mysql多字段修改update_MySQL进阶三板斧(三)看清“触发器 (Trigger)”的真实面目...
触发器(Trigger)的起源
- MySQL是最受欢迎的开源RDBMS,被社区和企业广泛使用。触发器是MySQL在5.0.1(开天辟地一版本)中增加的三大新功能之一,另外两个师兄弟是视图(view)与存储过程(procedure)。均属于相对“高级”一点的数据库必需功能。
一、什么是触发器
触发器(trigger):监视某种情况,并触发执行某种操作。触发器是在表中数据发生更改时自动触发执行的,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,例如当对一个表进行操作(insert,delete, update)时就会激活它执行。也就是说触发器只执行DML事件(insert、update和delete)
MySQL触发器的作用
1. 安全性。可以基于数据库的值使用户具有操作数据库的某种权利。
- 可以基于时间限制用户的操作,例如不允许下班后和节假日修改数据库数据。
- 可以基于数据库中的数据限制用户的操作,例如不允许股票的价格的升幅一次超过10%。
2. 审计。可以跟踪用户对数据库的操作。
- 审计用户操作数据库的语句。
- 把用户对数据库的更新写入审计表。
3. 实现复杂的数据完整性规则
- 实现非标准的数据完整性检查和约束。触发器可产生比规则更为复杂的限制。与规则不同,触发器可以引用列或数据库对象。例如,触发器可回退任何企图吃进超过自己保证金的期货。
- 提供可变的缺省值。
4.实现复杂的非标准的数据库相关完整性规则。触发器可以对数据库中相关的表进行连环更新。
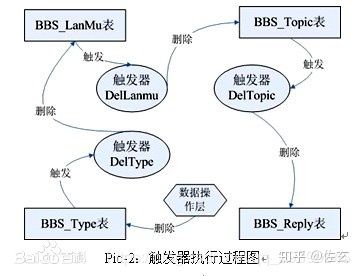
例如,在auths表author_code列上的删除触发器可导致相应删除在其它表中的与之匹配的行。
- 在修改或删除时级联修改或删除其它表中的与之匹配的行。
- 在修改或删除时把其它表中的与之匹配的行设成NULL值。
- 在修改或删除时把其它表中的与之匹配的行级联设成缺省值。
- 触发器能够拒绝或回退那些破坏相关完整性的变化,取消试图进行数据更新的事务。当插入一个与其主健不匹配的外部键时,这种触发器会起作用。例如,可以在books.author_code 列上生成一个插入触发器,如果新值与auths.author_code列中的某值不匹配时,插入被回退。
5. 同步实时地复制表中的数据。
6. 自动计算数据值,如果数据的值达到了一定的要求,则进行特定的处理。例如,如果公司的帐号上的资金低于5万元则立即给财务人员发送警告数据。
二、触发器语法
1. 创建语法四要素
- 监视地点(table)
- 监视事件(insert | update | delete)
- 触发时间(after | before)
- 触发事件(insert | update | delete)
2. 语法公式
CREATE 3. 语法参数说明
1.CREATE TRIGGER
2.{ BEFORE | AFTER } --- 触发器触发时间设置:可以设置为事件发生前或后(前:一般用于校验;后:一般用于关联)。
3.{ INSERT | UPDATE | DELETE } -- 设定触发事件:如执行insert、update或delete的过程时激活触发器。
4.ON
5.FOR EACH ROW --- 触发器的执行间隔(必有的公式内容):FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次。
6.<触发的SQL语句> --- 触发器包含所要触发的SQL语句:这里的语句可以是任何合法的语句, 包括复合语句,但是这里的语句受的限制和函数的一样。当然,触发SQL中可以调用“触发了( INSERT | UPDATE | DELETE )触发器的那一行数据”。
例如下方代码:
create 4. NEW 与 OLD关键字详解
MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据,来引用触发器中发生变化的记录内容,具体地:
① 在INSERT型触发器中,NEW用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
② 在UPDATE型触发器中,OLD用来表示将要或已经被修改的原数据,NEW用来表示将要或已经修改为的新数据;
③ 在DELETE型触发器中,OLD用来表示将要或已经被删除的原数据;
另外,原则上请编写简单高效的触发执行语句,以免悄无声息的浪费过多资源你还不知道!
