求
- send_timeout:两次请求间隔,默认值为 60 秒,大于该值就会关闭连接。对于一些耗时较长的动作需要额外注意这个配置
这里需要注意 send_timeout 和 keepalive_timeout 的区别:
keepavlive 开启后,客户端会向服务端发出心跳包,服务端会接收心跳包并重置定时器(send_timeout )。当定时器超时后服务端会关闭连接。而 send_timeout 其实和 keepavlue 没什么关系,当用户发起一次请求后开始计时,超过 send_timeout 后关闭连接。
配置完成后可以使用 Charles 进行测试,看看连接是否被复用和被复用的次数。

这里使用 abtest 进行一下压测,后面的压测只是做一个参考,在虚拟机中压测结果不是很准确。
# 安装 ABtest
$ yum install -y httpd-tools
# 进行一次压力测试
$ ab -n 100000 -c 30 http://192.168.80.154/abtest 参数说明:
- -n 即requests,用于指定压力测试总共的执行次数。
- -c 即concurrency,用于指定的并发数。
- -t 即timelimit,等待响应的最大时间(单位:秒)。
- -b 即windowsize,TCP发送/接收的缓冲大小(单位:字节)。
- -p 即postfile,发送POST请求时需要上传的文件,此外还必须设置-T参数。
- -u 即putfile,发送PUT请求时需要上传的文件,此外还必须设置-T参数。
- -T 即content-type,用于设置Content-Type请求头信息,例如:application/x-www-form-urlencoded,默认值为text/plain。
- -v 即verbosity,指定打印帮助信息的冗余级别。
- -w 以HTML表格形式打印结果。
- -i 使用HEAD请求代替GET请求。
- -x 插入字符串作为table标签的属性。
- -y 插入字符串作为tr标签的属性。
- -z 插入字符串作为td标签的属性。
- -C 添加cookie信息,例如:"Apache=1234"(可以重复该参数选项以添加多个)。
- -H 添加任意的请求头,例如:"Accept-Encoding: gzip",请求头将会添加在现有的多个请求头之后(可以重复该参数选项以添加多个)。
- -A 添加一个基本的网络认证信息,用户名和密码之间用英文冒号隔开。
- -P 添加一个基本的代理认证信息,用户名和密码之间用英文冒号隔开。
- -X 指定使用的和端口号,例如:"126.10.10.3:88"。
- -V 打印版本号并退出。
- -k 使用HTTP的KeepAlive特性。
- -d 不显示百分比。
- -S 不显示预估和警告信息。
- -g 输出结果信息到gnuplot格式的文件中。
- -e 输出结果信息到CSV格式的文件中。
- -r 指定接收到错误信息时不退出程序。
- -h 显示用法信息,其实就是ab -help。
大家可以测试一下下面几种情况,
- 直接压测上游服务器
- 压测代理服务器
- 关闭代理服务器和上游服务的 keepavlie
根据结果对比一下这两个参数
- Requests per second:每秒处理的请求(客户端接收到响应)
- Transfer rate:吞吐量
会发现开启 keepalive QPS 会更高。
链路上的可配参数
从代理接收客户端请求数据,到代理服务区将数据转发到上游服务器,最后接收响应数据转发返回客户端,中间过程可以进行
- 请求头修改
- Buffer 缓冲
- 超时控制

缓冲和超市控制
- set_header:设置header
- proxy_connect_timeout :与上游服务器连接超时时间、快速失败
- proxy_send_timeout:定义nginx向后端服务发送请求的间隔时间(不是耗时)。默认60秒,超过这个时间会关闭连接
- proxy_read_timeout:后端服务给nginx响应的时间,规定时间内后端服务没有给nginx响应,连接会被关闭,nginx返回504 Gateway Time-out。默认60秒
缓冲区
- proxy_requset_buffering:是否完全读到请求体之后再向上游服务器发送请求
- proxy_buffering :是否缓冲上游服务器数据
- proxy_buffers 32 64k;:缓冲区大小 32个 64k大小内存缓冲块
- proxy_buffer_size:header缓冲区大小
proxy_requset_buffering on;
proxy_buffering on;
proxy_buffer_size 64k;
proxy_buffers 32 128k;
proxy_busy_buffers_size 8k;
proxy_max_temp_file_size 1024m;- proxy_temp_file_write_size 8k:当启用从代理服务器到临时文件的响应的缓冲时,一次限制写入临时文件的数据的大小。 默认情况下,大小由proxy_buffer_size和proxy_buffers指令设置的两个缓冲区限制。 临时文件的最大大小由proxy_max_temp_file_size指令设置。
- proxy_max_temp_file_size 1024m;:临时文件最大值
proxy_temp_path :临时文件路径
proxy_temp_path /spool/nginx/proxy_temp 1 2;a temporary file might look like this:
/spool/nginx/proxy_temp/7/45/00000123457
对客户端的限制
- client_body_buffer_size:对客户端请求中的body缓冲区大小,看操作系统,默认32位8k 64位16k,如果请求体大于配置,则写入临时文件
- client_header_buffer_size:设置读取客户端请求体的缓冲区大小。 如果请求体大于缓冲区,则将整个请求体或仅将其部分写入临时文件。 默认32位8K。 64位平台16K。
- client_max_body_size 1000M;:默认1m,如果一个请求的大小超过配置的值,会返回413 (request Entity Too Large)错误给客户端。将size设置为0将禁用对客户端请求正文大小的检查。
- client_body_timeout:指定客户端与服务端建立连接后发送 request body 的超时时间。如果客户端在指定时间内没有发送任何内容,Nginx 返回 HTTP 408(Request Timed Out)
