【数学建模学习笔记【集训十天】之第九天】
数模学习目录
- Pandas 学习(续)
-
- Pandas Json
-
- json 读取-1
-
-
- 文件准备
- 运行结果如下:
-
- 直接处理 json-2
-
- 运行结果如下:
- json 对象-3
-
- 运行结果如下:
- 内嵌 json-4
-
-
- 文件准备
- 运行结果如下:
-
- json_normalize() 解析-5
-
- 运行结果如下:
- 运行结果如下:
- 读取更复杂的 json-6
-
-
- 文件准备:
- 运行结果如下:
-
- glom 处理 - json-7
-
- 运行结果如下:
- Numpy 学习(续)
-
- Numpy 统计函数
-
- numpy.amin() 和 numpy.amax()
- numpy.ptp()
- numpy.percentile()
- numpy.median()
- Matplotlib 学习(续)
-
- Matplotlib 绘制多图
-
- 1-两图并列
-
- 运行效果如下:
- 2-四图显现:
-
- 运行效果如下:
- 3-创建一些测试数据
-
- 运行效果如下:
- 4-创建一个画像和子图
-
- 运行效果如下:
- 5-创建两个子图
-
- 运行效果如下:
- 6-创建四个子图
-
- 运行效果如下:
- 每日一言:
-
- 持续更新中...
Pandas 学习(续)
Pandas Json
json 读取-1
文件准备
# -*- coding = utf-8 -*-
# @Time : 2022/7/6 10:39
# @Author : lxw_pro
# @File : Pandas Json.py
# @Software : PyCharm
import pandas as pd
df = pd.read_json('lxw.json')
print(df.to_string()) # to_string() 用于返回 DataFrame 类型的数据
运行结果如下:
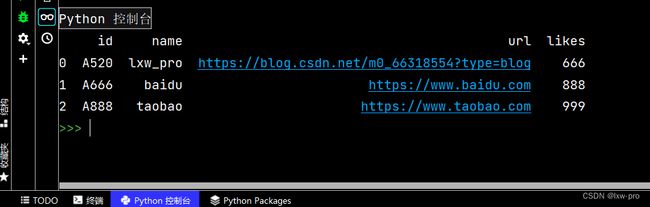
直接处理 json-2
# 直接处理 JSON 字符串
import pandas as pd
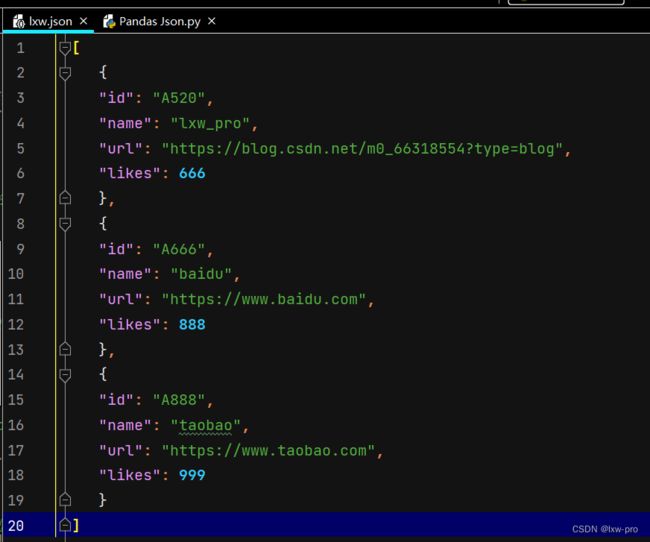
lxw = [
{
"id": "A520",
"name": "lxw_pro",
"url": "https://blog.csdn.net/m0_66318554?type=blog",
"likes": 666
},
{
"id": "A666",
"name": "baidu",
"url": "https://www.baidu.com",
"likes": 888
},
{
"id": "A888",
"name": "taobao",
"url": "https://www.taobao.com",
"likes": 999
}
]
df2 = pd.DataFrame(lxw)
print(df2)
