2021-06-05生成对抗网络一 李宏毅(学习笔记)
目录
(二)GAN的理论
GAN的评估方法
Condition Generation
无监督训练
GAN
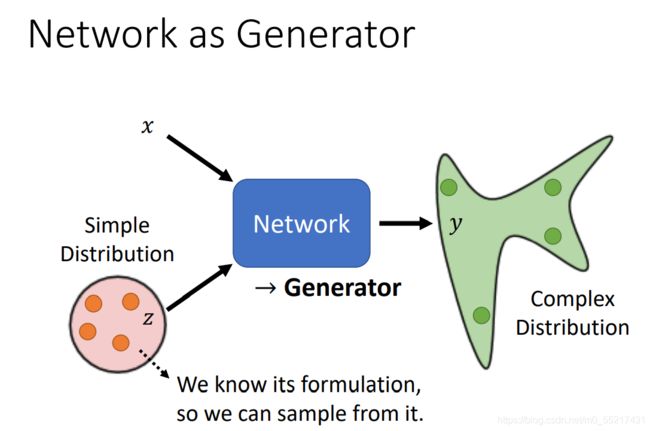
把network作为generator使用,特别的地方就是network的输入会加上一个随机变量z,这个z可能是从某一个distribution采样出来的,该distribution应该够简单,它可能是一个公式,以便我们采用,也就是同时看输入x和z得到输出。
z特别的地方是:它是不固定的,每次我们用该网络时都会生成一个z,每次由输入x时,我们都从distribution中做一个sample和x运算,这时我们network的输出就会转化成一个复杂的distribution,我们叫该类网络为生成对抗网络。
那么为什么有时候需要输出时一个分布呢?
使用普通的网络,在训练资料中有时会存在多种可能性,所以最终预测的时候可能会得到错误的结果,就比如游戏人物预测结果可能同时向左向右转
为了解决这类问题,一种方法就是让网络的输出不再是固定的,而是有概率的,输出一个几率的分布,也就是同时包含向左转和向右转的可能性。假设z是一个bimary的随机变量,有0和1各占0.5的概率,网络可以学习到的结果可能就是z采样到1的时候就向左,采样到0就向右,这样就可以解决多种可能性的问题。
总结起来就是,我们想要找一个function,但是同样的输入有多种可能的输出,而这些不同的输出都是对的,这时候我们就需要机器有一些创造的能力,举例来说就是聊天机器人的应用。
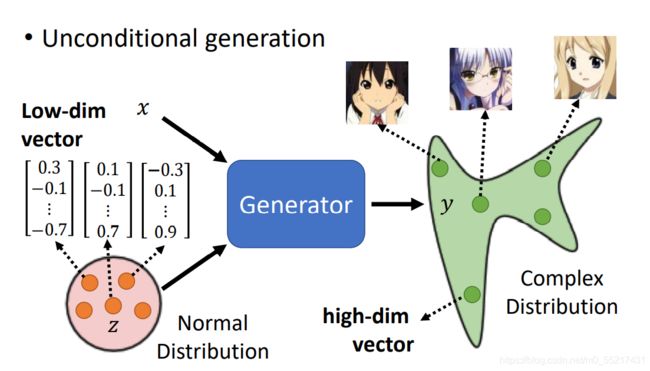
Unconditional generation(没有x)
输入为z,输出y;假如z是一个normal distribution中采样出来的一个低维向量,y是一个复杂的输出分布,当输入的向量不同的时候,就会输出不同的图片
GAN网络除了Generator外,还要多训练一个Discriminator
