基于http-flv的抖音直播端到端延迟优化实践
延迟是怎么产生的?
传统直播方案(http-flv、RTMP 等)的架构以及延迟量级如下图所示:

以抖音直播为例,直播链路各环节延迟贡献如下:
-
推流端——网络延迟平均 20 ~ 30ms,编码延迟依赖编码参数设置而定
-
流媒体服务——在拉流转码的场景下,会额外引入 300ms ~ 2s 的转码延迟(大小与转码参数相关),如果直接播放源流,则不存在转码延迟
-
播放端——网络延迟 100ms ~ 200ms 左右,主要是链路分发节点之间的传输延迟;防抖 buffer—— 5 ~ 8s
从各环节延迟贡献看,容易得出一个直观的结论:端到端延迟过大主要是播放器的防抖 buffer 造成,这个表面现象也经常会导致很多同学,认为降低播放器的 buffer,就能降低延迟。这个说法的对错,取决于从什么角度解释。在辩证这个结论前,我们先详细拆解介绍下直播全链路的延迟:

上图主要更细致地拆解了流媒体服务环节,即 CDN 传输链路,拆解为上行(收流节点和上层节点)、源站、下行(上层节点和拉流边缘节点)。各环节延迟归因如下:
主播端(推流器)
主要包含编码延迟以及发送缓存引入的延迟(多数主播网络情况良好,发送缓存延迟平均只有 20 ~ 30ms),这个环节的延迟可优化空间不多,虽然通过调节编码器参数可有效降低编码延迟,但带来的是画质的损失,同时也影响压缩效果,因此多数集中在优化弱网传输(不过出发点是为了提供用户观看流畅体验,而不在于降低延迟)。
收流边缘节点&中间链路
针对 http-flv 不需要分片的协议,CDN 传输各节点都是在收到流数据就直接转发到下一个节点,这个环节主要的延迟是由链路传输引起的,与链路长度正相关,一般平均不超过 200ms。
如果播放端拉转码流,那么在网络传输延迟基础之上,会额外增加转码延迟(目前各大 CDN 厂商编码延迟大概分布在 300ms ~ 2s),包括解码延迟和转码延迟,其中对于无 B 帧的场景,解码延迟较小,主要是编码延迟。编码延迟主要是受编码器缓存帧数影响,假设 FPS=15,那么缓存 6 帧,延迟就 400ms,该部分延迟与推流编码延迟一样,同样可以通过调整转码参数来降低转码延迟,但也同样会带来画质与压缩率的损失,因此这部分延迟需要根据实际场景综合来考虑,如果对延迟要求很高,可以调整下。
拉流边缘节点
不考虑回源的情况,这个环节主要影响延迟的是 gop cache 策略(有的 CDN 厂商也叫做快启 buffer 策略或者快启 cache),即在边缘节点缓存一路流最新的几个 gop(一般媒体时长平均为 5 ~ 7s),目的是为了在拉流请求建立时,可以有媒体数据即时发送,优化首帧和卡顿,这样也就导致了播放端收到的第一帧数据就是 5 ~ 7s 前的旧数据,第一帧的延迟就达到了 5 ~ 7s(这个环节才是端到端延迟过大的根因)。
CDN gopCache 的逻辑
字节与 CDN 厂商沟通约定 gop cache 按照下限优先来下发数据,比如下限 6s,表示先在缓存数据中定位最新 6s 的数据,然后向 6s 前的旧数据查找第一个关键帧下发,保证下发第一帧距离最新帧之间的时长不低于 6s:
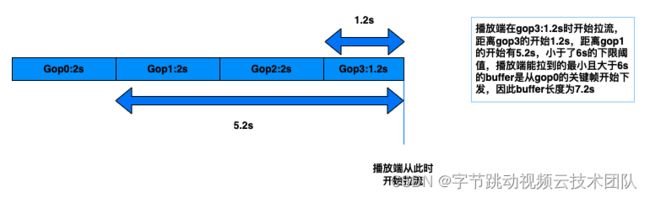
如上图,如果不考虑生产端和中间链路的延迟,那么 buffer 长度 7.2s 可以近似看作播放的初始端到端延迟,在播放器正常播放且无卡顿的前提下,这个延迟会一直持续到退出直播间,不会变化。这里介绍几个初始延迟计算的通用公式:
-
延迟分布区间[M,M+gop]s,
-
平均延迟为 M+gop/2,其中 M 为 gopCache 策略的下限,gop 即为编码 gop 的固定大小值
例如抖音秀场 gop 大小是固定的 2s,假设 gopCache 下限为 6s,那么观众的合理端到端延迟分布区间为:[6, 8]s,根据用户请求的时间点,所有观众的延迟都会均匀分布在这个区间内,因此不同观众间的延迟 diff 最大不超过一个 gop 的长度 2s(这点是优化设备间延迟差的理论基础)
观众(播放器)
播放器在 io 模块有分配缓存 buffer(抖音线上分配 buffer 最大为 20s,也就是最多可容纳 20s 的媒体数据,这个 buffer 其实越大越好,抗网络抖动能力也越强),用于存放从 CDN 边缘节点下载到的流媒体数据。播放器下载是主动下载,在可分配的 buffer 队列未充满的前提下,io 线程是连续下载流媒体数据并存放到 buffer 中,直到没有空闲 buffer 可利用为止。因此,观众网络状况良好的情况下,在用户请求播放,建立链接后,CDN 的边缘节点的快启 buffer,会很快都被下载到播放器的 buffer 中,后续渲染环节消费速度远低于 i/o 下载的速度,这样端到端的延迟就主要分布到了播放器的 buffer 中。但只说明启播后,直播链路的延迟从 CDN 的 gopCache,转移到了播放器,播放器 buffer 并不是延迟的根因,因此,降低播放器的最大缓存 buffer,并不能降低延迟。如果换个角度理解,降低播放器 buffer 中实际缓存的数据,会降低延迟这个说法是正确的,比如通过倍速播放或者丢帧。
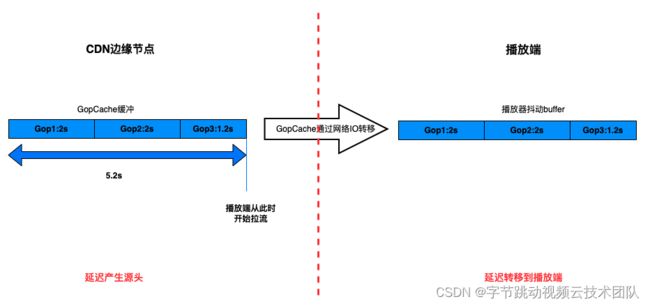
现在了解了全链路延迟是怎么产生的,我们可以确认以下几点:
-
端到端延迟,在 CDN 边缘节点收到 http-get 请求那一刻起,流数据未达到客户端 buffer 前,初始延迟的大小就已经确定了,这个延迟对应于我们的 QoS 指标-首帧延迟
-
影响延迟大小的因素主要有两点:CDN 边缘节点 gop cache 策略(5~7s 延迟)以及视频流 gop 大小(会造成一个 gop 大小的延迟 diff)
-
客户端 buffer 大小与延迟大小之间没有因果关系,buffer 的大小只会影响延迟全链路的分布,但降低播放器 buffer 大小只会降低防抖能力,恶化卡顿,并不会降低延迟
-
较低延迟的有效手段包括:
-
降低 CDN 的 gopCache,是根本手段
-
增加 buffer 中视频数据的消费速度,也可以有效降低延迟,例如倍速播放或者直接丢弃媒体数据
-
在 gopCache 不变的前提下,降低 gop,也可以降低平均端到端延迟,比如 gop=4s 调整为 2s,平均端到端延迟下降 1s
-
为什么要优化延迟?