- client_header_timeout:客户端向服务端发送一个完整的 request header 的超时时间。如果客户端在指定时间内没有发送一个完整的 request header,Nginx 返回 HTTP 408(Request Timed Out)。
- client_body_temp_path path
[level1[level2[level3`]]]:在磁盘上客户端的body临时缓冲区位置 - client_body_in_file_only on:把body写入磁盘文件,请求结束也不会删除
- client_body_in_single_buffer:尽量缓冲body的时候在内存中使用连续单一缓冲区,在二次开发时使用
$request_body读取数据时性能会有所提高 - large_client_header_buffers:如果一个请求行或者一个请求头字段不能放入 client_header_buffer_size 大小的缓冲区,那么就会使用large_client_header_buffers,默认8k
压缩响应体
压缩响应体能够可以加快传输效率,但需要客户端和服务端支持共同的压缩算法。常用的算法有 gzip 和 brotil
GZIP 动态压缩
我们使用 Chrome 浏览器访问某站点时会自动带上一个 Header
Accept-Encoding: gzip表示浏览器支持 gzip 解压缩算法,服务器可以将响音体用 gzip 压缩后返回,在我们没有开启 GZIP 时,响应体的 Header 中 Content-Length 表示字符数量
Content-Length: 654当我们在 Nginx 中配置 GZIP
gzip on;
gzip_buffers 16 8k;
gzip_comp_level 6;
gzip_http_version 1.1;
gzip_min_length 256;
gzip_proxied any;
gzip_vary on;
gzip_types text/plain application/x-javascript text/css application/xml;
gzip_types
text/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xml
text/javascript application/javascript application/x-javascript
text/x-json application/json application/x-web-app-manifest+json
text/css text/plain text/x-component
font/opentype application/x-font-ttf application/vnd.ms-fontobject
image/x-icon;
gzip_disable "MSIE [1-6]\.(?!.*SV1)";再次请求发现没有 Content-Length,Content-Encoding 变成了
Transfer-Encoding: chunkedNginx 一边压缩一边响应,导致 Nginx 也不知道压缩后的文件大小,所以以 chunked 方式返回,chunked 表示以块为单位传输数据。当最后一个块为 0 字节时表示结束。
我们可以在 Chrome 中设置一下浏览器支持的压缩算法

相关配置的说明:
- gzip:是否开启 gzip
- gzip_buffers:buffer 大小
- gzip_comp_level:压缩等级,等级越高对 CPU 损耗越大
- gzip_http_version:http 最低版本
gzip_proxied:根据上游服务器返回的 Header 决定是否进行压缩
- off 为不做限制
作为反向代理时,针对上游服务器返回的头信息进行压缩
- expired - 启用压缩,如果header头中包含 "Expires" 头信息
- no-cache - 启用压缩,如果header头中包含 "Cache-Control:no-cache" 头信息
- no-store - 启用压缩,如果header头中包含 "Cache-Control:no-store" 头信息
- private - 启用压缩,如果header头中包含 "Cache-Control:private" 头信息
- no_last_modified - 启用压缩,如果header头中不包含 "Last-Modified" 头信息
- no_etag - 启用压缩 ,如果header头中不包含 "ETag" 头信息
- auth - 启用压缩 , 如果header头中包含 "Authorization" 头信息
- any - 无条件启用压缩
- gzip_vary:增加一个header,适配老的浏览器
Vary: Accept-Encoding - gzip_types:增加一个header,适配老的浏览器
Vary: Accept-Encoding - gzip_disable:禁止某些浏览器使用gzip,尽量不要在配置文件中使用正则表达式,这个尽量不配置
上面的配置方式属于动态压缩,有一个致命问题是无法使用 send_file 零拷贝。send_file 只能针对磁盘上的文件进行零拷贝。我们可以先把资源文件预先进行压缩,当用户请求时直接返回压缩后的文件
静态压缩
安装一下 http_gzip_static_module 和 http_gunzip_module
# 重新编译,加上下面参数
--with-http_gzip_static_module
--with-http_gunzip_module对于希望预先进行压缩的文件。使用下面命令进行压缩
# 压缩
$ gzip -r ./
# 解压缩
$ gunzip -r /在配置文件中添加配置
gzip_static always;- always:直接返回 gz 文件
- on:检查客户端是否支持 gzip,如果支持则返回 gz 文件,不支持则返回源文件
- off:关闭该模块
我们完全可以将源文件全部删除,只保留压缩文件。但当面对部分客户端不支持 gzip 时,在没有保留源文件的情况下我们可以配合 gunzip 模块,在服务端解压缩后再将数据返回。
gunzip on;
gunzip_buffers 16 8k;
gzip_static always;在实际生产环境中,对于静态文本文件如 js、css (代码源文件的压缩比可以很高),我们可以开启静态压缩取代动态压缩。当你希望移除源文件只保留压缩文件时,需要考虑到不支持 GZIP 的客户端,所有需要引入 gunzip 模块
Brotli 压缩
Brotli 是谷歌的一种压缩算法,压缩率比 GZIP 高 20%。
- ngx_brotli:https://github.com/google/ngx...
