图神经网络GNN在推荐系统的应用:综述
参考:
- 论文1:
《Graph Neural Networks in Recommender Systems: A Survey》
https://arxiv.org/pdf/2011.02260.pdf - 论文2:
《Graph Neural Networks for Recommender Systems:
Challenges, Methods, and Directions》
https://arxiv.org/pdf/2109.12843.pdf
1 介绍
1.1 推荐系统发展的三个阶段
回顾一下推荐系统的历史,一般可以分为三个阶段,浅层模型[74,125,126],神经模型[26,48,56]和基于gnn的模型[55,153,188]。
最早的推荐模型通过直接计算交互的相似度提出了基于模型的CF方法,如矩阵分解(MF)[74]或分解机[125],将推荐作为一个表示学习问题来处理。然而,这些方法面临着复杂的用户行为或数据输入等关键挑战。
为了解决这一问题,提出了基于神经网络的模型[26,48,56]。例如,神经协同过滤(NCF)将MF的内积扩展到多层感知器(MLP),以提高其能力。同样,深度分解机(DeepFM)[48]将浅层模型分解机(FM)[125]与MLP相结合。然而,由于这些方法的预测和训练范式忽略了观测数据中的高阶结构信息,因此仍然存在很大的局限性。例如,NCF的优化目标是预测用户-物品交互,训练样本包括观察到的积极用户-物品交互和未观察到的消极用户-物品交互。这意味着在为特定用户更新参数时,只涉及他/她与之交互的项目。
最近,图神经网络的发展为解决推荐系统中的上述问题提供了基础和机会。其中,图神经网络采用嵌入传播,迭代聚合邻域嵌入。通过叠加传播层,每个节点可以访问高阶邻居信息,而不是像传统方法那样只访问一阶邻居信息。
基于gnn的推荐算法具有处理结构化数据和挖掘结构化信息的优势,已成为推荐系统中最先进的方法。
1.2 GNN在RS应用上面临的问题
GNN在推荐系统应用面临以下问题:
- 首先,将推荐系统的数据输入构造成图,用节点表示元素,用边表示关系。
- 对于具体的任务,需要自适应设计图神经网络中的组件,包括如何传播和聚合,现有的作品已经探索了各种不同的选择,不同的优点和缺点。
- 基于GNN模型的优化,包括优化目标,损失函数。数据采样等等。
- RS对计算有较高的要求,而GNN的嵌入传播涉及到大量的计算,如何设计高效的GNN
2 四个角度介绍推荐系统
在本节中,我们将从四个角度介绍推荐系统的背景:阶段、场景、目标和应用
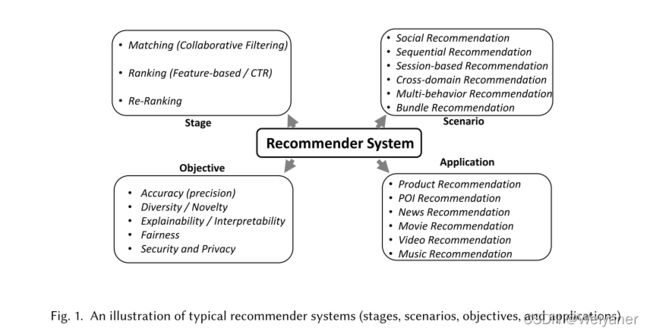
2.1 三大阶段(召-排-重)
如今的推荐系统通常由这三部分组成,分别是,召回阶段,精排和重拍。流程如下:

1、 召回
第一阶段从非常大的项目池(百万级甚至十亿级)中生成数百个候选项目,这大大降低了规模。
由于该阶段输入的数据量大,且在线服务的延迟限制严格,因此无法采用非常深的神经网络等复杂算法,而是采用简单模型和策略。
也就是说,这一阶段的核心任务是高效地检索潜在的相关条目,并获得用户兴趣的粗粒度建模一般召回阶段通常包含多个匹配渠道和多个模型,如嵌入匹配、地理匹配、人气匹配、社交匹配等。也就是多路召回。
2 排序
召回阶段结束后,将来自不同通道的多个候选项源合并成一个列表,然后使用单一的排序模型对候选项进行评分。具体来说,排名模型根据分数对这些项目进行排名,并选择排名靠前的几十个项目。
由于这一阶段的输入条目量相对较小,系统可以采用更加复杂的算法来达到更高的推荐精度[69,89,133]。由于涉及到许多特征,这一阶段的关键挑战是设计合适的模型来捕获复杂的特征交互。
3、重排
在排序阶段更多追求的是相关性(精确度),可能无法满足其他重要的要求,如新鲜度、多样性、公平性等[120],因此需要重新排序阶段。