介绍:Discriminator本身也是一个神经网络,假设拿一张图片作为输入,输出就是一个数字Scalar,其值越大,就说明输入的图片越像我们想要的图像
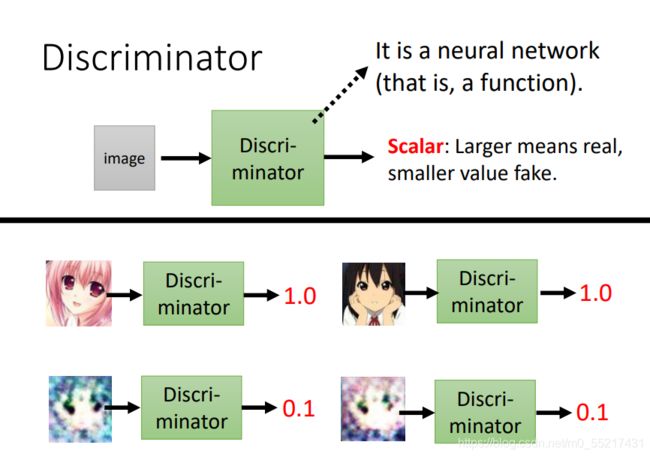
generator和discriminator的网络结构我们都可以自己设定
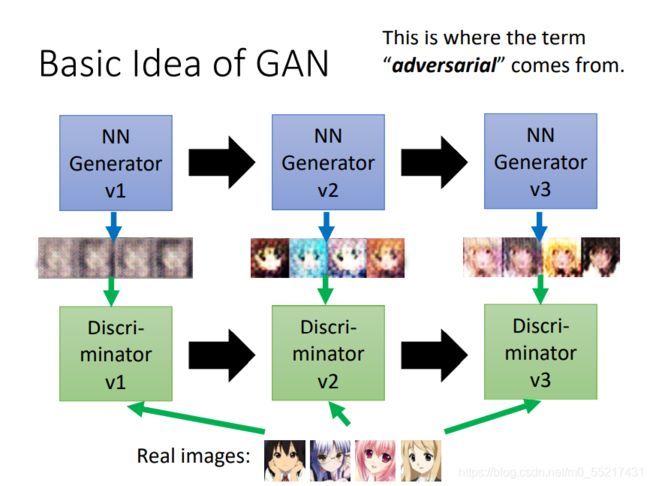
GAN的基础架构
以以上的例子接着说,假设generator需要输出我们想要的图片,学习一开始输出的效果可能并不好,然后discriminator就会把输出图片和真实图片做对比,得出它和我们期望的结果的一个衡量值,然后generator为了骗过discriminator,就会继续进化,产生上一代discriminator期望的特征,但是discriminator也会继续进化,他会继续分辨第二代generator生成的图片和真实图片之间的差距,,循环往复,二者不断进步,
算法原理:
1.初始化generator和discriminator
2.在每个训练轮次中:
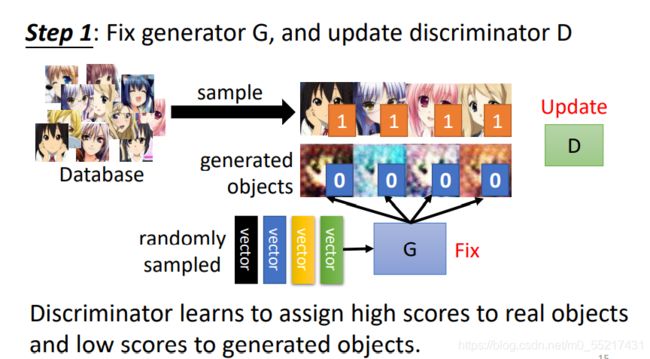
(1)定住generator G,更新discriminator D,根据G生成的结果和我们想要的图片做对比训练,得出差异,就比如真实图片为1,生成图片为0,接下来要做的就是分类问题或者回归问题,如果是分类,就训练一个classifier,分辨两者之间的差异,就可以新的图片做预测
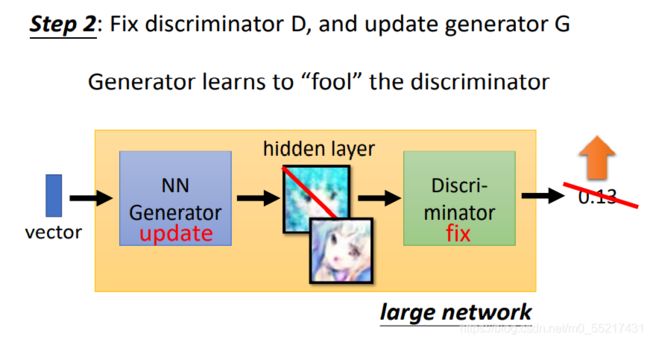
(2)定住D,训练G,此时D的打分方法是固定的,G的训练目标是要D的输出值越大越好,过程中直接把G和D接起来当作一个大的网络来看待,后面的参数是固定的
GAN的理论
G的作用就是要保证生成的图片和当前D期望的图片差距最小,也就是这里用的损失函数
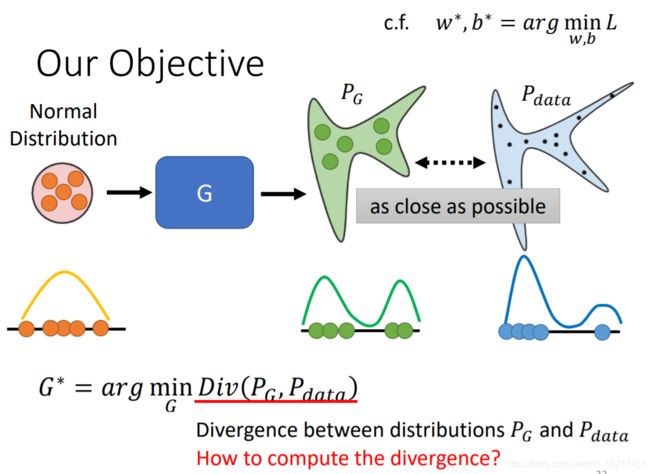
Divergence就是用来衡量两个distribution的相似度
那么如何计算Divergence呢?