- brotli :https://github.com/google/brotli
下载最新版本,按照下面步骤进行编译
# 解压两个安装包,将 brotli 里的所有内容复制到 ngx_brotli/deps/brotli
$ rotli-1.0.9
$ -r ./* ../ngx_brotli-1.0.0rc/deps/brotli/
# 回到 Nginx 源码目录,编译
$ ./configure --with-compat --add-dynamic-module=/root/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/root/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module --with-http_gunzip_module
$ make
$ cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak
$ cp objs/nginx /usr/local/nginx/sbin/nginx
$ mkdir -p /usr/local/nginx/modules
$ cp ./objs/ngx_http_brotli_static_module.so /usr/local/nginx/modules/
$ cp .objs/ngx_http_brotli_filter_module.so /usr/local/nginx/modules/
修改配置文件
# 加载顶部
load_module "/usr/local/nginx/modules/ngx_http_brotli_filter_module.so";
load_module "/usr/local/nginx/modules/ngx_http_brotli_static_module.so";
# 加到某个 server
brotli on;
brotli_static on;
brotli_comp_level 6;
brotli_buffers 16 8k;
brotli_min_length 20;
brotli_types text/plain text/css text/javascript application/javascript text/xml application/xml application/xml+rss application/json image/jpeg image/gif image/png;brotli 可以和 gzip 一起使用,当浏览器不支持 br 时会自动使用 gzip
Chrome 浏览器只会在 HTTPS 情况下使用 br,这里可以使用 curl 来测试一下
$ curl -H "Accept-Encoding: br" -I http://192.168.80.154/static/test.txt
HTTP/1.1 200 OK
Server: nginx/1.21.6
Date: Sun, 26 Jun 2022 13:55:45 GMT
Content-Type: text/plain
Last-Modified: Sun, 26 Jun 2022 10:08:17 GMT
Connection: keep-alive
Vary: Accept-Encoding
ETag: W/"62b83011-268"
Content-Encoding: brconcat 请求合并
Concat 是淘宝开源的一个模块,他可以将多个静态资源请求合并,比如某个页面需要下面两个 css
为了减少请求次数,我们可以将两个请求合并
淘宝官网就有类似的操作

我们可以下载安装一下 Concat 模块,尝试合并一下 CSS
# 静态编译
$ ./configure --with-compat --add-dynamic-module=/root/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/root/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --add-module=/root/nginx-http-concat-master --with-http_gzip_static_module --with-http_gunzip_module
$ make
$ cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak
$ cp objs/nginx /usr/local/nginx/sbin/nginx添加配置
location /static/css/ {
concat on;
concat_max_files 20;
}创建两个 CSS 文件,尝试请求
curl http://192.168.80.154/static/??test02.css,test02.css可以或则两个文件合并的结果。由于这里的合并需要将两个文件加载到内存,所以无法使用 send_file。
预先进行资源静态化
对于一些并发数较高的请求,一般优化思路有三个:
- 多级缓存
- 预先资源预先静态化
- 将数据放到距离用户更近的地方
资源静态化是借助一些模板引擎,将动态数据和静态页面进行渲染并生成文件,将该文件放置到 Nginx 中。

- 缓存一致性问题:对于一些类似评论、价格等数据我们可以使用异步方式获取
- 静态页面同步问题:可以使用 rsync + inotify 进行文件同步
文件合并输出:对于一个页面,比如淘宝的任意一个商品详情,可以将他拆分成三个部分:
- 固定的文本:例如导航栏、页头页尾
- 相对固定的文本:比如商品的描述、参数等
- 动态数据:比如价格、购物车等等
对于固定的文本,我们可以将其永久放在资源服务器上,使用 Nginx 的一些页面嵌套的技术与非固定页面进行合并。对于相对固定的文本,我们可以使用一些模板引擎进行页面渲染,实现将选然后的文件放在某台服务器,让该服务器将页面同步到各台 Nginx 中,对于动态的数据我们就使用异步的方式获取即可。
SSI 合并输出
SSI 是 Nginx 进行 HTML 文件合并的模块,用法类似于模板引擎:
使用该模块就能够将固定的文件内容抽离,相关的配置如下:
- ssi on:是否开启 SSI
- ssi_min_file_chunk:向磁盘存储并使用sendfile发送,文件大小最小值
- ssi_last_modified :是否保留lastmodified
- ssi_silent_errors :不显示逻辑错误
- ssi_value_length:限制脚本参数最大长度
- ssi_types :默认text/html;如果需要其他mime类型 需要设置
比如我们可以抽离出页头页尾:
Hello word
中间的部分交给模板引擎生成,再 incluede 到页面中。这种方式同样无法使用 send_file
文件同步方案
文件同步可以使用推模式或者拉模式,借助工具 rsync 可以实现文件的对比、压缩和传输
我们可以在源服务器启动 rsync,在目标服务器定时拉取资源文件。
# 安装 rsync
$ yum install -y rsync
# 准备密码文件
$ echo "hello:123" >> /etc/rsyncd.pwd
$ chmod 600 /etc/rsyncd.pwd
# 修改配置
$ vim /etc/rsyncd.conf
auth users = hello
secrets file = /etc/rsyncd.pwd
[ftp]
path = /usr/local/nginx/flask-demo
comment = ftp export area
$ rsync --daemon
$ firewall-cmd --add-port=873/tcp --permanent
$ firewall-cmd --reload目标服务器查看
$ rsync --list-only [email protected]:154::ftp/
passwordL 123
drwxr-xr-x 39 2022/06/18 12:01:31 .
-rw-r--r-- 2,406 2022/06/18 12:01:31 invalid.png
drwxr-xr-x 72 2022/06/26 23:40:45 static拉模式
拉取最新文件
$ rsync -avz /usr/local/nginx/flask-demo [email protected]:154::ftp/使用 SSH 进行文件同步
$ rsync -avz --delete [email protected]::ftp/ /usr/local/nginx/flask-demo/rsync 其他参数:
| 选项 | 含义 |
|---|---|
| -a | 包含-rtplgoD |
| -r | 同步目录时要加上,类似cp时的-r选项 |
| -v | 同步时显示一些信息,让我们知道同步的过程 |
| -l | 保留软连接 |
| -L | 加上该选项后,同步软链接时会把源文件给同步 |
| -p | 保持文件的权限属性 |
| -o | 保持文件的属主 |
| -g | 保持文件的属组 |
| -D | 保持设备文件信息 |
| -t | 保持文件的时间属性 |
| –delete | 删除DEST中SRC没有的文件 |
| –exclude | 过滤指定文件,如–exclude “logs”会把文件名包含logs的文件或者目录过滤掉,不同步 |
| -P | 显示同步过程,比如速率,比-v更加详细 |
| -u | 加上该选项后,如果DEST中的文件比SRC新,则不同步 |
| -z | 传输时压缩 |
推模式
这时需要在目标服务器启动 rysnc,源服务器进行推送。先修改目标服务器的配置文件
uid = root
gid = root
readonly = no
auth users = hello
secrets file = /etc/rsyncd.pwd
[ftp]
path = /usr/local/nginx/flask-demo
comment = ftp export area
生产环境要单独创建用户和用户组哈。启动 rsync,将文件推送到目标服务器
# 在源服务器记录目标服务器认证密码
$ echo "123" > /etc/rsyncd.passwd.client
$ chmod 600 /etc/rsyncd.passwd.client
$ firewall-cmd --add-port=873/tcp --permanent
$ firewall-cmd --reload
$ rsync -az --delete --password-file=/etc/rsyncd.passwd.client /usr/local/nginx/flask-demo/ [email protected]::ftp/需要借助 inotify 进行目录监控,当存在文件变更时进行推送
$ ./configure
$ make
$ make install监控指定目录
$ /usr/local/inotify/bin/inotifywait -mrq --timefmt '%Y-%m-%d %H:%M:%S' --format '%T %w%f %e' -e close_write,modify,delete,create,attrib,move //usr/local/nginx/flask-demo/
2022-06-27 14:12:27 //usr/local/nginx/flask-demo/New File CREATE
2022-06-27 14:12:27 //usr/local/nginx/flask-demo/New File CLOSE_WRITE,CLOSE
2022-06-27 14:12:29 //usr/local/nginx/flask-demo/heelo CREATE
2022-06-27 14:12:29 //usr/local/nginx/flask-demo/New File DELETE这样我们就可以编写一个自动化脚本:
#!/bin/bash
/usr/local/inotify/bin/inotifywait -mrq --timefmt '%d/%m/%y %H:%M' --format '%T %w%f %e' -e close_write,modify,delete,create,attrib,move //usr/local/nginx/html/ | while read file
do
rsync -az --delete --password-file=/etc/rsyncd.passwd.client /usr/local/nginx/html/ [email protected]::ftp/
done
部署到距离用户更近的地方
前面提到的资源静态化,使用了 rsync 进行文件同步。在公网上我们希望能够将资源部署到距离用户最近的地方,这时候就需要 CDN 分布式内容分发网络。

中间的 CDN 服务器可以使用 Nginx 搭建,一般 DNS 解析都比较智能,能够根据你的 ISP 返回指定的 CDN 服务器地址(这个需要去云平台配置)。
比较不智能的方式是 GEOIP,使用场景比较少。
获取用户 IP 地址
由于引入了代理服务器,上游服务无法获取客户端 IP 地址。我们可以在 Nginx 中为 HTTP Header 加上 X-Forwarded-For
proxy_set_header X-Forwarded-For $remote_addr;GEOIP
Nginx 借助 GEOIP 也可以做 IP 归属地检查,并根据检查结果返回不同的资源,比如 IP 来自于中国就返回中文站点。
- GEOIP 数据库:https://dev.maxmind.com/geoip...