运行结果如下:

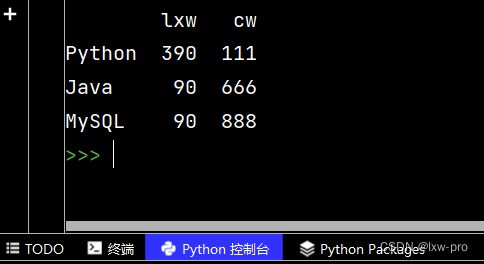
json 对象-3
# JSON 对象与 Python 字典具有相同的格式,可直接将 Python 字典转化为 DataFrame 数据
import pandas as pd
lzd = {
"lxw": {"Python": 390, "Java": 90, "MySQL": 90},
"cw": {"Python": 111, "Java": 666, "MySQL": 888}
}
df3 = pd.DataFrame(lzd)
print(df3)
运行结果如下:
内嵌 json-4
文件准备
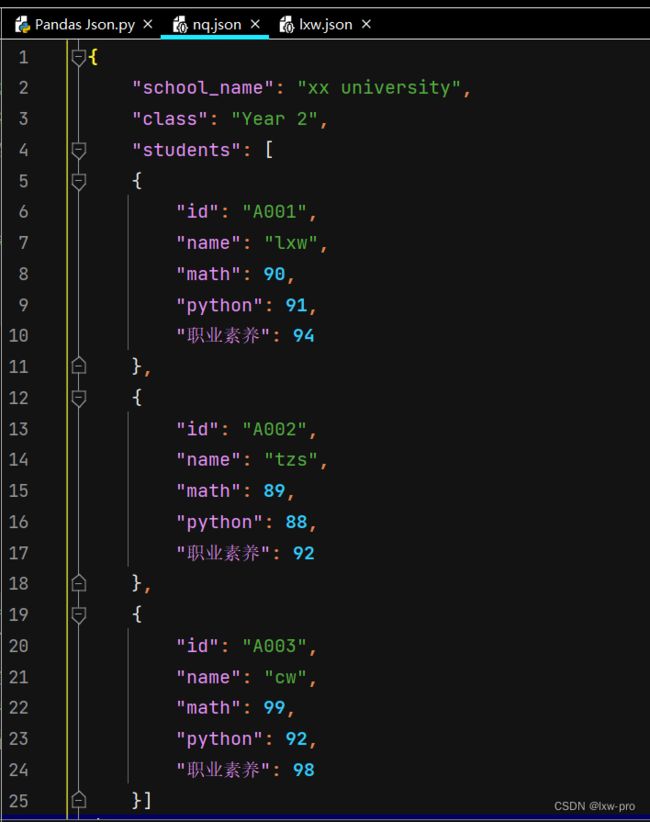
# 内嵌的 JSON 数据
import pandas as pd
df4 = pd.read_json('nq.json')
print(df4)
运行结果如下:

json_normalize() 解析-5
# 须使用到 json_normalize() 方法将内嵌的数据完整的解析出来[爬虫也有类似的解析]
# 部分展出:
import pandas as pd
import json
with open('nq.json', 'r', encoding='UTF-8') as f:
data = json.loads(f.read())
# 铺平数据
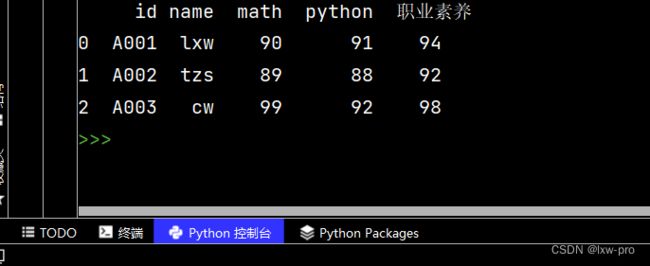
df_list = pd.json_normalize(data, record_path=['students'])
print(df_list)
运行结果如下:
# 全部展出:
import pandas as pd
import json
with open('nq.json', 'r', encoding='utf-8') as fp:
data2 = json.loads(fp.read())
# 铺平数据
df_list2 = pd.json_normalize(
data2,
record_path=['students'],
meta=['school_name', 'class']
)
print(df_list2)
运行结果如下:

读取更复杂的 json-6
文件准备:
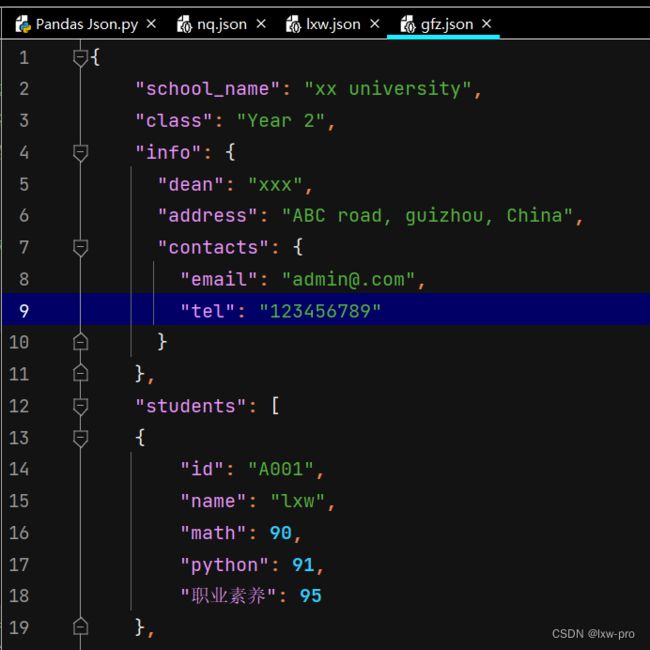

# 读取更复杂的 JSON 数据[该数据嵌套了列表和字典]
import pandas as pd
import json
with open('gfz.json', 'r', encoding='utf-8') as h:
data3 = json.loads(h.read())
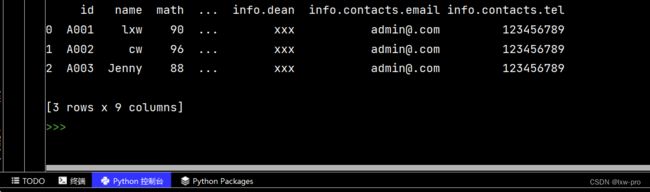
df_list3 = pd.json_normalize(
data3,
record_path=['students'],
meta=[
'class',