三、实际应用
1. 数据准备
想我初三时常年倒数,成绩稳定,因此我拿当时几位老友排名数据来纪念一波(手动挠头)。给大家提供一个测试数据;
(沿用的前两篇“视图”、“存储过程”博文中的数据)
a.学生表
CREATE #插入数据:
INSERT #插入结果:

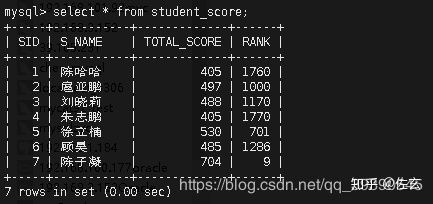
b.成绩表
CREATE #插入数据:
INSERT #插入结果:
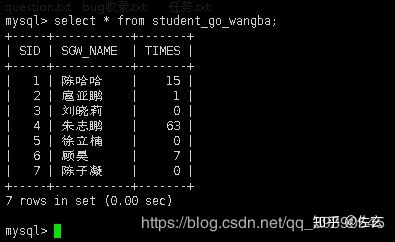
c.逃课上网表
CREATE #插入数据:
INSERT #插入结果:
2. 使用案例
# Insert触发器 - 级联插入
表数据:以上面的三张表为例;学生表(student)、学生成绩表(student_score)、逃课上网次数表(student_go_wangba),均已学号(stuid)为主键。
需求:
- 需要设计一个触发器A,当增加新的学生时,需要在成绩表(student_score)中插入对应的学生信息,至于“分值、排名”字段为0即可;后面由老师打分更新。
- 需要设计一个触发器B,当增加新的学生成绩信息时,需要在逃课上网表(student_go_wangba)中插入对应的学生信息,至于“逃课上网次数”字段为0即可;后面由教导主任“小平头”去更新。(该触发器意义在于:测试after insert链式反应是否支持)
那么,如何设计触发器A呢?
- 首先它是一个插入Insert触发器,是建立在表student上的;
- 然后是after,插入后的事件;
- 事件内容是插入成绩表,需要插入学生的学号和姓名,number为自增,而“分值、排名”目前不需要。
- 注意:new表示student中新插入的值
触发器A:
-- 触发器B:
-- 查询一下我的触发器:
show 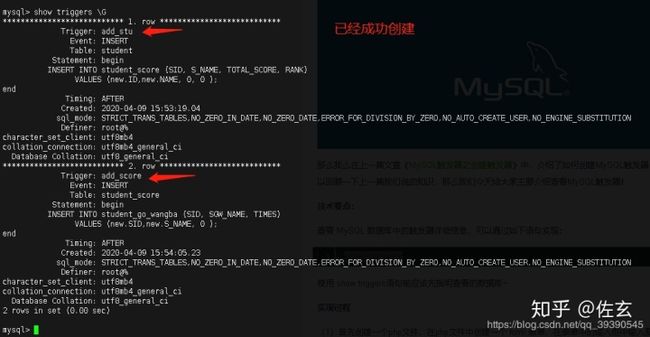
如果在Navicat中就不用 G,直接"show triggers;"就可以。
show 
执行触发器,向student表中加入一条数据:
INSERT 结果如下图所示:
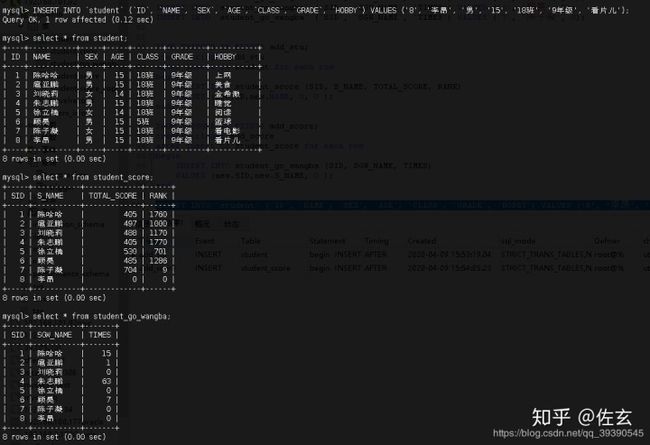
同时插入三个数据,两个触发器正确执行了~
注意:创建触发器和表一样,建议增加判断:DROP TRIGGER IF EXISTS `add_stu`;
# Delete触发器 - 级联删除
表数据:以上面的三张表为例;学生表(student)、学生成绩表(student_score)、逃课上网次数表(student_go_wangba),均已学号(stuid)为主键。
需求:有些老是逃课上网的学生被开除,需要删掉所有信息,以免给学校抹黑~~~
- 需要设计一个触发器C,当删除新的学生时,需要在成绩表(student_score)中删除对应的学生信息。
- 需要设计一个触发器D,当删除新的学生成绩信息时,需要在逃课上网表(student_go_wangba)中删除对应的学生信息。(该触发器意义在于:测试after delete链式反应是否支持)
那么,如何设计触发器C呢?