MMDB依赖:https://github.com/maxmind/li...
$ ./configure $ make && make install # 添加动态链接库 $ echo /usr/local/lib >> /etc/ld.so.conf.d/local.conf $ ldconfigNginx 模块:https://github.com/leev/ngx_h...
$ ./configure --with-compat --add-dynamic-module=/root/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/root/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --add-module=/root/nginx-http-concat-master --with-http_gzip_static_module --with-http_gunzip_module --add-module=/root/ngx_http_geoip2_module-3.4 $ make $ cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak $ cp objs/nginx /usr/local/nginx/sbin/nginx
快速配置
geoip2 /root/GeoLite2-Country_20220628/GeoLite2-Country.mmdb {
$geoip2_country_code country iso_code;
}
add_header country $geoip2_country_code;更多配置:http://nginx.org/en/docs/http...
多级缓存
上面介绍了资源静态化和 CDN,都是让经量少的请求到达上游服务器。
除了上面的两种方式,还可以在客户端做手脚:
比如一次大促活动,由于用户不断访问热门商品的详情页,服务器是可以提前预知那些商品是热卖商品。例如某商品只有 100 件,那么设计者完全可以在用户中随机挑选 200 位用户让他们参与抢购,其他用户直接展示抢完了(不发起请求)
利用缓存可以提高用户响应速度的同时降低服务器的负载。按照与用户的距离划分,可以分为下面几个层级的缓存
- 浏览器缓存
- CNS 缓存
- 正向代理缓存
- 反向代理缓存
- Nginx 内存缓存
- Nginx 外置缓存
- 上游服务器缓存

浏览器缓存
比如 JD,可以看到不禁用缓存的情况下,有很多请求来自于 memory 或者 disk,加载速率比较高。怎么样的请求才能使用浏览器的缓存咧?
强制缓存:指定有效期的方式:当响应头存在 Expire 字段时,浏览器会将请求缓存至有效时间。这里的有效时间依赖于客户端系统时间,如果客户端时间没有同步则会产生偏差。
expires 30s; #缓存30秒 expires 30m; #缓存30分钟 expires 2h; #缓存2小时 expires 30d; #缓存30天http1.1的规范,使用max-age表示文件可以在浏览器中缓存的时间以秒为单位
标记 类型 功能 public 响应头 响应的数据可以被缓存,客户端和代理层都可以缓存 private 响应头 可私有缓存,客户端可以缓存,代理层不能缓存(CDN,proxy_pass) no-cache 请求头 可以使用本地缓存,但是必须发送请求到服务器回源验证 no-store 请求和响应 应禁用缓存 max-age 请求和响应 文件可以在浏览器中缓存的时间以秒为单位 s-maxage 请求和响应 用户代理层缓存,CDN下发,当客户端数据过期时会重新校验 max-stale 请求和响应 缓存最大使用时间,如果缓存过期,但还在这个时间范围内则可以使用缓存数据 min-fresh 请求和响应 缓存最小使用时间, must-revalidate 请求和响应 当缓存过期后,必须回源重新请求资源。比no-cache更严格。因为HTTP 规范是允许客户端在某些特殊情况下直接使用过期缓存的,比如校验请求发送失败的时候。那么带有must-revalidate的缓存必须校验,其他条件全部失效。 proxy-revalidate 请求和响应 和must-revalidate类似,只对CDN这种代理服务器有效,客户端遇到此头,需要回源验证 stale-while-revalidate 响应 表示在指定时间内可以先使用本地缓存,后台进行异步校验 stale-if-error 响应 在指定时间内,重新验证时返回状态码为5XX的时候,可以用本地缓存 only-if-cached 响应 那么只使用缓存内容,如果没有缓存 则504 getway timeout
协商缓存:判断文件修改状态的方式(Nginx 返回静态资源的默认方式):第一次访问静态资源时,响应头包含了 Etag(文件名、大小、修改时间生成的标识)和 Last-Modified(文件上次更新时间),第二次请求该资源时请求头需要带上这两个头(Last-Modified 改名成 If-Modified-Since),如果 Nginx 判断文件没有被修改则返回 304 No Modified,不会返回文件
如何关闭
etag off; add_header "Last-Modified" ""; # 或者 if_modified_since off;
在实际应用中,当我们使用 Chrome 打开一个新的标签页输入某个网站,会触发强制缓存的逻辑,检查内存或者磁盘是否存在缓存,如果存在则通过 Expire 和 Cache-Control 判断一下是否过期。当用户按下 F5 刷新时则走协商缓存的逻辑,通过 Etag 和 If-Modified-Since 协商是否能够使用缓存。
有几点需要注意:
- 不只是静态资源,动态资源也很可能进行缓存。上游服务器需要自己生成 Etag(可以使用织入的方式进行),如果数据没有变化则返回 304
- 对于一些不希望使用缓存的请求,可以在 URL 上加上一些随机数
- 缓存的作用不经可以保护上游服务,还可以再没有联网时提高用户体验。但使用时需要看看客户端是否支持标准 HTTP
反向代理文件缓存
当我们通过代理服务器访问上游服务器时,上游服务器返回的结果可以被 Nginx 缓存,当下一次有相同的访问时就可以直接返回缓存中的数据。
只需要进行以下配置即可
http模块:
proxy_cache_path /ngx_tmp levels=1:2 keys_zone=test_cache:100m inactive=1d max_size=10g ;
location模块:
add_header Nginx-Cache "$upstream_cache_status";
proxy_cache test_cache;
proxy_cache_valid 168h;其中 proxy_cache_path 中,第一个参数是路径,level 表示层级(比如这里的 1:2 表示第一层目录名称是一个字符,2 表示第二层目录以两个字符命名),keys_zone 是一个标识符,后面引用该配置时需要用到。100m 表示 KV (每一个被缓存的文件都有一个 Key,Value 是缓存文件所在路径)在内存中的大小。inactive 表示文件的删除时间,到点了会自动删除。max_size 表示缓存文件总大小最大值。
- proxy_cache_use_stale:默认 off。在什么时候可以使用过期缓存,可选
error|timeout|invalid_header|updating|http_500|http_502|http_503|http_504|http_403|http_404|http_429|off - proxy_cache_background_update:默认 off,运行开启子请求更新过期的内容。同时会把过期的内容返回给客户端