Gan网络告诉我们的是,,只要我们知道怎么从PG和Pdata中采样出来数据,就有办法算出Divergence,不要知道PG和Pdata实际上的公式规则是怎样,只要能够采样,就能够算出来,下面是采样的过程:

后面就要靠D的力量,我们根据PG和真实的Pdata训练出一个D,它的目标是对真图和生成图的一个辨别,用公式可以表示为一个优化的问题,就是训练一个D,他可以去最大化某一个目标函数,这个目标函数的意义就是,从Pdata采样出来的数据y,然后我们把它放到D里面得到一个分数,另外我们也从PG产生出来的图片做一个采样,得到一个分数,我们希望这个目标函数越大越好,分数越大表明图片越接近真实结果,这个目标函数值就是我们想要的divergence
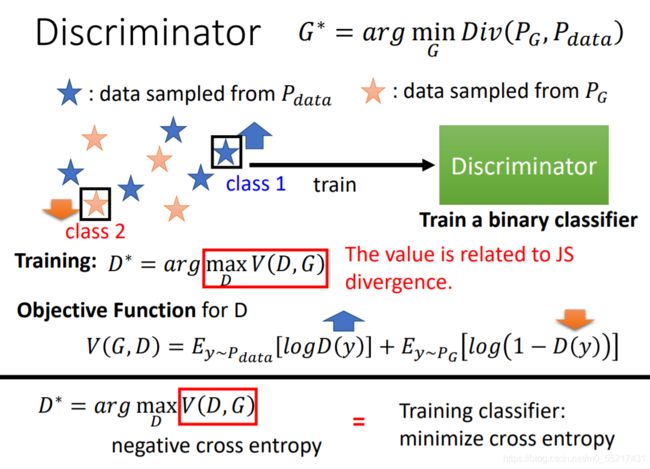
也可以当作一个分类问题,但是当真假数据很像并且混在一起时,很难把他们区分开,就很难把目标函数的值变得很大,但是它们相似度比较低的话对于D就很容易区分。

好,现在我们回归到原来的问题:我们最初的目标是要训练一个G,使得PG和Pdata的差距尽可能的小,对于他们差距的计算我们通过D来求上述目标函数来解决,而对于不同divergence的计算我们也可以通过其他的目标函数来解决。
JS divergence不适合的原因:
1.从高维空间来看,图片就是低维的Manifold,PG和Pdata映射到二维空间,就是两条直线,除非它们刚好重合,否则相交的范围几乎是可以忽略的
2.我们不知道PG和Pdata长什么样子,我们对他们的理解只来自采样的数据,它们有非常大的Overlap的范围,如果我们采用的点不够多,对D来说也不能很好的区分
对于不相交的直线来说,无论它们距离远近,算出来的结果都是log2,有重合就是0,这样我们每次训练出来的结果都是100%,不能看出我们的G一个越来越好的过程,对图像的对比只有0和100,