['info', 'dean'],
['info', 'contacts', 'email'],
['info', 'contacts', 'tel']
]
)
print(df_list3)
运行结果如下:
glom 处理 - json-7
# 使用到 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性
import pandas as pd
from glom import glom # 注:要写成这种形式的,不然会报错
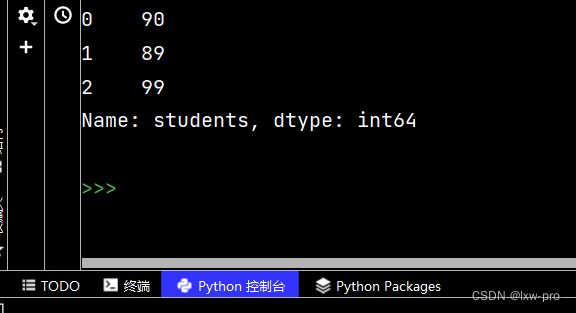
df5 = pd.read_json('nq.json')
data5 = df5['students'].apply(lambda ha: glom(ha, 'math'))
print(data5)
运行结果如下:
————————————————————————————————————————————
Numpy 学习(续)
Numpy 统计函数
numpy.amin() 和 numpy.amax()
# NumPy 统计函数
# NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等
# numpy.amin() 和 numpy.amax()
# numpy.amin() 用于计算数组中的元素沿指定轴的最小值。
#
# numpy.amax() 用于计算数组中的元素沿指定轴的最大值。
import numpy as np
lxw = np.array([
[5, 2, 1],
[9, 2, 6],
[3, 6, 9]])
print(np.amin(lxw, 1)) # 取横行最小
print(np.amin(lxw, axis=1)) # 同上
print(np.amin(lxw, 0)) # 取纵列最小
print(np.amin(lxw)) # 取所有元素当中的最小值
print(np.amax(lxw)) # 取所有元素当中的最大值
print(np.amax(lxw, axis=0)) # 取纵列最大
numpy.ptp()
# numpy.ptp()
# numpy.ptp()函数计算数组中元素最大值与最小值的差(最大值 - 最小值)
import numpy as np
c = np.array([
[3, 6, 8],
[9, 3, 1],
[6, 3, 8]
])
print(np.ptp(c)) # 所有元素的最大值-最小值
print(np.ptp(c, axis=0)) # 纵列最大值-最小值
print(np.ptp(c, axis=1)) # 横行最大值-最小值
numpy.percentile()
# numpy.percentile()
# 百分位数是统计中使用的度量,表示小于这个值的观察值的百分比。 函数numpy.percentile()接受以下参数。
'''
numpy.percentile(a, q, axis)
参数说明:
参数 说明