proxy_no_cache:什么时候不使用缓存,比如下面设置中的变量为 0 则不使用
proxy_no_cache $cookie_nocache $arg_nocache$arg_comment; proxy_no_cache $http_pragma $http_authorization;- proxy_cache_bypass:缓存大小
- proxy_cache_convert_head:默认为 on,表示是否把 head 请求转换为 get 请求获取数据并缓存,如果关闭 需要在
cache key中添加 $request_method 以便区分缓存内容 - proxy_cache_lock:由于可能存在多个请求完成数据更新,这里可以使用锁来保证数据一致性。(这里是一个读-写场景)
- proxy_cache_lock_age:锁超时时间
- proxy_cache_key:默认
$scheme$proxy_host$request_uri,缓存的 Key - proxy_cache_revalidate:向上游服务器发送 If-Modified-Since 来校验是否需要重新拉取缓存
proxy_cache_valid:缓存过期时间,超出时间后会重新获取。
proxy_cache_valid 200 302 10m; proxy_cache_valid 301 1h; proxy_cache_valid any 1m;
我们可以尝试配置后,使用浏览器访问,页面会被缓存在 Nginx 下,随便打开一个可以看到文件中包含缓存的 Key、Date 和缓存文件内容。但目录结果阅读性差,当我们需要删除某个页面的缓存时比较麻烦,如果希望清除指定缓存,需要依赖另一个插件。
下载安装后配置
location ~ /purge(/.*) {
proxy_cache_purge test_cache $1;
}
注意这里配置的 key 是 uri,所以对应的 proxy_cache 配置的 proxy_cache_key 也要是 uri
proxy_cache_key $uri;配置完成后尝试通过 GET 或者 PURGE 请求清除缓存
range
对于数据大小已知,Response 包含 Content-Length、服务器支持 Http Range 的情况,我们可以在请求头上带上
Range: bytes=0-5指定需要获取的数据范围
如果 Content-Type 是 Stream,则不支持 range
能完成片段读取的前提有两个:
- 上游服务器支持 Range
代理服务器将 Range Header 传递到后端服务器
proxy_set_header Range $http_range;
在使用 Range 时,如果希望使用上 Proxy Cache 则需要注意下面的配置
- proxy_cache_max_range_offset:range最大值,超过之后不做缓存,默认情况下 不需要对单文件较大的资源做缓存
- proxy_cache_methods:默认为 get、header
- proxy_cache_min_uses:请求多少次才进行缓存
- proxy_cache_path:指定存储根目录
- levels=1:2:存储层级,当需要进行磁盘扩容是可以使用软连接跨越文件系统
- use_temp_path:默认创建缓存文件时,先向缓冲区创建临时文件,再移动到缓存目录
- inactive:指定时间内未被访问过的缓存将被删除
配置:
server {
listen 3128;
# dns resolver used by forward proxying
resolver 8.8.8.8;
# forward proxy for CONNECT request
proxy_connect;
proxy_connect_allow 443 563;
proxy_connect_connect_timeout 10s;
proxy_connect_read_timeout 10s;
proxy_connect_send_timeout 10s;
# forward proxy for non-CONNECT request
location / {
proxy_pass http://$host;
proxy_set_header Host $host;
}
}Nginx 进程缓存
Nginx 提供了 shared_dict,多 Worker 共享,在我们使用 lua 进行二次开发的时候有用,稍后会赘述。这里先说一个可优化的点
open_file_cache 优化
当 Nginx 需要将某个静态资源返回给用户时,需要经历下面的系统调用
$ strace -p {Nginx Worker PID}
strace: Process 1135 attached
epoll_wait(8, [{EPOLLIN, {u32=90669072, u64=139642362363920}}], 512, -1) = 1
accept4(6, {sa_family=AF_INET, sin_port=htons(13822), sin_addr=inet_addr("192.168.80.1")}, [112->16], SOCK_NONBLOCK) = 3
epoll_ctl(8, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLRDHUP|EPOLLET, {u32=90669792, u64=139642362364640}}) = 0
epoll_wait(8, [{EPOLLIN, {u32=90669072, u64=139642362363920}}], 512, 60000) = 1
accept4(6, {sa_family=AF_INET, sin_port=htons(13823), sin_addr=inet_addr("192.168.80.1")}, [112->16], SOCK_NONBLOCK) = 10
epoll_ctl(8, EPOLL_CTL_ADD, 10, {EPOLLIN|EPOLLRDHUP|EPOLLET, {u32=90669552, u64=139642362364400}}) = 0
epoll_wait(8, [{EPOLLIN, {u32=90669792, u64=139642362364640}}], 512, 59999) = 1
recvfrom(3, "GET /static/test.txt HTTP/1.1\r\nH"..., 1024, 0, NULL, NULL) = 492
open("/usr/local/nginx//flask-demo/static/test.txt.gz", O_RDONLY|O_NONBLOCK) = 11
fstat(11, {st_mode=S_IFREG|0644, st_size=616, ...}) = 0
writev(3, [{iov_base="HTTP/1.1 200 OK\r\nServer: nginx/1"..., iov_len=264}], 1) = 264
sendfile(3, 11, [0] => [616], 616) = 616
write(4, "192.168.80.1 - - [30/Jun/2022:10"..., 204) = 204
close(11) = 0
setsockopt(3, SOL_TCP, TCP_NODELAY, [1], 4) = 0
每一次请求都会先 open 文件,再 sendfile 出去。这里可以进行缓存一下文件句柄,避免反复创建销毁(配置到 Server 下面)
open_file_cache max=500 inactive=60s
open_file_cache_min_uses 1;
open_file_cache_valid 60s;
open_file_cache_errors on- max:缓存最多多少个句柄,inactive:什么时候删除句柄