它通常删除某些项或更改列表的顺序,以满足附加条件和业务需求。
2.2 场景
下面,我们将详细介绍推荐系统的不同场景,包括社交推荐、序列推荐、会话推荐、捆绑推荐、跨域推荐和多行为推荐。
1 社交推荐
在过去的几年里,社交平台极大地改变了用户的日常生活。通过与其他用户互动的能力,个人行为受到个人和社会因素的驱动。
具体来说,用户的行为可能会受到朋友的行为或想法的影响,这被称为社会影响[28]。
例如,微信视频平台的用户可能会因为微信好友的喜欢行为而喜欢某些视频。同时,社会同质性是许多社交平台上的另一种流行现象,即人们倾向于与自己偏好相似的人建立社会关系[107]。以社交电子商务为例,来自一个共同家庭的用户可能有相似的产品偏好,如食物、衣服、日用品等。
因此,往往将社会关系整合到推荐系统中,以提高最终绩效,这就是所谓的社交推荐。

2 序列推荐
随着时间的推移,用户会产生大量的交互行为。序列推荐方法从这些行为序列中提取信息,预测用户的下一个交互行为。在序列推荐中,用户历史行为在兴趣建模中起着重要作用。
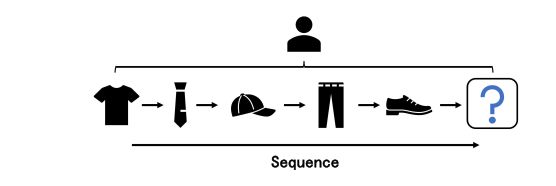
传统推荐如协作过滤[56],都是以每个用户行为为样本来训练模型。它们直接在单个项目上建模用户的偏好,但序列推荐基于用户的历史行为序列来学习时间戳感知的顺序模式,从而推荐用户可能感兴趣的下一个项目。
在序列推荐中,有两个主要挑战。
- 首先,对于每个样本,即每个序列,需要从序列中提取用户的兴趣来预测下一个条目。特别是当序列长度增加时,同时建模用户的短期、长期和动态兴趣是非常具有挑战性的。
- 其次,除了在序列内建模之外,由于物品可能出现在多个序列中,或者用户拥有多个序列,因此需要捕获不同序列之间的协作信号,以便更好地进行表示学习。
3 会话推荐(session rec)
在许多现实场景中,如YouTube和Tiktok,由于存储资源有限,没有必要长时间跟踪用户id的行为。换句话说,用户配置文件和长期的历史交互是不可用的,只提供来自匿名用户的短会话数据。
因此,传统的推荐方法(如协同过滤)在这种情况下可能表现不佳。这就引发了基于会话的推荐(SBR)问题,SBR的目标是利用给定的匿名行为会话数据预测下一个条目,如图5所示。

与序列推荐不同,同一用户的后续会话在SBR中是独立处理的,因为用户在每个会话中的行为只显示出基于会话的特征[57]。
4 捆绑推荐(bundle rec)
类似于捆绑销售,将一个组合的物品进行推荐,为了提高销售和广告业务能力。

5 跨域推荐
随着越来越多的用户与多域的多模态信息进行交互,跨域推荐(CDR)已被证明是一种很有前景的方法,可以缓解冷启动和数据稀疏问题[41,43,60,68,104,112,203]。CDR方法大致可分为单目标CDR (STCDR)和双目标CDR (DTCDR)[30]两大类。
6 多行为推荐
用户与推荐系统的交互行为不是一种行为,而是多种行为。例如,当用户点击视频时,他/她可能还会进行收集或评论等行为。在电子商务网站中,用户在购买商品之前,经常会点击、添加到购物车中、分享、收集商品,如图8所示。虽然推荐系统的最终目标是推荐用户想要购买的产品,但与用户的点击、分享等行为相比,购买行为非常稀疏。
对于多行为推荐,主要有两大挑战:
- 不同行为对于目标行为的影响不同,不同的人有不同的影响,如何精确的建模这些不同行为对目标行为的影响。
- 不同行为对items的综合表示如何学习
2.3 建模目标
在推荐中,最重要的目标当时是准确度,除此之外,还需要考虑其他的目标,比如多样性,可解释性以及公平性。
1 多样性
参见:推荐系统的多样性总结
2 可解释性
由于目前的推荐系统大多采用深度学习范式,因此对推荐的可解释性有迫切的需求[201]。可解释推荐系统的重点不仅在于产生准确的推荐结果,还在于产生说服性的解释,说明如何以及为什么向特定用户推荐该商品[201]。增加推荐系统的可解释性,可以增强用户感知的透明度[131]、说服力[142]和可信度[75],方便从业者调试和细化系统[201]。