a 输入数组
q 要计算的百分位数,在 0 ~ 100 之间
axis 沿着它计算百分位数的轴
'''
import numpy as np
bf = np.array([
[3, 6, 1],
[4, 5, 8]
])
print(np.percentile(bf, 50)) # %50的分位数,也就是取其数组中位数
print(np.percentile(bf, 50, axis=0)) # 取纵列中位数
print(np.percentile(bf, 50, axis=1)) # 取横行中位数
print(np.percentile(bf, 50, axis=1, keepdims=True)) # 保持维度不变
numpy.median()
# numpy.median()
# numpy.median() 函数用于计算数组中元素的中位数(中值)
import numpy as np
zw = np.array([
[23, 54, 76],
[12, 45, 34],
[52, 66, 89]
])
print(np.median(zw)) # 取所有元素的中位数
print(np.median(zw, axis=0)) # 取纵列的中位数
print(np.median(zw, axis=1)) # 取横行的中位数
————————————————————————————————————————————
Matplotlib 学习(续)
Matplotlib 绘制多图
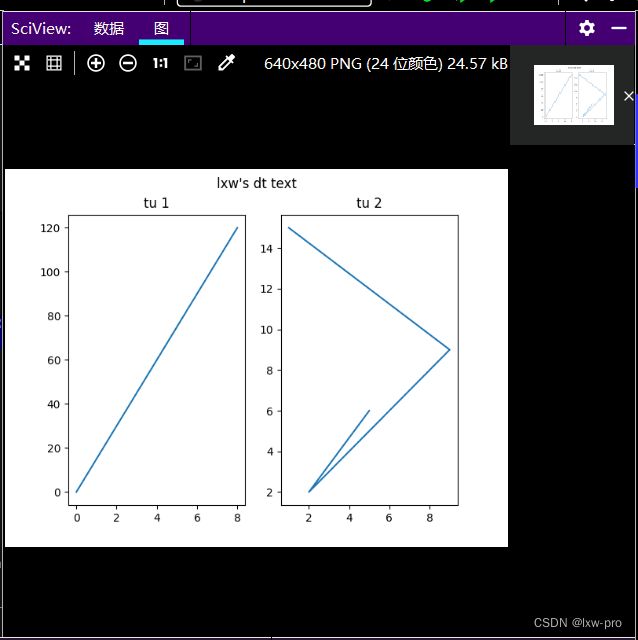
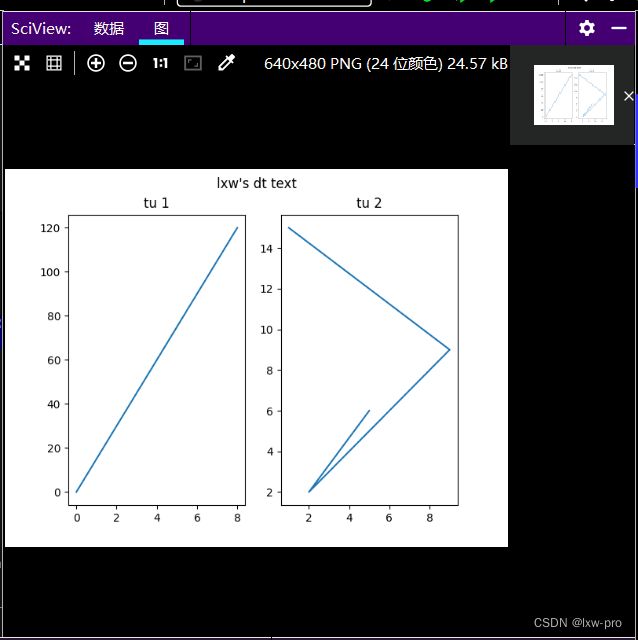
1-两图并列
# -*- coding = utf-8 -*-
# @Time : 2022/7/5 13:30
# @Author : lxw_pro
# @File : Matplotlib 学习-6.py
# @Software : PyCharm
# Matplotlib 绘制多图
# 可使用 pyplot 中的 subplot() 和 subplots() 方法来绘制多个子图。
# subplot() 方法在绘图时需要指定位置
# subplots() 方法可以一次生成多个【在调用时只需要调用生成对象的 ax 即可】
# 两图并列
import matplotlib.pyplot as plt
import numpy as np
# tu 1:
xh = np.array([0, 8])
yh = np.array([0, 120])
plt.subplot(1, 2, 1)
plt.plot(xh, yh)
plt.title('tu 1')
# tu 2:
xh2 = np.array([5, 2, 9, 1])
yh2 = np.array([6, 2, 9, 15])
plt.subplot(1, 2, 2)
plt.plot(xh2, yh2)
plt.title('tu 2')
plt.suptitle("lxw's dt text")