传统的直播技术延迟非常大,从观众评论到看到主播给出反馈一般要在 5-10 秒以上。几个典型的尴尬场景:
- 单一用户延迟大,导致体验差
在线教育,学生提问,老师都讲到下一个知识点了,再返回来回答。
电商直播,询问宝贝信息,主播“视而不理”。
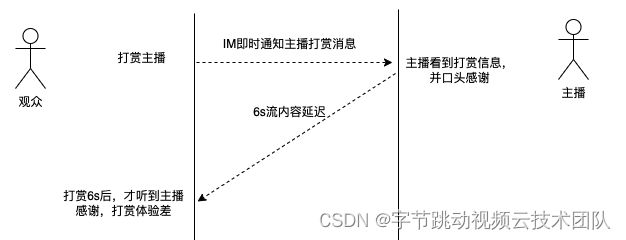
打赏后迟迟听不到主播的口播感谢。
假设端到端延迟为 6s,那么在线教育和电商直播两个场景,互动延迟由面对面的 0s,增加到了 12s,如下图所示:

打赏场景,互动延迟由面对面的 0s,增加到了 6s,如下图所示:
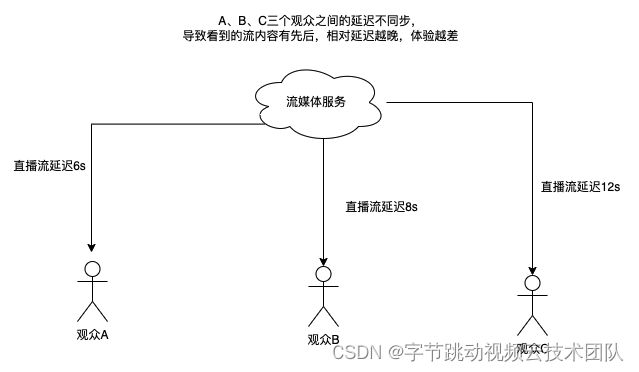
- 不同用户延迟 diff 大,导致体验差
在别人的呐喊声知道球进了,你看的还是直播吗?
这个场景的延迟体验问题,并不是某次拉流请求端到端高延迟导致的,主要是因为不同用户间的延迟不一致导致,如下图:
可见,高延时影响了直播互动体验,阻碍了直播在一些场景的落地,特别在电商直播,直播间的评论提问是观众和主播互动的一个重要手段,主播的实时互动反馈对直播间的活跃度和交易达成至关重要。
以上两类由于延迟导致体验差的场景,分别对应我们 QoS 指标中的平均端到端延迟、延迟设备差两个指标,延迟相关的优化也会以这两个指标为标准。
延迟体验优化实践案例
百万英雄答题
直播流链路
延迟需求
-
所有观众端到端时延在 6s 以内——对应首帧延迟和平均端到端延迟指标
-
不同观众 A,B,C 之间直播流时延差在 2s 以内,避免答题不同步——对应设备延迟差指标
需求分析
-
对于答题类活动直播场景,用户主要集中精力在听题、读题、答题,与主播的互动不是强需求,因此端到端延迟不是优化重点,只要满足需求的 6s 即可
-
用户使用场景多数是面对面或者实时语音组团答题,会对彼此之间延迟不一致的现象很敏感,因此保证设备延迟差尽可能小是核心需求点
解决方案
- 满足时延 6s 以内——调整 gopCache 以及 gop 大小
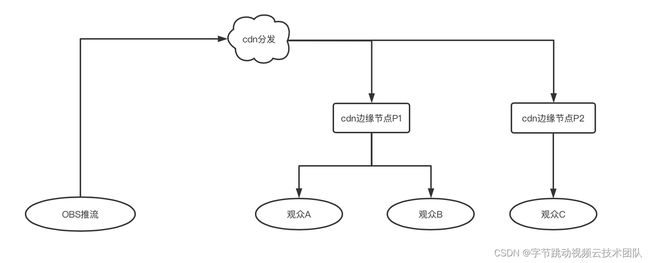
gop=2s,gopCache 下限为 5s,那么首帧延迟分布在[5s, 5+2s]内,平均延迟为(5+(5+2))/2=6s,具体措施如下:
-
各家 CDN 快启策略需要设置为下限优先,并且快启 buffer 阈值为 5s
-
推流参数设置需要设置 gop=2s,且保持稳定:保证观看同一路流的用户,时延 diff 在 2s 内
-
转码配置需要保持 gop=2s 的配置,并且 I 帧对齐:保证观看不同转码流的用户,时延 diff 在 2s 内
- 延迟差在 2s 以内