- open_file_cache_min_uses:访问多少次后才进行缓存
- open_file_cache_valid:缓存有效时间
- open_file_cache_errors:是否对错误信息进行缓存
配置完成后连续发起请求
epoll_wait(8, [{EPOLLIN, {u32=4025118736, u64=140621254389776}}], 512, -1) = 1
accept4(6, {sa_family=AF_INET, sin_port=htons(3464), sin_addr=inet_addr("192.168.80.1")}, [112->16], SOCK_NONBLOCK) = 3
epoll_ctl(8, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLRDHUP|EPOLLET, {u32=4025119216, u64=140621254390256}}) = 0
epoll_wait(8, [{EPOLLIN, {u32=4025119216, u64=140621254390256}}], 512, 60000) = 1
recvfrom(3, "GET /static/test.txt HTTP/1.1\r\nH"..., 1024, 0, NULL, NULL) = 418
open("/usr/local/nginx//flask-demo/static/test.txt", O_RDONLY|O_NONBLOCK) = 10
fstat(10, {st_mode=S_IFREG|0644, st_size=1208, ...}) = 0
writev(3, [{iov_base="HTTP/1.1 200 OK\r\nServer: nginx/1"..., iov_len=240}], 1) = 240
sendfile(3, 10, [0] => [1208], 1208) = 1208
write(4, "192.168.80.1 - - [30/Jun/2022:12"..., 205) = 205
setsockopt(3, SOL_TCP, TCP_NODELAY, [1], 4) = 0
epoll_wait(8, [{EPOLLIN, {u32=4025119216, u64=140621254390256}}], 512, 65000) = 1
recvfrom(3, "GET /static/test.txt HTTP/1.1\r\nH"..., 1024, 0, NULL, NULL) = 418
writev(3, [{iov_base="HTTP/1.1 200 OK\r\nServer: nginx/1"..., iov_len=240}], 1) = 240
sendfile(3, 10, [0] => [1208], 1208) = 1208
write(4, "192.168.80.1 - - [30/Jun/2022:12"..., 205) = 205可见没有再 open file 了
外置缓存
我们需要先了解两个知识点:匿名 location 和 return。
- 匿名 location 相当于被 private 修饰的 location,外部无法直接访问,
- return:响应 Response
比如下面这个例子
error_page 404 = @fallback;
location @fallback {
add_header "Content-Type" text/plain";
return 200 "page no found";
}随意访问一个不存在的文件不再会返回 404。
Memcached
当 Nginx 所在主机的内存不够用时,可以使用 memcached 或者 redis 扩容。先看 memcached,Nginx 中提供的模块只支持 get 操作,所以需要外部应用程序事先进行 set 操作。
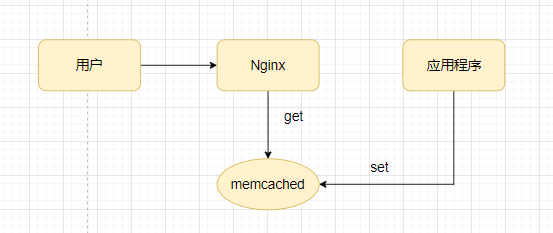
我们可以快速体验一下
# 安装
$ yum -y install memcached
# 查看状态
$ memcached-tool 127.0.0.1:11211 stats添加配置
location /memcached {
set $memcached_key "$uri?$args";
memcached_pass 127.0.0.1:11211;
add_header X-Cache-Satus HIT;
add_header Content-Type 'text/html; charset=utf-8'; # 强制响应数据格式为html
}先用 telnet 模拟一下应用程序 set
$ telent localhost 11211
set /memcached/test? 0 0 5
hello
$ curl localhost/memcached/test?
hello参数中set 第一个是 flags,第二个是有效期,第三个内容字节数
Redis
Nginx 提供的 Redis 模块既可以进行 get/set 操作,所以 redis 完全可以充当 proxy cache 使用
- Github:https://github.com/openresty/...
- Openresty:http://openresty.org/cn/
由于 redis2-nginx-module 需要依赖 ngx_set_misc 等依赖,ngx_set_misc 又依赖于其他模块,所以干脆直接使用 OpenResty 了
编译方式和 Nginx 完全一致
./configure --prefix=/usr/local/openresty安装好后编写一下 service file
$ tee /usr/lib/systemd/system/openresty.service <通过这个模块可以通过 URL 进行一些 Redis 操作。
location = /get {
default_type text/plain;
set_unescape_uri $key $arg_key; # this requires ngx_set_misc
redis2_query get $key;
redis2_pass localhost:6379;
}
location = /set {
default_type text/plain;
set_unescape_uri $key $arg_key; # this requires ngx_set_misc
set_unescape_uri $val $arg_val; # this requires ngx_set_misc
redis2_query set $key $val;
redis2_pass localhsot:6379;
}
location = /incr {
default_type text/plain;
set_unescape_uri $key $arg_key; # this requires ngx_set_misc
redis2_query incr $keyl;
redis2_pass localhsot:6379;
}
较为复杂的操作可以通过后面学习的 lua 脚本完成。
Stream 模块
一个四层代理模块,可以代理 TCP 和 UDP。例如 MySQL 多主模式中,可以借助 Nginx 做简单的负载均衡,应用更新上线时也可以做灰度发布。
stream {
server {
listen 6666;
proxy_pass mysql;
}
upstream mysql {
server 192.168.0.2:3306;
server 192.168.0.3:3306;
}
}文档:http://nginx.org/en/docs/stre...