于是就有了Wasserstein distance
他会固定P和Q,然后穷举所有的moving plans,选取最小值当作Wa distance,
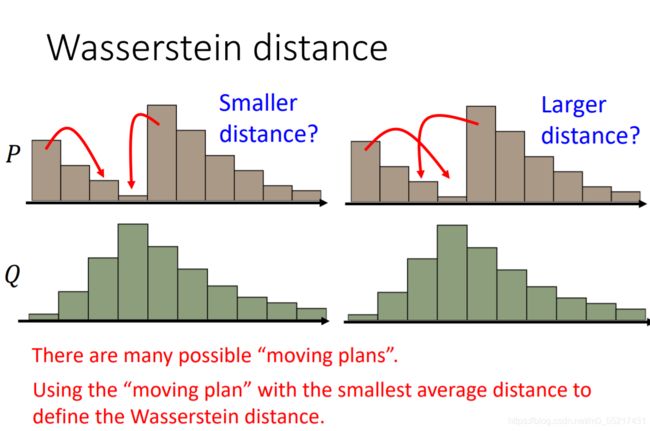
通过这种计算方式,我们就可以知道生成数据和真实数据之间的差距,从而很好的计算divergence。
使用这种方式计算divergence的网络为WGAN
那么如何计算Wasserstein distance呢
计算结果如下,其实就是把Pdata放入D中的评估值减去PG,保证这个值最大,也就保证了D对二者的区分度越好;而D在这里有个限制,他必须是一个足够平滑的函数,因为不能给generated和real data无限大的负值和正值,算出的wd也会无限大,这样会导致没有办法收敛,所以要加上这个限制,表明他不能变化太剧烈

那么如何保证D一定满足这个限制呢?
下面有几种原始的解决方案

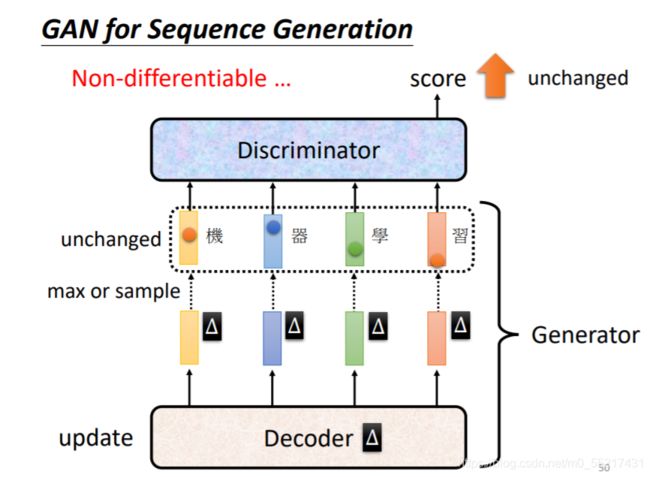
但是GAN对于文字的生成十分困难,生成文字的时decoder扮演G的角色,负责产生文字,但是Decoder参数如果有很小的变化,在取max那个分数最大的token的时候是没有改变的,对于Discriminator来说它的输出是没有改变的,所以就没有办法算微分(MaxPooling为什么可以算微分),但是可以用Reinforcement learning来训练生成器
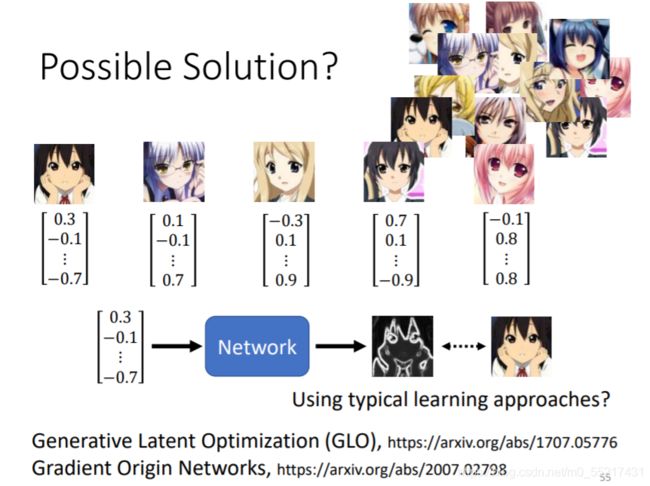
一些思考:输入Gussian的一个随机变量,从其中采样出来的向量,把他变成一张图片,可不可以用supervised learning的方法做呢?