调整 gop=2s 后,仅能保证一直流畅播放无卡顿的 vv,彼此直接的延迟 diff 在 2s 以内,但对于观播过程中发生卡顿的用户,累计延迟增加的情况,延迟 diff 会越来越大,例如用户 A 卡 4s 后,恢复正常播放,那么 A 的端到端延迟会增加 4s,如果 A,B,C 是一个组队答题的小伙伴,A 的题目解说会一直落后 B 和 C,这样的体验很不好。因此需要针对这类场景的设备延迟差做优化:这时候需要播放器追帧微调,使 A 的播放速度追上 B 和 C。具体措施如下:
-
追帧的原则是:在 A 的播放器 buffer 超过 6s 时,就开始倍速播放,直到 buffer 低于 6s,这时候 A 就追上了 B 和 C
-
追帧阈值 6s,追帧速度是 1.4,这样设置的效果时,A 观众在延迟落后 4s 的情况下,追帧 10s 即可赶上 B 和 C,实际阈值的设置,可以根据需求来确定,原则上是在延迟满足需求时,尽量不触发追帧,保持正常速度播放
效果验收
相对于第一届百万英雄答题,延迟不同步的用户反馈大量减少
4s 低延迟字节内购会
直播流链路
类似于百万英雄
延迟需求
-
所有观众端到端时延在 4s 以内——对应首帧延迟和平均端到端延迟指标
-
不同用户在听到主播说上链接时,与购物链接弹出时间尽量一致——对应设备延迟差指标
需求分析
-
内购会有电商主播带货环节,因此对互动延迟敏感
-
内购会是大型组团抢购活动,员工都在工位面对面参与,因此对设备延迟差也会很敏感
解决方案
- 推流&转码流配置

-
CDN 侧
相对于百万英雄答题场景,内购会对互动延迟敏感,因此这里相对于百万英雄答题需要做特殊配置,由于各家厂商默认 gopCache 策略,平均端到端延迟在 6s 左右,不满足需求的 4s,需要通过配置 url query 参数控制厂商的 gopCache 策略,保证延迟在 4s 左右
-
播放端参数配置详情
-
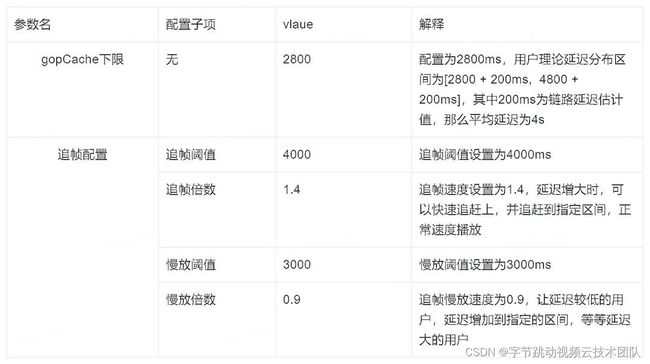
延迟等级:4s
-
参数配置目标:降低不同设备间延迟差,控制用户延迟分布在[3000ms, 4000ms]内,这样保证设备间延迟差最大不超过 1s——延迟低的用户慢放,延迟高的用户追帧,从而更精确的控制设备延迟差低于 gop 长度 2s
-
倒计时确认时机
内购会上链接或者答题,是根据现场助理观播的延迟来确定上链接或者发题的倒计时时机,由于有快慢放对齐设备延迟差的过程,建议助理看播 1min 后,延迟稳定后,再确定倒计时
效果验收
-
线下演练以及正式场不同设备间的流内容延迟,进入观播后通过快慢放调整后,延迟基本都稳定在 4s,且 diff 不超过 1s
-
主播口播“上链接”与实际链接弹出延迟 diff 在 1s 内,抢购体验良好
-
基本无卡顿反馈 case
抖音直播-FLV 低延迟-3s
直播流链路

需求目标
-
平均延迟达到 3s
-
播放时长、看播渗透、留存等核心业务指标显著正向
-