- 首先它是一个插入delete触发器,是建立在表student上的;
- 然后是after,插入后的事件;
- 事件内容是关联删除成绩表数据,需要删除学生的学号即可。
- 注意:old表示student中新删除的值。
触发器C:
-- 触发器D:
-- 查询一下我的触发器(show triggers G):
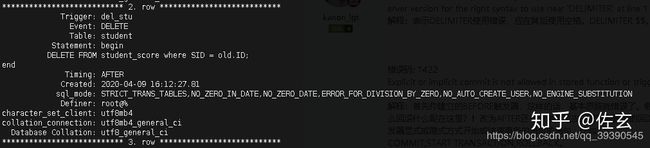
执行触发器,从student表中删除一条数据:
DELETE 结果如下图所示:
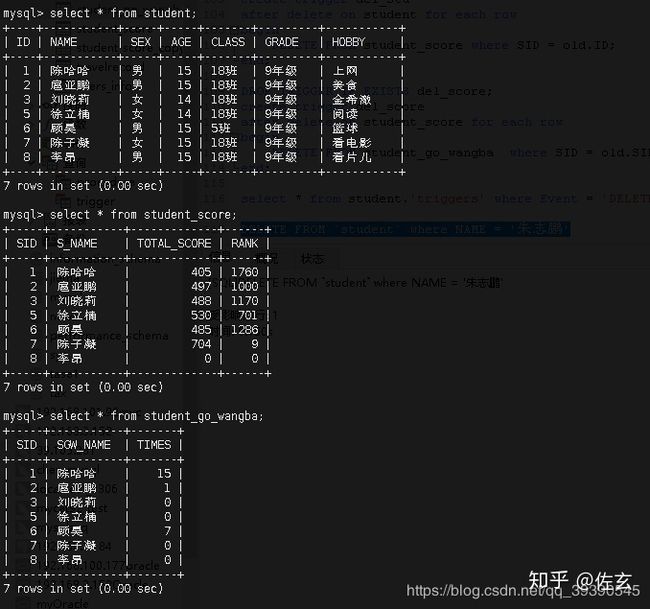
同时删除三个数据,触发器正确执行了。朱志鹏同学数据已经木得了~
注意:创建触发器和表一样,建议增加判断:DROP TRIGGER IF EXISTS `del_stu`;
# Update触发器 - 实时更新
跟Insert触发器、Delete触发器同理,这里不再赘述
四、触发器有哪些缺陷 @江湖中人

下面通过参考知乎、CSDN论坛、天涯社区,简单讲解几个内容供大家参考:
问题一: 触发器有哪些限制和注意事项
回答:
触发器会有以下两种限制:
1.触发程序不能调用将数据返回客户端的存储程序,也不能使用采用CALL语句的动态SQL语句,但是允许存储程序通过参数将数据返回触发程序,也就是存储过程或者函数通过OUT或者INOUT类型的参数将数据返回触发器是可以的,但是不能调用直接返回数据的过程。
2.不能再触发器中使用以显示或隐式方式开始或结束事务的语句,如START TRANS-ACTION,COMMIT或ROLLBACK。
注意事项:
MySQL的触发器是按照BEFORE触发器、行操作、AFTER触发器的顺序执行的,其中任何一步发生错误都不会继续执行剩下的操作,如果对事务表进行的操作,如果出现错误,那么将会被回滚,如果是对非事务表进行操作,那么就无法回滚了,数据可能会出错。
问题二: 大型系统必须得要存储过程和触发器吗?
回答1:
我们先要弄清楚二个问题:
- 什么是大型系统?
- 你讨论的是什么领域的应用,可以大致分为二种:互联网、企业内部
接下来给你举一些例子:
- SAP、peopleSoft、ERP等企业级别应用
一般情况下,会使用存储过程和触发器,减少开发成本,毕竟其业务逻辑修改频繁,而且为通用,很多时候会把一些业务逻辑编写成存储过程,像Oracle会写成包,比存储过程更强大。
另外一个原因是服务器的负载是可控,也即系统的访问人数首先是可控的,没有那么大,而且这些数据又非常关键,为此往往使用的设备也比较好,多用存储柜子支撑数据库。
- 另外一类互联网行业的
比如淘宝、知乎、微博等,数据库的压力是非常大的,也往往会最容易成为瓶颈,而且多用PC服务器支撑,用户量的增速是不可控的,同时在线访问的用户量也是不可控的,为此肯定会把业务逻辑放到其他语言的代码层,而且可以借助一些LVS等类型软硬件做负载均衡,以及平滑增减Web层的服务器,从而达到线性的增减而支持大规模的访问。
所以不管你的这个系统是否庞大,首先要分业务支持的对象,系统最可能容易出现瓶颈的地方在那?