也就是说,把已有的图片都配上一个Vector,从Gussian分布采样出来的vector,接下来就直接训练一个网络,以向量和它们对应的图片作为结果训练,但是如果是随机的向量,训练起来可能比较困难,参考论文链接如下:
GAN的评估方法
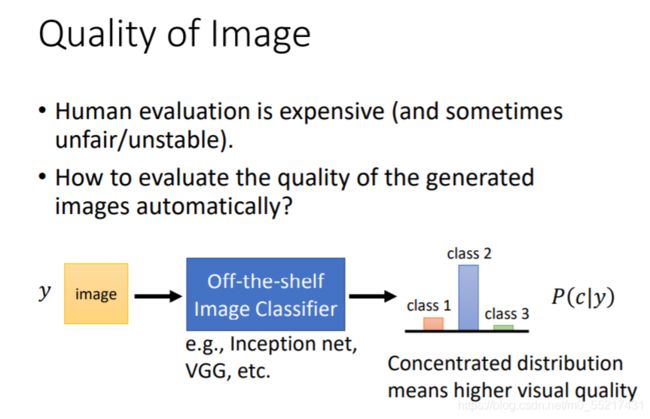
那么有没有方法来量Generator的好坏呢,以往的方法都只是用人眼看,没有客观的评估方式。
有一中方法是把结果放到影响分类系统中,输出的条件概率分布结果越集中,说明这个图片产生的比较好,
但是这种方法可能会产生Mode Collapse的现象,就是说可能对于结果比较好的图片,为了骗过D,G可能会重复产生。

还有一种比较难分辨的问题叫做MOde Dropping,也就是产生出来的资料只有真实资料的一部分,它的多样性达不到真实资料的多样性

下图是对多样性比较好的结果的评估,这里评估的是图片数量
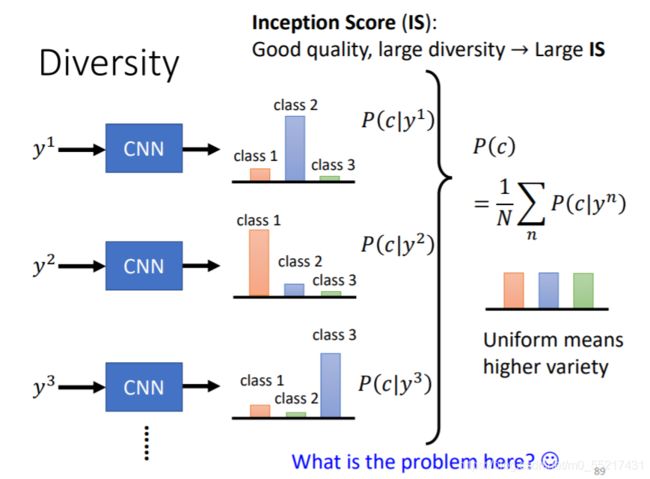
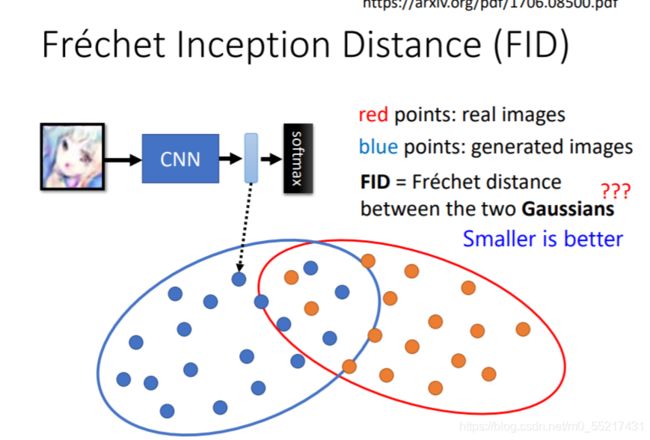
IS评估标准:单张图片质量高,总图片多样性大,下面是FID评估标准,把量类图片混在一起作为高斯分布,映射到一个二维面上,越相近分数越高
但是也并不能完全解决评估的问题,如果G产生的图片和原图意义,就没有意义