电商 GMV、充值打赏等营收指标显著正向
需求分析
-
传统直播场景,不同观众同一时刻经常观看不同主播的流,且经常是个人独立观播,对同一直播间,不同观众延迟一致的诉求基本不存在,因此延迟设备差不是优化重点指标
-
秀场直播、直播带货等场景,是强互动场景,对互动延迟要求高,本需求核心优化点是端到端延迟
解决方案
本次需求场景的受众是抖音的所有直播用户,网络质量的优劣也是参差不齐的,在保证满足降低延迟的需求目标,我们还需要保证观播的流畅性不要负向太多。
延迟解决方案
-
gop 下调为 2s
-
配置 gopCache 下限参数为 1800ms,延迟区间为[1800+200ms,3800+200ms],平均 3s
卡顿优化方案
1、先验知识科普
-
启播 buffer 策略:表示首帧渲染后,需要等到播放器 audio buffer 达到一定阈值后,再继续播放,这样可以增加网络抗抖能力
-
网络分级 1 ~ 8:
-
8—等效于非常好的 4G 网络;
-
7—等效于较好的 4G 网络;
-
6—等效于一般的 4G 网络;
-
5—等效于较差的 4G 网络;
-
1 ~ 4—网络质量差
-
2、基于网络质量的个性化启播 buffer 策略
-
方案设计基本原理
-
基于网络分级,自适应调整启播 buffer
-
设定启播 buffer 最大调整区间为[0,850ms]
-
不同网络分级映射到不同的启播 buffer 区间
-
随着网络分级的变差,启播 buffer 档位递增速率也加快
-
同一网络分级的不同 vv,根据重试和卡顿次数,在该网络分级的启播 buffer 区间中进行微调
-
随着卡顿次数的增加,启播 buffer 在对应档位区间内的微调幅度逐步下降
-
对于同一次 app 启动周期内,发生多次直播 vv 的情况,需要考虑最近一次直播播放 session 中的卡顿和重试情况,且卡顿和重试的影响权重随着时间衰减
-
-
QoS 收益:卡顿负向降低了 20%
3、基于网络质量的个性化延迟策略
基于数据统计发现:网络分级 1 ~ 4 的 vv 占比为 5.54%,但卡顿指标却贡献了 47.83%,再结合本需求场景设备间延迟差并不是核心指标,因此可通过个性化延迟来优化卡顿。
-
方案设计基本原理
-
基于网络分级,自适应调整延迟
-
不同网络分级映射不同的 gopCache 下限
-
随着网络分级的变差,延迟逐渐增大
-
-
QoS 收益:卡顿负向降低了 30%+
4、客户端管控 CDN 卡顿优化策略
在需求推进过程中发现两个奇怪的现象:
-
在网络质量足够好的场景下进行线下测试,发现低延迟更容易触发 CDN 的丢帧策略(优化卡顿的策略),从而导致渲染卡顿上涨(和 CDN 沟通后,CDN 侧不愿意透露太多的丢帧策略细节,根因无法求证)
-