当然也不是说互联网行业的应用就绝对不用存储过程,这个也不对,曾在阿里做的Oracle迁移MySQL系统确实用了,因为历史的原因,另外还有一些新系统也有用,比如晚上进行定期的数据统计的一些操作,不过有量上的控制。存储过程是好东西,要分场景,分业务类型来用就可以把握好。

回答2:
- 肯定不能一刀切的说能用或者不能用,不同类型的系统、不同的规模、不同的历史原因都会有不同的解决方案。
- 一般情况下,Web应用的瓶颈常在DB上,所以会尽可能的减少DB做的事情,把耗时的服务做成Scale Out,这种情况下,肯定不会使用存储过程;而如果只是一般的应用,DB没有性能上的问题,在适当的场景下,也可以使用存储过程。
- 至于触发器,我是知道有这东西但从来没用过。我希望风险可控,遇到问题能够快速的找到原因,尽可能不会去使用触发器。
回答3:
1.PLSQL可以大大降低parse/exec 百分比;
2.存储过程可以自动完成静态SQL variable bind;
3.存储过程大大减少了JDBC网络传输与交互,速度快;
4.oracle 中存储过程内部commit为异步写,一定程度上减少了等redo日志落地时间;
5.存储过程最大问题就是给数据库开发工作压力太大,另外架构升级时候会比较难解耦;
6.触发器不推荐使用,触发操作能在业务层解决就在业务层解决,否则很难维护,而且容易产生死锁。
问题三: 为什么大家都不推荐使用MySQL触发器而用存储过程?
回答1:
1.存储过程和触发器二者是有很大的联系的,我的一般理解就是触发器是一个隐藏的存储过程,因为它不需要参数,不需要显示调用,往往在你不知情的情况下已经做了很多操作。从这个角度来说,由于是隐藏的,无形中增加了系统的复杂性,非DBA人员理解起来数据库就会有困难,因为它不执行根本感觉不到它的存在。
2.再有,涉及到复杂的逻辑的时候,触发器的嵌套是避免不了的,如果再涉及几个存储过程,再加上事务等等,很容易出现死锁现象,再调试的时候也会经常性的从一个触发器转到另外一个,级联关系的不断追溯,很容易使人头大。其实,从性能上,触发器并没有提升多少性能,只是从代码上来说,可能在coding的时候很容易实现业务,所以我的观点是:摒弃触发器!触发器的功能基本都可以用存储过程来实现。
3.在编码中存储过程显示调用很容易阅读代码,触发器隐式调用容易被忽略。
4.存储过程的致命伤在于移植性,存储过程不能跨库移植,比如事先是在mysql数据库的存储过程,考虑性能要移植到oracle上面那么所有的存储过程都需要被重写一遍。
回答2:
这种东西只有在并发不高的项目,管理系统中用。如果是面向用户的高并发应用,都不要使用。
触发器和存储过程本身难以开发和维护,不能高效移植。
- 触发器完全可以用事务替代。
- 存储过程可以用后端脚本替代。

回答3:
我觉得来自两方面的因素:
1.存储过程需要显式调用,意思是阅读源码的时候你能知道存储过程的存在,而触发器必须在数据库端才能看到,容易被忽略。
2.Mysql的触发器本身不是很好,比如after delete无法链式反应的问题。
我认为性能上其实还是触发器占优势的,但是基于以上原因不受青睐。
五、总结
触发器是基于行触发的,所以删除、新增或者修改操作可能都会激活触发器,所以不要编写过于复杂的触发器,也不要增加过得的触发器,这样会对数据的插入、修改或者删除带来比较严重的影响,同时也会带来可移植性差的后果,所以在设计触发器的时候一定要有所考虑。
触发器是一种特殊的存储过程,它在插入,删除或修改特定表中的数据时触发执行,它比数据库本身标准的功能有更精细和更复杂的数据控制能力。
文章来源:MySQL进阶三板斧(三)看清“触发器 (Trigger)”的真实面目
原文作者:陈哈哈
来源平台:CSDN