mysql 结果集去重_mysql去重, 把url重复且区为空的中去掉、统计重复数据、、结果集去重合并成一行...
delete from 表名 where id not in (select d.id from (SELECT id FROM 表名 GROUP BY c1,c2,c3,c4)as d)
#去重复,把url重复,且区为空的中去掉。
select * from TABLE where
url in
(select u.url from (select * from TABLE where id not in (select d.id from (SELECT id FROM TABLE GROUP BY url)as d)) as u)
and qu like "";
二、删除/去除重复记录
select *, count(distinct name) from table group by name
SELECT shortname,COUNT(*) FROM student GROUP BY shortname HAVING COUNT(*) > 1;
select user_name,count(*) as count from user group by user_name having count>1;
创建临时表:
create table tb2 select c1,c2 from tb1 group by c1,c2;
drop table tb1;
alter table tb2 rename to tb1;
三、统计重复数据:
select c1,c2
from tb1
group by c1,c2
having count(*)>1;
除了GROUP BY 来读取数据表中不重复的数据,使用DISTINCT关键字来过滤。
用distinct:
select distinct c1,c2 from table;
四、防止表中出现重复数据:
在MySQL数据表中设置指定的字段为PRIMARY KEY索引/UNIQUE索引)来保证数据的唯一性。
create table tb1 (
c1 char(16) not null,
c2 char(16) not null,
c3 char(10),
primary key(c1,c2)
)
或者:
create table tb1
(
c1 char(20) not null,
c2 char(20) not null,
c3 char(10),
unique(c1,c2)
)
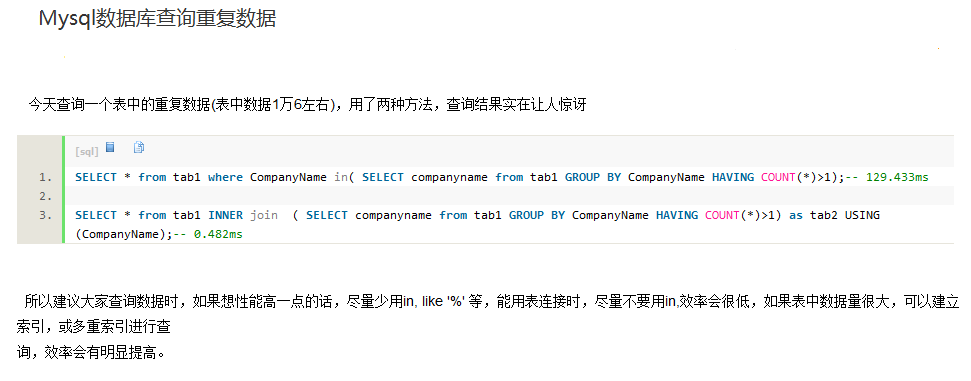
mysql查询表里的重复数据方法
更新时间:2017年05月20日 13:51:47 投稿:mdxy-dxy 我要评论
这篇文章主要介绍了mysql查询表里的重复数据方法,需要的朋友可以参考下


MySQL里查询表里的重复数据记录:
先查看重复的原始数据:
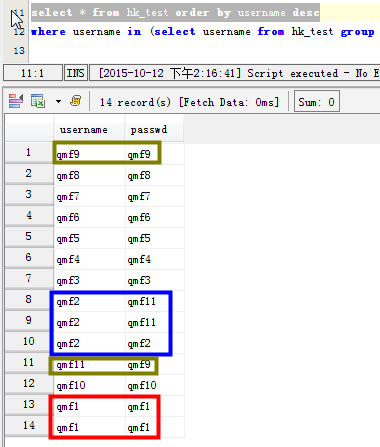
场景一:列出username字段有重读的数据
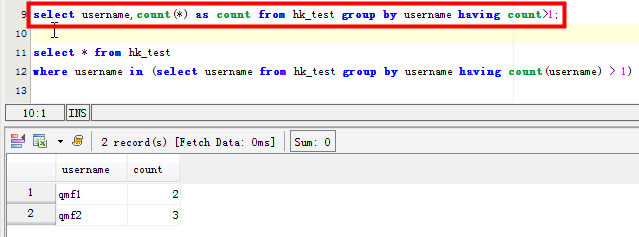
这种方法只是统计了该字段重复对应的具体的个数
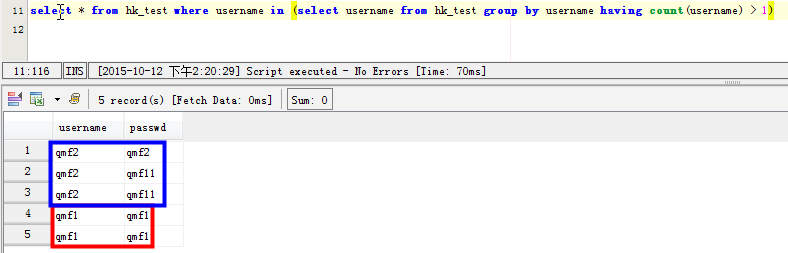
场景二:列出username字段重复记录的具体指:
解决方法:
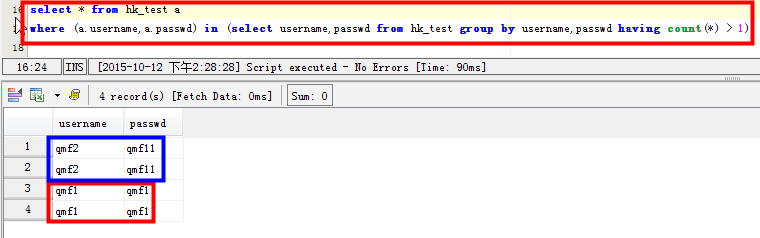
场景三:查看两个字段都重复的记录:比如username和passwd两个字段都有重复的记录:
场景四:查询表中多个字段同时重复的记录:
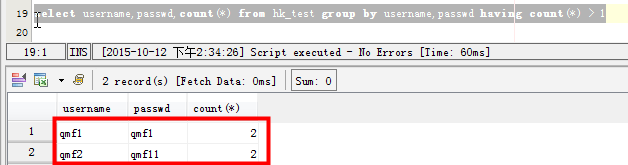
查找mysql数据表中重复记录
mysql数据库中的数据越来越多,当然排除不了重复的数据,在维护数据的时候突然想到要把多余的数据给删减掉,剩下有价值的数据。
以下sql语句可以实现查找出一个表中的所有重复的记录.
