报文、报文段、数据包、帧、比特、字符、字节,与编码
计算机通信原理
TCP/IP协议簇
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇。TCP/IP协议不仅仅指的是TCP 和IP两个协议,而是指一个由FTP、SMTP、TCP、UDP、IP等协议构成的协议簇, 只是因为在TCP/IP协议中TCP协议和IP协议最具代表性,所以被称为TCP/IP协议。
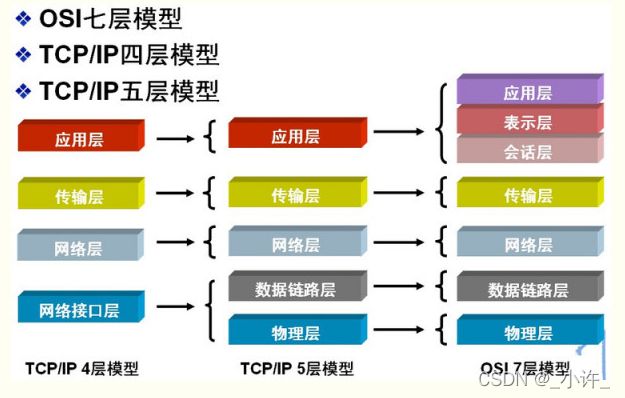
最具代表性的TCP/IP协议簇:
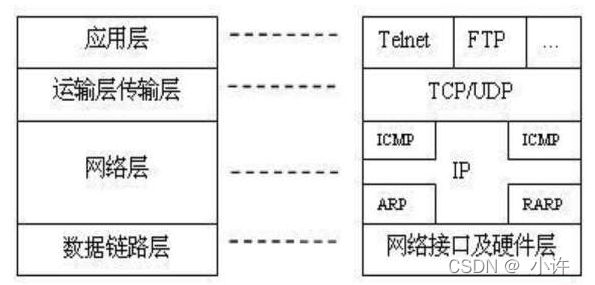
各层传输数据单元:
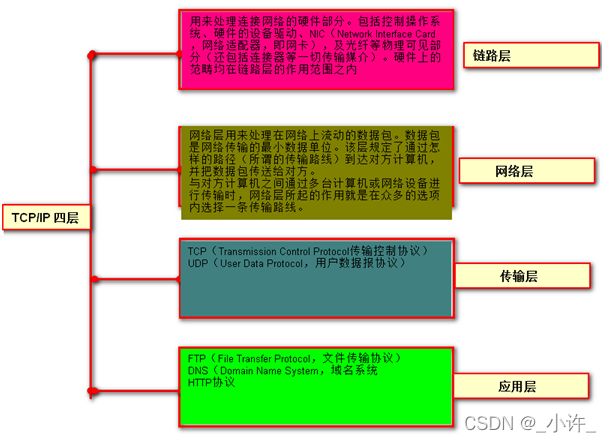
物理层:主要是处理机械的、电气的和过程的接口,以及物理传输介质等,是面向硬件的,传输的基本单元是比特。
数据链路层:对来自网络层的数据进行封装形成数据帧,是传输数据的物理媒。数据帧是数据链路层的传输的基本单元。
网络层:网络层的传输数据的单元式数据包或分组。来自传输层的TCP或UDP报文段到达网络层时也要经过网络层协议的再次封装,网络层为ip协议,该层也定义了IP规范。
传输层:传输层数据传输的单元是报文段,来自应用层的报文到达传输层是由传输层协议再次封装,形成TCP或UDP报文。
应用层:应用层都是以原始的数据传输的,应用层使用不同的协议对数据封装形成报文。如HTTP报文,DNS报文,FTP报文。
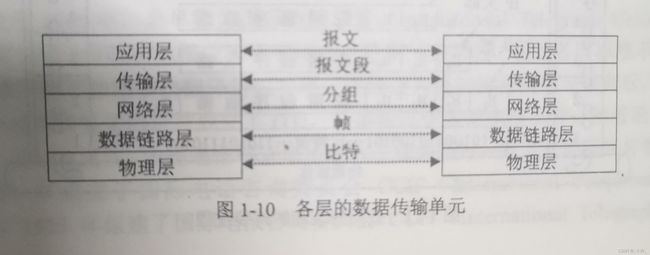
数据封装和解封装
TCP/IP协议簇定义计算机通信的规范。按照这个规范,各个私有计算机就能通过网线或无线网进行连接,并实现数据共享。数据共享对重要的就是封装与解封装的过程。然而TCP/IP协议簇早已定好了规范。面对不同的层级封装为不同的传输单元。
在整个数据传输的过程中,数据在发送端是自上而下逐层传输的,每一层都要进行一次封装,在来自上层的数据加上本层的通信协议的参数信息,在解封装时利用这些参数信息识别正确的数据和解析需要的协议。

如上图所示,只有经过层层封装最终转化为比特流后才能通过电脑在网线上“传输”。
这里的传输并不是真正的传输,并不是像传送带那样传输,真正在网线上传输的是电信号,因为比特流的0,1只是一个标识,在显示中并不存在,不能作为传输单元,而电信号(电频)在现实中是存在的。接收端的计算机也不是接收的比特流,而是电信号,这些电信号是有规律的,接收端电脑通过规律再将电信号转化为比特率。例如传输数据的时间为2秒,传输时间间隔为一秒,则在传输时间2秒内,一次正电平一次负电平为1,先负后正为0,那么根据这个规律,就能构建比特流了。比特流由TCP/IP协议簇中物理层解封装的,再逐层解封装,就能得到原始数据了。按照TCP/IP协议簇封装的数据才能正常解封装。所以TCP/IP协议簇是数据得以传输的基础。
数据传输的单元
报文:应用层传输单元。面向应用,将应用产生的数据封装为报文。主要协议由HTTP(超文本传输协议),FTP(文件传输协议),SMTP(电子邮件传输协议),DNS(域名管理系统)。如Java中,提供了Servlet容器将Java的对象,集合以及基本数据类型的数据封装为报文。
报文段网络层传输单元。对应用层的报文再次封装,定义IP,端口等信息,定义数据发送的目的地。
数据包将网络层的报文段封装,添加IP头部等信息,定义传输的具体细节。
帧:数据包再次封装的结果,面向计算机硬件。
比特流:对帧的进一步封装,成为最终的类型,计算机将比特流转化为规律信号再网线等传输介质上传递。
封装与解封装就是数据在这四种类型直接的转化,同一类型数据必须面向同一层才能被正常解析。物理层,数据链路层,甚至网络层是由计算机自动完成的。传输层,和应用层是由程序完成的。如Java的Socket可以将Java数据封装为一个TCP或UDP报文段,再由计算机封装后接收传输指令就可以传输了。Java的Servlet容器又可以将Java数据封装为HTTP报文,从而发送。包括邮件SMTP,文件FTP报文等。
字节,字符,编码
网络传输的基本单元比特流,比特流对于计算机来说很容易识别,但对于用户来说苦涩难懂。就需要将比特流转为人们可以识别的文字(字符)。
比特流并不是直接转化为字符,而是经过了字节的转化,在编码为字符。
字节(Byte):一个字节占8位(bit),在计算机和网络中是通过二进制字节传递信息的。也就是一个字节由由八位二进制组成。计算机中64位系统就代表了64位的二进制代表一个字,换算成字节就是64/8=8,即是说由8字节构成一个字,32位系统就是32/8=4,4个字节代表一个字。