在 AB 实验过程中,某一家 CDN 厂商上线了过激的丢帧策略,引起了线上大量反馈,从用户反馈看,基本都是反馈刚进入直播间的卡顿,推测用户对启播阶段的丢帧卡顿,更敏感
结合以上两个现象,基本可以判断低延迟情况下,CDN 在启播阶段更容易丢帧,且启播丢帧会严重影响 QoE 体验,因此管控 CDN 丢帧策略,对 QoS(视频渲染卡顿)以及 QoE 都是有正向优化效果的,管控规则如下:
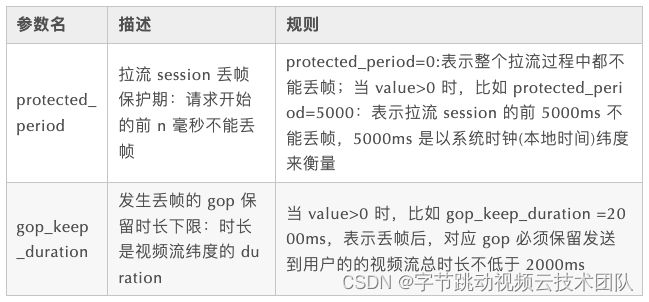
- QoS 收益:FLV 低延迟渲染卡顿负向降低约 30%
最终效果验收
-
QoE 指标收益
-
核心业务指标:直播人均看播时长、看播渗透、留存等显著正向
-
营收相关指标:电商人均支付订单数、付费渗透、充值等显著正向
-
-
Qos 指标
-
端到端延迟:3.24s
-
卡顿:增加 13%
-
-
带宽成本收益
-
由于低延迟降低了 gopCache,延迟下降到 3s,相对于 7s 高延迟 FLV,在启播时会少下载 4s 的数据,尤其抖音直播预览流占比达到 70%,因此低延迟 FLV 可以节省不必要的带宽成本,成本收益为 10%
-
关于延迟的思考
思考一:观众对互动延迟的感知是否存在拐点,延迟降到一定程度,用户感知不到?我们从三个典型的互动场景来思考:
-
观众评论,主播看到评论进行口播回复互动:观众对话框输入评论平均耗时至少 2s 以上,再降低互动延迟是否有收益?
-
观众打赏送礼,主播进行口播感谢互动:假设观众打赏耗时平均 1s 左右,此时打赏后互动延迟 3s 口播感谢,此时的延迟水平是否已经满足观众对主播感谢响应度的需求?
-
直播带货场景:无论“上链接”口播与链接实际弹窗是否一致,还是秒拍场景,核心的延迟指标都是设备间延迟差指标会影响体验,是否实际的端到端延迟其实观众并没有互动延迟敏感?
思考二:在传统标准直播 http-flv 场景下,是否可以依然基于本文中介绍的方法,继续下探更低延迟,比如 1s?个人判断是可以做到的,但面临的挑战也更多,需要更精细的播控策略来平衡延迟与播放流畅性,比如:
-
在 tcp/quic 等传输协议场景,启播时 CDN 侧都存在带宽(最佳的发送速率)探测的算法逻辑,基于实际发送数据探测结合 ACK 等反馈信息来增加发送速率,那么这里就存在一个问题——继续降低 gopCache,满足延迟下降到 1s 的同时,也导致 CDN 用于发送探测的数据量会变少,不足以探测到网络链路实际的带宽,这样会导致 gopCache 阶段平均发送速率会降低,抗网络抖动能力会急剧下降,同时也会影响首帧,因此为进一步下探延迟,需要播放端和 CDN 相互配合优化启播发包速率,这样才能保证流畅性不负向过多
-
更低延迟的场景对延迟的要求也极高,也更容易发生卡顿,但凡发生一次卡顿,延迟就很容易成倍增加,最终导致延迟降不下来,进一步下探延迟也需要配合精细的追帧或者丢帧策略。