语义分割系列2-Unet(pytorch实现)
Unet发布于MICCAI。其论文的名字也说得相对很明白,用于生物医学图像分割。
《U-Net: Convolutional Networks for Biomedical Image Segmentation》
Unet与前文所讲的FCN颇为相似,或者说FCN影响了Unet也影响了之后各类语义分割网络的结构设计。
Unet
网络设计
Unet的网络设计如其名字一般优雅,U型网络。图像数据经过4次下采样,再经过四次上采样恢复到原图大小,同时,每一个上采样层和下采样层之间都有一个跳跃连接(skip connection)。相对FCN来说,这种层层连接的U型架构更加优雅,由于每一次上采样时都融合了对应下采样层的特征,Unet在像素级别的恢复上效果更佳。
而每一层的特征融合后都会经过一系列的卷积层,以此来处理特征图中的细节,让模型学习这些信息来组装一个更精确的输出。
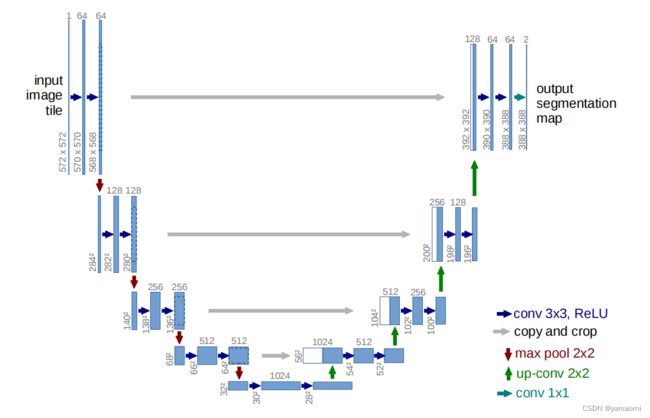 图1 Unet网络结构
图1 Unet网络结构
trick
作者在设计Unet时也加入了一些tricks来帮助模型训练。
 图2 一种重叠的切割策略(Overlap-tile strategy )
图2 一种重叠的切割策略(Overlap-tile strategy )
原作者将这个策略称为Overlap-tile strategy, 该策略允许通过重叠的方法对任意大的图像进行无缝分割(见图2)。为了预测图像边界区域中的像素,通过镜像输入图像来推断缺失的上下文。这种平铺策略对于将网络应用于大型图像很重要。比如,需要预测图中黄色框的信息,就将蓝色框的数据作为输入,如果蓝色框内有一部分信息缺失,就对蓝色框做镜像处理,获得黄色框区域的上下文信息。
至于为什么要这么做,我认为主要有两个原因:
一是,作者在原文中提到的,因为需要输入的图像分辨率过大,对GPU的显存占用比较高,这种通过滑窗的预测方式能够在一定程度上减轻GPU的负担。(毕竟是医学图像嘛,往往对图像分辨率要求较高,强行将图像的分辨率resize到比较低的情况下容易损失一些信息)。
二是,整个Unet的设计中都没有使用padding,因为下采样维度越高,经过越多的卷积层,padding操作越多,越深层的特征图就越容易受到padding的影响,这就导致了图像边缘的损失。但是呢,不使用padding的话,在层层的卷积过程中,图像的分辨率会越来越小,导致最后上采样回去的特征图尺寸和原图不匹配,为了解决这个问题,作者"粗暴"地将原图做一个镜像扩充,这样上采样回去的图像就和原图一样大了。
结果
 图3 Unet 在ISBI cell tracking challenge上的结果
图3 Unet 在ISBI cell tracking challenge上的结果
复现Unet模型
通过pytorch复现一下Unet模型。
导入模块构建模型
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms
from torchvision import models
from tqdm import tqdm
import warnings
import os.path as ospimport torch
import torch.nn as nn
class Unet(nn.Module):
def __init__(self, num_classes):
super(Unet, self).__init__()
self.stage_1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3,padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.stage_2 = nn.Sequential(
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
)
self.stage_3 = nn.Sequential(
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
)
self.stage_4 = nn.Sequential(
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
)
self.stage_5 = nn.Sequential(
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3,padding=1),
nn.BatchNorm2d(1024),
nn.ReLU(),
nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=3,padding=1),
nn.BatchNorm2d(1024),
nn.ReLU(),
)
self.upsample_4 = nn.Sequential(
nn.ConvTranspose2d(in_channels=1024, out_channels=512,kernel_size=4,stride=2, padding=1)
)
self.upsample_3 = nn.Sequential(
nn.ConvTranspose2d(in_channels=512, out_channels=256,kernel_size=4,stride=2, padding=1)
)
self.upsample_2 = nn.Sequential(
nn.ConvTranspose2d(in_channels=256, out_channels=128,kernel_size=4,stride=2, padding=1)
)
self.upsample_1 = nn.Sequential(
nn.ConvTranspose2d(in_channels=128, out_channels=64,kernel_size=4,stride=2, padding=1)
)
self.stage_up_4 = nn.Sequential(
nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.stage_up_3 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.stage_up_2 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.stage_up_1 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.final = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=num_classes, kernel_size=3, padding=1),
)
def forward(self, x):
x = x.float()
#下采样过程
stage_1 = self.stage_1(x)
stage_2 = self.stage_2(stage_1)
stage_3 = self.stage_3(stage_2)
stage_4 = self.stage_4(stage_3)
stage_5 = self.stage_5(stage_4)
#1024->512
up_4 = self.upsample_4(stage_5)
#512+512 -> 512\
up_4_conv = self.stage_up_4(torch.cat([up_4, stage_4], dim=1))
#512 -> 256
up_3 = self.upsample_3(up_4_conv)
#256+256 -> 256
up_3_conv = self.stage_up_3(torch.cat([up_3, stage_3], dim=1))
up_2 = self.upsample_2(up_3_conv)
up_2_conv = self.stage_up_2(torch.cat([up_2, stage_2], dim=1))
up_1 = self.upsample_1(up_2_conv)
up_1_conv = self.stage_up_1(torch.cat([up_1, stage_1], dim=1))
output = self.final(up_1_conv)
return output可以进行一下简单测试
device = torch.device("cuda:0")
model = Unet(num_classes=2)
model = model.to(device)
a = torch.ones([2, 3, 224, 224])
a = a.to(device)
model(a).shape

为了方便,本文构建的模型没有按照Unet论文中的镜像填充和重叠的切割策略,用padding来保证上采样和下采样时特征图大小匹配。所以,输出的大小和原图大小应当相等。
构建Pascal VOC2012数据集
数据集使用了CamVid数据集。
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
import os.path as osp
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'dataset\camvid' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=True,drop_last=True)模型训练
model = Unet(num_classes=33).cuda()
#model.load_state_dict(torch.load(r"checkpoints/Unet_50.pth"), strict=False)from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
#损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
#选用adam优化器来训练
optimizer = optim.SGD(model.parameters(),lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.1, last_epoch=-1)
#训练50轮
epochs_num = 100
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,scheduler,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(
net, features, labels.long(), loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
scheduler.step()
# print(f'loss {metric[0] / metric[2]:.3f}, train acc '
# f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
# print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
# f'{str(devices)}')
print(f"epoch {epoch} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch)
time_list.append(timer.sum())
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df['time'] = time_list
df.to_excel("savefile/Unet_camvid.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(model.state_dict(), f'checkpoints/Unet_{epoch+1}.pth')train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num,scheduler)
![]()
总结
大多数医疗影像语义分割任务都会首先用Unet作为baseline,Unet的结构也被称为编码器-解码器结构,即Encoder-Decorer结构,这种结构将会出现在各类语义分割的模型中。
Unet也衍生出一系列家族成员,包括Unet++、attention-Unet、Trans Unet、Swin Unet等等。这些模型也会在之后的系列中更新。