plt.show()
运行效果如下:
2-四图显现:
# 四图显现:
import matplotlib.pyplot as plt
import numpy as np
# tu 1:
tx = np.array([23, 54, 23, 54, 12])
ty = np.array([54, 54, 23, 65, 23])
plt.subplot(2, 2, 1)
plt.plot(tx, ty)
plt.title("tu 1")
# tu 2:
tx2 = np.array([23, 54, 65, 2, 65, 21])
ty2 = np.array([56, 23, 54, 12, 34, 15])
plt.subplot(2, 2, 2)
plt.plot(tx2, ty2)
plt.title('tu 2')
# tu 3:
tx3 = np.arange(7)
ty3 = np.array([1, 3, 5, 6, 4, 2, 9])
plt.subplot(2, 2, 3)
plt.plot(tx3, ty3)
plt.title('tu 3')
# tu 4:
tx4 = np.array([23, 5, 9, 23, 12, 3])
ty4 = np.arange(6)
plt.subplot(2, 2, 4)
plt.plot(tx4, ty4)
plt.title('tu 4')
plt.suptitle("lxw's stxx text")
plt.show()
运行效果如下:
注:下面的四部分代码是一起的,代码打完才能出相对应的效果图
3-创建一些测试数据
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2*np.pi, 400)
y = np.sin(x**2)
plt.plot(x, y)
运行效果如下:

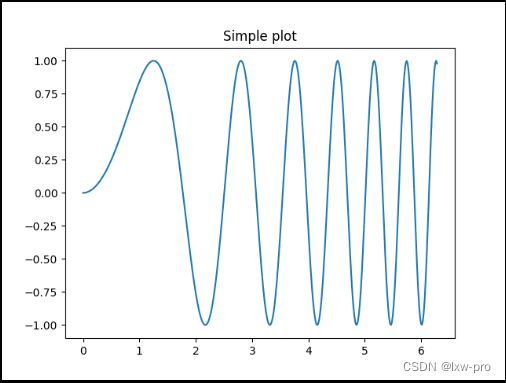
4-创建一个画像和子图
fig, ax = plt.subplots()
ax.plot(x, y)
ax.set_title('Simple plot')
运行效果如下:
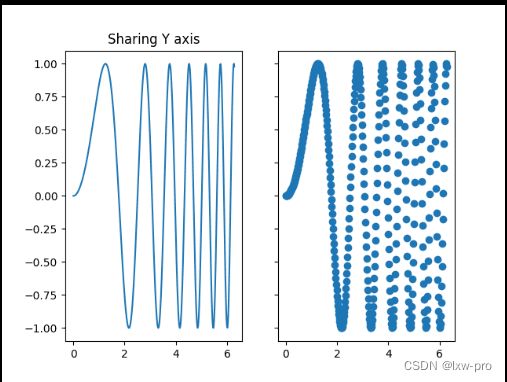
5-创建两个子图
lxw, (ax1, ax2) = plt.subplots(1, 2, sharey=True)
ax1.plot(x, y)
ax1.set_title('Sharing Y axis')
ax2.scatter(x, y)
运行效果如下:
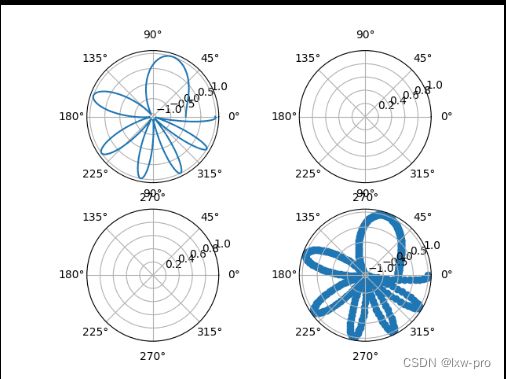
6-创建四个子图
lxw2, axs = plt.subplots(2, 2, subplot_kw=dict(projection="polar"))
axs[0, 0].plot(x, y)
axs[1, 1].scatter(x, y)
plt.show()
运行效果如下:
每日一言:
每天多一点努力,成为自己想要的样子。
持续更新中…
