C语言学习入门之函数7000字超详解【下】
目录
- 1. 函数的嵌套调用和链式访问
-
- 1.1 嵌套调用
- 1.2 链式访问
- 2. 函数的声明和定义
-
- 2.1函数声明:
- 2.2函数定义:
- 3. 函数递归
-
- 3.1 什么是递归?
- 3.2 递归的必要两个条件
- 3.2.1 练习1:
- 3.2.2 练习2:
- 4. 递归与迭代
-
- 4.1练习:
- 4.2练习:
1. 函数的嵌套调用和链式访问
函数和函数之间可以根据实际的需求进行组合的,也就是互相调用的
1.1 嵌套调用
代码演示:
#define _CRT_SECURE_NO_WARNINGS
#include
注意:函数可以嵌套调用,但是不能嵌套定义,每个函数地位都是相等的,并列的关系
1.2 链式访问
把一个函数的返回值作为另外一个函数的参数
链式访问的条件:函数必须有返回值
代码演示:
#define _CRT_SECURE_NO_WARNINGS
#include运行结果:

分析:
printf函数的返回值是打印的字符的个数
2. 函数的声明和定义
2.1函数声明:
写一个加法函数:
#define _CRT_SECURE_NO_WARNINGS
#include如果不进行函数声明,程序可以编译运行,但是会出现警告
注意:1. 函数声明是告诉编译器有一个函数叫什么,参数是什么,返回类型是什么。但是具体是不是存在,函数声明决定不了
2. 函数的声明一般出现在函数的使用之前。要满足先声明后使用
3. 函数的声明一般要放在头文件中的
![]()
2.2函数定义:
函数的定义是指函数的具体实现,交待函数的功能实现
举个栗子:
实现一个计算器
1,加法——A程序猿
add.h add.c
2,减法——B程序猿
sub.h sub.c
3,乘法——C程序猿
mul.h mul.c
4,除法——D程序猿
div.h div.c
代码演示:
add.h
#pragma once
//防止头文件被重复包含
int Add(int x, int y);//函数的声明
add.c
#define _CRT_SECURE_NO_WARNINGS
int Add(int x, int y)
{
return x + y;
}
sub.h
#pragma once
int Sub(int x, int y);
sub.c
#define _CRT_SECURE_NO_WARNINGS
int Sub(int x, int y)
{
return x - y;
}
test.c
#define _CRT_SECURE_NO_WARNINGS
#include包含头文件的本质是将头文件的内容全部拷贝过来
在初学编程时,我们习惯把所有的代码都写到一个文件中,但是在公司中要考虑分工协作问题,模块化设计
再举个栗子:
公司B想完成一个加法功能test.c,但是他不会,程序猿A写了一个程序可以完成这个任务并且卖给B公司,后期代码的维护维修也是A来完成。为了防止公司复刻源代码,程序猿A将 add.c 编译成静态库文件add.lib,然后将头文件add.h提供给B公司,B公司就知道怎样使用,功能的实现是在add.lib中实现的,add.lib文件都是一些乱码了,无法看懂,这样就在一定程度上保护了源文件
我们看一下怎样将add.c文件编译成静态库:
add>右击鼠标>属性

配置属性>常规>配置类型>静态库(.lib)
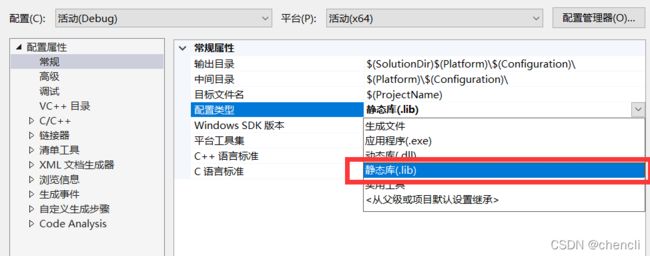
add.c配置完成后会生成add.lib,它是无法直接执行的,所以会报错

将
add.h和add.lib交给B公司

代码演示:
#define _CRT_SECURE_NO_WARNINGS
#include注意:B公司买
add.lib回来之后要导入静态库文件才能使用
#pragma comment(lib,"add.lib")
add.lib在vs中打开是这个样子的:

此时,
add.c所实现的功能都在add.lib中,B公司是看不到add.c的真是实现的
如果我们将函数的声明和定义放在一起,就不能单独剥离出来让别人使用了
3. 函数递归
3.1 什么是递归?
程序调用自身的编程技巧称为递归( recursion)
递归做为一种算法在程序设计语言中广泛应用。一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量
递归的主要思考方式在于:把大事化小
3.2 递归的必要两个条件
1.存在限制条件,当满足这个限制条件的时候,递归便不再继续
2.每次递归调用之后越来越接近这个限制条件
3.2.1 练习1:
接受一个整型值(无符号),按照顺序打印它的每一位 。例如:输入:1234 输出 1 2 3 4
代码演示:
#define _CRT_SECURE_NO_WARNINGS
#include运行结果:
![]()
图解:
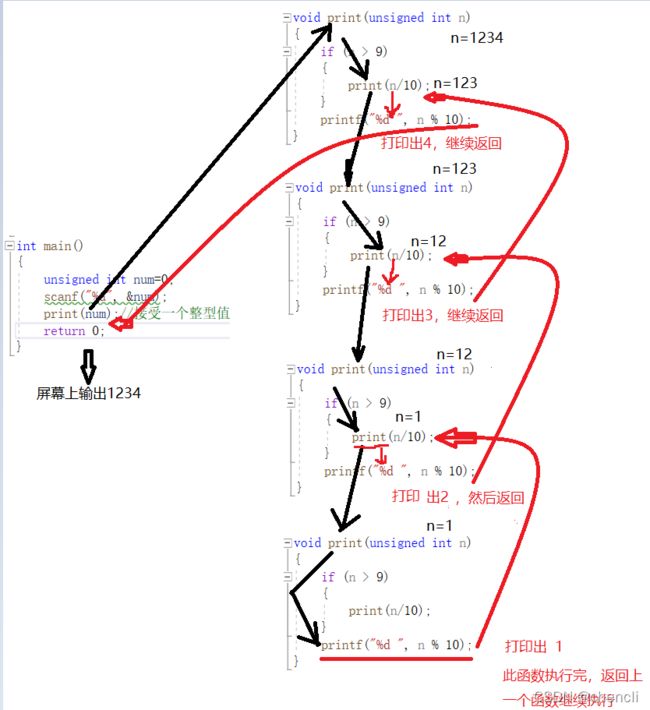
注意:1. 存在限制条件,当满足这个限制条件的时候,递归便不再继续,没有限制条件会出现死递归
2. 每次递归调用之后越来越接近这个限制条件
3.2.2 练习2:
编写函数不允许创建临时变量,求字符串的长度
也就是让我们模拟strlen函数功能功能
代码演示:创建了临时变量count来计数
#define _CRT_SECURE_NO_WARNINGS
//模拟实现strlen
#include不允许创建临时变量,我们考虑用 递归
递归求解:我们求’abc\0’的长度,如果第一个字符不是’\0’,那我们就可以求1+’bc\0‘的长度,即:第一个字符不是’\0’,就可以拆开
my_strlen(“abc”)
1+my_strlen(“bc”)
1+1+my_strlen(“c”)
1+1+1+my_strlen(" ")
1+1+1+0
代码演示:
#define _CRT_SECURE_NO_WARNINGS
#include图解:

4. 递归与迭代
4.1练习:
求n的阶乘。(不考虑溢出)
代码演示:
#define _CRT_SECURE_NO_WARNINGS
#include4.2练习:
求第n个斐波那契数。(不考虑溢出)
递归解决代码演示:
#define _CRT_SECURE_NO_WARNINGS
#include运行结果:

分析:使用递归会重复大量的运算,求第40个斐波那契数的时候,第3个斐波那契数就被重复了39088169次,效率很低,不推荐用递归解决
那如何解决上述的问题?
- 将递归改写成非递归
- 使用static对象替代nonstatic局部对象。在递归函数设计中,可以使用static对象替代nonstatic局部对象(即栈对象),这不仅可以减少每次递归调用和返回时产生和释放nonstatic对象的开销,而且static对象还可以保存递归调用的中间状态,并且可为各个调用层所访问
迭代解决代码演示:
#define _CRT_SECURE_NO_WARNINGS
#include分析:1. 许多问题是以递归的形式进行解释的,这只是因为它比非递归的形式更为清晰
2. 但是这些问题的迭代实现往往比递归实现效率更高,虽然代码的可读性稍微差些
3. 当一个问题相当复杂,难以用迭代实现时,此时递归实现的简洁性便可以补偿它所带来的运行时开销