QPS 限制
先介绍一下压缩工具 jmatter
步骤:
创建线程组,三个核心参数:
- Number of threads:线程数
- Range-up period:启动间隔
- Loop Count:循环次数
- 创建 HTTP 请求
创建结果展示,下面三个视图比较重要
Summary Results:
- Label:取样器/监听器名称
- Samples :事务数量
- Average:平均一个完成一个事务消耗的时间(平均响应时间)
- Median:所有响应时间的中间值,也就是 50% 用户的响应时间,大概是这个意思
- Min:最小响应时间
- Max:最大响应时间以上单位都是ms
- Std.Dev:偏离量,越小表示越稳定
- Error %:错误事务率
- Throughtput:每秒事务数,即tps
- Recieve、Sent、Arg KB/sec:网络吞吐量

Nginx 支持三种限流方式:
漏桶(切合实际网络环境)
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; location / { limit_req zone=one burst=5; root html; }binary_remote_addr 表示以二进制远程地址(只是 IP 地址不包含端口)作为限制单位(也可以使用 server_name),zone 为该规则的名称,10m 是在内存维护了客户吨发起请求的速率。rate 是速率。localtion 中的 burst 是同大小。
一一切都是为了 Nginx 按照 rate 速度处理请求,
- 当没有设置 burst 时,一旦请求速率超过 rate 就会返回 503
- burst 表示处理突发流量的能力,可以理解为桶。速度过快的请求会暂时存放在这里,按照 rate 的速度慢慢处理,当桶满了会拒绝请求。
- nodelay 能够取消 burst 缓冲,让 burst 瞬时处理完所有i请求,并拒绝所有不符合速率的请求,直到客户端速率恢复为止,
上面三点可以通过 jmatter 进行测试
令牌桶(为不同用户进行限速,资源下载软件的 VIP、视频播放先全速再限速)
令牌桶中保存 n 个令牌,每个令牌可能代表着带宽,不同等级的用户可以获取到不同个数的令牌以得到不同的下载速度。Nginx 官方没有实现该功能。
带宽限制
location / { limit_rate_after 1m; limit_rate 1k; }这个功能在视频播放中有用,先让用户看的舒服一点再限速,第一可以让用户充值二是用户可能对视频不感兴趣没必要加载这么多内容,
并发连接(服务端方式客户端多线程下载,基于计数器)
limit_conn_zone $binary_remote_addr zone=two:10m; location / { limit_rate 20; limit_conn two 1; root html; }limit_conn 中的第二个蚕食是限制的连接数
日志
低价值的日志经过采集到大数据平台后,通过机器学习等算法处理能够获得用户画像、用户行为轨迹等高价值数据,Nginx 相关配置
- binary_remote_addr:http://nginx.org/en/docs/http...
- ngx_http_empty_gif_module:http://nginx.org/en/docs/http...
先说 ngx_http_empty_gif_module 模块,访问 ngx_http_empty_gif_module 会返回一个 1x1 像素的图片,我们可以通过 img 标签内嵌到主页上,传递用户的行为信息,配置如下
location = /_.gif {
empty_gif;
}访问后可以看到 access.log
$ tail -f /usr/local/nginx/logs/access.log
192.168.80.1 - - [01/Jul/2022:10:51:39 +0800] "GET //_.gif HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"access.log 相关配置
access_log /path/to/log.gz combined gzip flush=5m buffer=32k;combined 是系统定义的一个 log_format,flush 是 log_buffer 刷盘时机
log_format combined '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"';如果采集器要求我们输出 json,可以设置对应的 format
log_format ngxlog json '{"timestamp":"$time_iso8601",'
'"source":"$server_addr",'
'"hostname":"$hostname",'
'"remote_user":"$remote_user",'
'"ip":"$http_x_forwarded_for",'
'"client":"$remote_addr",'
'"request_method":"$request_method",'
'"scheme":"$scheme",'
'"domain":"$server_name",'
'"referer":"$http_referer",'
'"request":"$request_uri",'
'"requesturl":"$request",'
'"args":"$args",'
'"size":$body_bytes_sent,'
'"status": $status,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamaddr":"$upstream_addr",'
'"http_user_agent":"$http_user_agent",'
'"http_cookie":"$http_cookie",'
'"https":"$https"'
'}';我们还可以缓存一下 log file 的句柄
open_log_file_cache max=N [inactive=time] [min_uses=N] [valid=time];error.log
错误日志则只能设置日志路径和日志等级
error_log** *file* [*level*];logrotale:Linux 自带的日志绕接工具。这里简单说一下如何在不影响应用程序运行情况ia进行日志分割
- mv + create:应用程序打开一个文件后,对文件的读写落实到物理块,即使在此过程中我们修改了文件名称。所以 logrotale 可以直接重命名日志文件,然后发送信号给应用程序,应用程序自己 reload 配置文件
- copy + truncate:当应用程序不支持 reload 时,logrotale 可以先将部分内容复制出来,再缩小原来的文件
详细:https://wsgzao.github.io/post...