3 公平性
推荐系统作为一个典型的数据驱动系统,可能会受到数据和算法的影响而产生偏差,其公平性越来越受到关注[4,86,108]。具体来说,根据所涉及的利益相关者,推荐系统的公平性可以分为两类[4,86,108]:
- 用户公平性,试图确保在特定用户或人口统计群体之间没有算法偏见[9,78,84]
- 项目公平性,表示不同项目的公平暴露,或不同项目之间没有流行偏见[2,3,86,108]。在这里,我们关注的是用户公平性,而将项目公平性放在多样性部分。
2.4 应用领域
推荐系统广泛存在于当今的信息服务中,具有各种各样的应用,其中具有代表性的有:
1 产品(电商)推荐
2 POI推荐
POI(兴趣点)推荐,也是一个流行的应用程序,旨在为用户下次访问推荐新的地点/兴趣点。在兴趣点推荐中,有两个重要的因素,空间因素和时间因素。空间因子是指POIs自然存在的地理属性,即地理位置。此外,由于用户无法像在电子商务网站上浏览/购买产品那样轻松地访问POIs,用户的访问次数也在很大程度上受到其地理活动区域的限制。此外,时间因素也很重要,因为用户的访问/签到行为往往是一个序列。这激发了下一个POI或后续POI推荐的问题[37,90,179]。具有代表性的就是美团、点评商品推荐
3 新闻推荐
与其他推荐应用不同的是,新闻推荐需要对新闻文本进行适当的建模。因此,自然语言处理方法可以与推荐模型相结合,更好地提取新闻特征[114]。
此外,用户总是对最新的新闻感兴趣,可能拒绝过时的。因此,从快速变化的候选人群中快速、准确地过滤新闻也很关键,但具有挑战性。在新闻推荐方面,MIND数据集[159]是最近发布的具有代表性的基准数据集。
4 电影推荐
电影推荐是最早的推荐系统之一。正是netflix的电影推荐比赛[7]激发了许多先锋的推荐研究[7,73]。电影推荐的早期设置是估计用户对电影的评分,从1到5,这被称为显式反馈。最近,二元隐式反馈已经成为比较流行的设置[56,126]。
3 GNN介绍
随着社会网络、分子结构、知识图等海量图数据的迅速出现,近年来出现了一波图神经网络(GNN)研究热潮。GNN发自于CNN和GRL(Graph representation learning)等学术的发展.
对于图像或文本等常规欧几里德数据时,CNN在提取局部特征方面是非常有效的。然而,对于图形等非欧几里德数据,CNN需要泛化处理操作对象(如图像中的像素或图形上的节点)大小不固定的情况。在GRL方面,它的目标是为表示图的复杂连接结构的图节点、图边或图子图生成低维向量。
1 图构建
定义一个图G(V,E),VE分别是图的节点和边集合。近年来,基于gnn的模型主要针对以下三类图设计专门的网络:
- 同构图,同构图的每条边只连接两个节点,节点和边只有一种类型。
- 异构图,每条边只连接两个节点,节点或边的类型有多种
- 超图,其中每条边连接两个以上节点。
在当今的许多信息服务中,关系数据很自然地以图形的形式表示。例如,隐含的社交媒体关系可以被认为是一个统一的图,节点代表个人,边连接相互关注的人。但是,由于图像和文本等非结构化数据并不显式包含图,因此需要手工定义节点和边来构建图。
以自然语言处理(NLP)中使用的文本数据为例,将单词/文档描述为节点,并根据词频-文档频率逆(Term Frequency- inverse Document Frequency, IF-ITF)构造节点之间的边[186]。知识图(KG)是异构图的一个典型实例,是图上表示学习的一个新兴研究方向。KG集成了多个数据属性和关系,节点和边分别被定义为实体和关系。具体来说,KG中的实体可以涵盖广泛的元素,包括人、电影、书籍等。这些关系被用来描述实体之间如何相互关联。例如,一部电影可以与人(如演员或导演)、国家、语言等相关。