select user_name,count(*) as count from user_table group by user_name having count>1;
参数说明:
user_name为要查找的重复字段.
count用来判断大于一的才是重复的.
user_table为要查找的表名.
group by用来分组
having用来过滤.
把参数换成自己数据表的相应字段参数,可以先在Phpmyadmin里面或者Navicat里面去运行,看看有哪些数据重复了,然后在数据库里面删除掉,也可以直接将SQL语句放到后台读取新闻的页面里面读取出来,完善成查询重复数据的列表,有重复的可以直接删除。
效果如下:
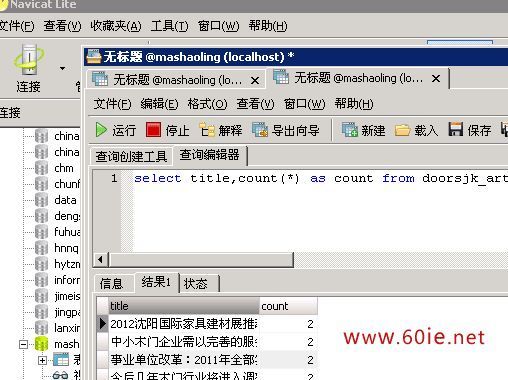
缺点:这种方法的缺点就是当你的数据库里面的数据量很大的时候,效率很低,我用的是Navicat测试的,数据量不大,效率很高,当然,网站还有其它查询数据重复的SQL语句,举一反三,大家好好研究研究,找到一个适合自己网站的查询语句。
MySQL之——查询重复记录、删除重复记录方法大全
查找所有重复标题的记录:
SELECT * FROM t_info a WHERE ((SELECT COUNT(*) FROM t_info WHERE Title = a.Title) > 1) ORDER BY Title DESC
一、查找重复记录
1、查找全部重复记录
Select * From 表 Where 重复字段 In (Select 重复字段 From 表 Group By 重复字段 Having Count(*)>1)
2、过滤重复记录(只显示一条)
Select * From HZT Where ID In (Select Max(ID) From HZT Group By Title)
注:此处显示ID最大一条记录
二、删除重复记录
1、删除全部重复记录(慎用)
Delete 表 Where 重复字段 In (Select 重复字段 From 表 Group By 重复字段 Having Count(*)>1)
2、保留一条(这个应该是大多数人所需要的 ^_^)
Delete HZT Where ID Not In (Select Max(ID) From HZT Group By Title)
注:此处保留ID最大一条记录
三、举例
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1) and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
四、补充
有两个以上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
1、对于第一种重复,比较容易解决,使用
select distinct * from tableName
就可以得到无重复记录的结果集。
如果该表需要删除重复的记录(重复记录保留1条),可以按以下方法删除
select distinct * into #Tmp from tableName
drop table tableName
select * into tableName from #Tmp
drop table #Tmp发生这种重复的原因是表设计不周产生的,增加唯一索引列即可解决。
2、这类重复问题通常要求保留重复记录中的第一条记录,操作方法如下
假设有重复的字段为Name,Address,要求得到这两个字段唯一的结果集
select identity(int,1,1) as autoID, * into #Tmp from tableName
select min(autoID) as autoID into #Tmp2 from #Tmp group by Name,autoID
select * from #Tmp where autoID in(select autoID from #tmp2)
mysql 结果集去重复值并合并成一行
+——+——+
| id| name | tag |
+——+——+
|1 | 10| A
|1 | 20| A
|1 | 20| C
|2 | 20| C
|3 | 200 | B
|3 | 500 | A
+——+——+
以id分组,把name字段的值打印在一行,逗号分隔(默认)
select id,group_concat(name) from student group by id;
以id分组,把name字段的值打印在一行,分号分隔:
select id,group_concat(name separator ’;’) from aa group by id;
以id分组,把去冗余的name字段的值打印在一行,逗号分隔:
select id,group_concat(distinct name) from aa group by id;