健康检查机制
被动检查机制
文档:http://nginx.org/en/docs/http...
proxy_next_upstream:触发下次重试的情况
error与服务器建立连接,向其传递请求或读取响应头时发生错误;timeout在与服务器建立连接,向其传递请求或读取响应头时发生超时;invalid_header服务器返回空的或无效的响应;http_500服务器返回代码为500的响应;http_502服务器返回代码为502的响应;/ttp_503服务器返回代码为503的响应;http_504服务器返回代码504的响应;http_403服务器返回代码为403的响应;http_404服务器返回代码为404的响应;http_429服务器返回代码为429的响应;
不了解这个机制,在日常开发web服务的时候,就可能会踩坑。
比如有这么一个场景:一个用于导入数据的web页面,上传一个excel,通过读取、处理excel,向数据库中插入数据,处理时间较长(如1分钟),且为同步操作(即处理完成后才返回结果)。暂且不论这种方式的好坏,若nginx配置的响应等待时间(proxy_read_timeout)为30秒,就会触发超时重试,将请求又打到另一台。如果处理中没有考虑到重复数据的场景,就会发生数据多次重复插入!(当然,这种场景,内网可以通过机器名访问该服务器进行操作,就可以绕过nginx了,不过外网就没办法了)
- max_fails:最大失败次数,0为标记一直可用,不检查健康状态
- fail_timeout:失效时间,当fail_timeout时间内失败了max_fails次,标记服务不可用,fail_timeout时间后会再次激活次服务
- proxy_next_upstream_timeout:重试最大超时时间
- proxy_next_upstream_tries:重试次数
主动检查机制:
- tengine版本:https://github.com/yaoweibin/
如果要使用开源版本,需要安装 1.20 的 Nginx,并 patch 一下 module 中的补丁
可以尝试将他合并到开源版的 Nginx,它可以主动探测
upstream backend {
# server 192.168.44.102 weight=8 down;
server 172.20.0.11;
server 172.20.0.11;
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
check_http_send "HEAD / HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
location /status {
check_status;
access_log off;
}
location / {
proxy_pass http://backend;
root html;
}访问 http://192.168.80.154/status 可以看到上游服务的健康情况
Linux 中打补丁的方法:https://blog.csdn.net/longint...
制作补丁
$ diff -Nur src src_new >src.patch打补丁
$ patch -p0
Lua 脚本
安装 Openresty 后,可以通过下面这些途径使用 lua 脚本
直接输出
location /lua {
default_type text/html;
content_by_lua '
ngx.say("Hello, World!
")
';
}引用文件
# 这里打开热编译,即每次请求都会重新编译 lua 脚本,方便测试
lua_code_cache off;
location /lua {
default_type text/html;
content_by_lua_file lua/show_headers.lua;
}lua_code_cache off 表示进行热部署,每次请求都会加载一次 lua
show_headers.lua 内容如下
local url_args = ngx.req.get_headers()
for k, v in pairs(url_args) do
if type(v) == 'table' then
ngx.say(k, " : ", table.concat(v, ", "), "
")
else
ngx.say(k, " : ", v, "
")
end
end还可以在配置文件中引入代码块,但不是很推荐
content_by_lua_block {
ngx.say(ngx.var.arg_a)
}- lua_ngx_api:https://openresty-reference.r...
使用 Nginx 缓存
nginx 原生的多进程共享内存:share dict,访问需要上锁
配置文件
lua_shared_dict shared_data 1m;shared_dict.lua
local shared_data = ngx.shared.shared_data local key = "demo" local val = shared_data:get(key) local default_val = 0 if not val then shared_data:set(key, default_val) ngx.say("lazy set key", "
") return end val = shared_data:incr(key, 1) ngx.say("val =", val, "
")lua-lrucache,是 lua 实现的单进程内存
content_by_lua_block { require("lua/lurcache.lua").go() }注意默认的加载路径是
openresty/lualib,可以通过 lua_package_path 设置,特别注意两点:- 使用需要开启 lua_code_cache
- 内存为 worker 独享,虽然会产生多份数据但进程独享比较高效
连接 Redis
lua-resty-redis:https://github.com/openresty/...
local cjson = require "cjson"
local redis = require "resty.redis"
-- register the module prefix "bf" for RedisBloom
redis.register_module_prefix("bf")
local red = redis:new()
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.say("failed to connect: ", err)
return
end
-- call BF.ADD command with the prefix 'bf'
res, err = red:bf():add("dog", 1)
if not res then
ngx.say(err)
return
end
ngx.say("receive: ", cjson.encode(res))
-- call BF.EXISTS command
res, err = red:bf():exists("dog")
if not res then
ngx.say(err)
return
end
ngx.say("receive: ", cjson.encode(res))连接 MySQL
lua-resty-mysql: https://github.com/openresty/...
local cjson = require "cjson"
local mysql = require "resty.mysql"
local db = mysql:new()
local ok, err, errcode, sqlstate = db:connect({
host = "127.0.0.1",
port = 3306,
database = "world",
user = "monty",
password = "pass"})
if not ok then
ngx.log(ngx.ERR, "failed to connect: ", err, ": ", errcode, " ", sqlstate)
return ngx.exit(500)
end
res, err, errcode, sqlstate = db:query("select 1; select 2; select 3;")
if not res then
ngx.log(ngx.ERR, "bad result #1: ", err, ": ", errcode, ": ", sqlstate, ".")
return ngx.exit(500)
end
ngx.say("result #1: ", cjson.encode(res))
local i = 2
while err == "again" do
res, err, errcode, sqlstate = db:read_result()
if not res then
ngx.log(ngx.ERR, "bad result #", i, ": ", err, ": ", errcode, ": ", sqlstate, ".")
return ngx.exit(500)
end
ngx.say("result #", i, ": ", cjson.encode(res))
i = i + 1
end
local ok, err = db:set_keepalive(10000, 50)
if not ok then
ngx.log(ngx.ERR, "failed to set keepalive: ", err)
ngx.exit(500)
end使用模板引擎
lua-resty-template:https://github.com/bungle/lua...
安装模板时只需要将 lib 复制到 lualib 中即可
local template = require "resty.template"
template.render("include.html", {
users = {{
name = "Jane",
age = 29
}, {
name = "John",
age = 25
}}
})
模板路径配置
set $template_root /usr/local/openresty/nginx/templates;在测试阶段我们可以关闭模板进行缓存,但生产上要将他开启
template.caching(false)模板如下
include.html
{% for _, user in ipairs(users) do %}
{(user.html, user)}
{% end %}
user.html
User {{name}} is of age {{age}} 更多的模板语法可以在工作中使用到了再关注。
更多复杂功能
基于 Lua 脚本 + openresty 的开源项目有 Kong、APISX、WAF 等,比如 Kong 预设了很多流量控制、请求修改等 lua 脚本,也支持自定义,lua 脚本可以作为插件进行热插拔。比如我们的一些鉴权操作(对接公司的 SSO 等)可以使用 lua 高效完成。
WAF,软防火墙
API 网关:
灰度发布:
- ABTestingGateway:https://github.com/CNSRE/ABTe...
以上就是 Nginx 实战的所有内容,后面会补上理论,敬请期待!