字符(character):字符是人所能读写的最小单位,例如汉字“我”、字母“A”、符合“+”等,计算机所能支持的字符组成的集合,就叫做字符集。
编码(encode):在计算机和网络中无法直接传递字符,但是可以解析字节,所以需要将字符转化为字节,个解析操作就叫做编码(encode),而相应的,将编码的字节还原成字符的操作就叫做解码(decode)。编码和解码都需要按照一定的规则,这种把字符集中的字符编码为特定的字节的规则就是字符编码(Character encoding)。
字符集
ASCII码
在计算机发展的早期,字符集和字符编码一般使用相同的命名,例如最早的字符集ASCII(American Standard Code for Information Interchange),它既代表了计算机所支持显示的所有字符(字符集),又代表了这个字符集的字符编码。
ASCII字符集是一个二维表,支持128个字符。128个码位,用7位二进制数表示,由于计算机1个字节是8位二进制数,所以最高位为0,即00000000-01111111 或0x00-0x7F。
慢慢地,只支持128个码位的ASCII不能满足我们的需求了,就在原来ASCII的基础上,扩展为256个字符,成为EASCII(Extended ASCII)。EASCII有256个码位,用8位二进制数表示,即00000000-11111111或0x00-0xFF。
ISO-8859
当计算机传到了欧洲,EASCII也开始不能满足需求了,但是改改还能凑合。于是国际标准化组织在ASCII的基础上进行了扩展,形成了ISO-8859标准,跟EASCII类似,兼容ASCII,在高128个码位上有所区别。但是由于欧洲的语言环境十分复杂,所以根据各地区的语言又形成了很多子标准,如ISO-8859-1、ISO-8859-2、ISO-8859-3、……、ISO-8859-16。
所以ISO-8859并不是一个标准,而是一系列标准,它们子标准都以同样的码位对应不同字符集。
GBK
全称叫《汉字内码扩展规范》,是国家技术监督局为 windows95 所制定的新的汉字内码规范,它的出现是为了扩展 GB2312,加入更多的汉字,它的编码范围是 8140~FEFE(去掉 XX7F)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 GB2312 兼容的,也就是说用 GB2312 编码的汉字可以用 GBK 来解码,并且不会有乱码。
Unicode字符编码
后来计算机传入亚洲,由于亚洲语种和文字都十分丰富,256个码位就显得十分鸡肋了。于是继续扩大二维表,单字节改双字节,16位二进制数,65536个码位。在不同国家和地区又出现了很多编码,大陆的GB2312、港台的BIG5、日本的Shift JIS等等。
为了解决传统的字符编码方案的局限,就引入了统一码(Unicode)和通用字符集(Universal Character Set, UCS)来替代原先基于语言的系统。通用字符集的目的是为了能够涵盖世界上所有的字符。Unicode是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
Unicode的编码方式:Unicode使用16位的编码空间也就是每个字符占用2个字节。这样理论上一共最多可以表示2的16次方(即65536)个字符。
Unicode的实现方式:Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式也称为Unicode转换格式(Unicode Transformation Format,简称为UTF),目前主流的实现方式有UTF-16和UTF-8。
UTF-8
UTF-8是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他Unicode字符混合的情况,将按一定算法转换。
UTF-8每个字符使用1-3个字节编码,并利用首位为0或1进行识别。
1、如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
2、如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
3、如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节
UTF-16
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
字节、字符和编码