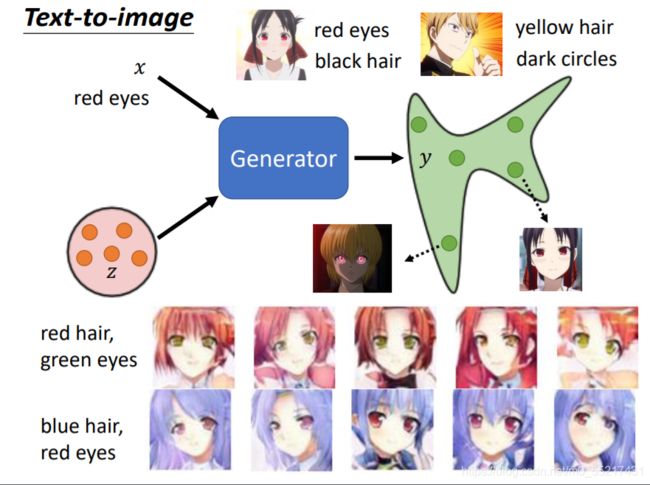
Condition Generation
可以用来做文字生成图片,他是在有条件下的生成,这个时候x就是一段文字,可以用RNN读过去得到一个向量,或者放到Transformor的Encoder里,再把Encoder输出的向量平均,再放到Generator里,
但是在训练D时,我们还要看文字的输入,不仅仅看G产生的图片y和真实图片的差距,还要输入条件x
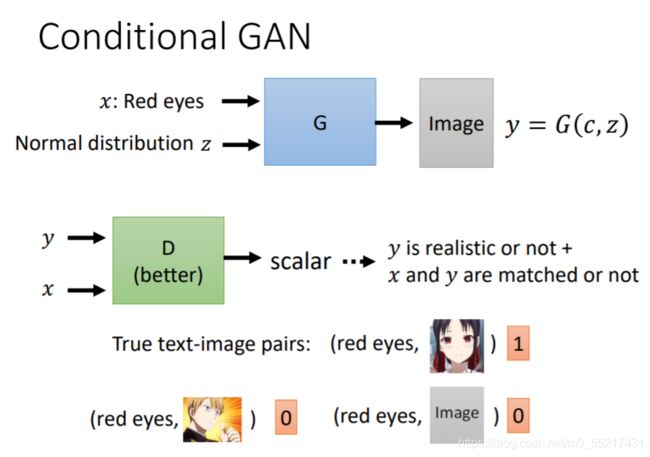
一方面图片要好,另一方面条件要配得上,这样D打出的分才可以高,我们需要给D一些标注过的训练资料,(文字和图片)
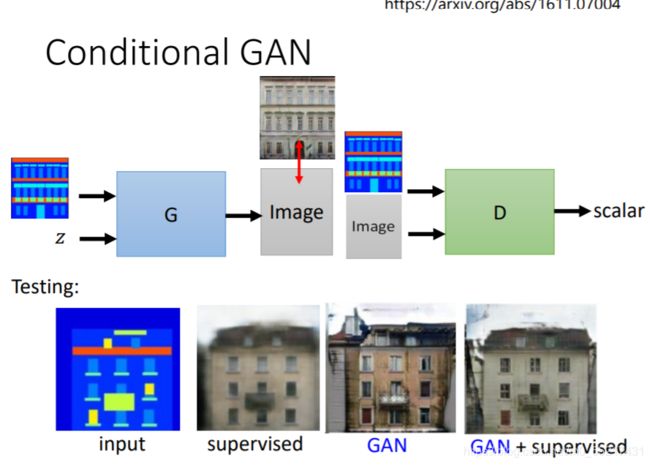
另外Conditonal GAN也可做image to image的操作,比如给房子的设计图,然后直接把房子的图片产生出来,黑白图片上色,素描图变事物,去雾等操作
但是如果用supervised的方法做生成他可能就会产生模糊的结果,由于输出有不同的可能,但是GAN的创造力又过于丰富,会产生我们不需要的东西,但是把他们结合起来可能结果最好,也就是G一方面要骗过D,另一方面要尽可能逼近真实图片
无监督训练
比如把人像转换成二次元风格图像
如果用GAN的思路,就是从原图采样,生成后放图D和动漫图库佐渡滴鼻,就结束了
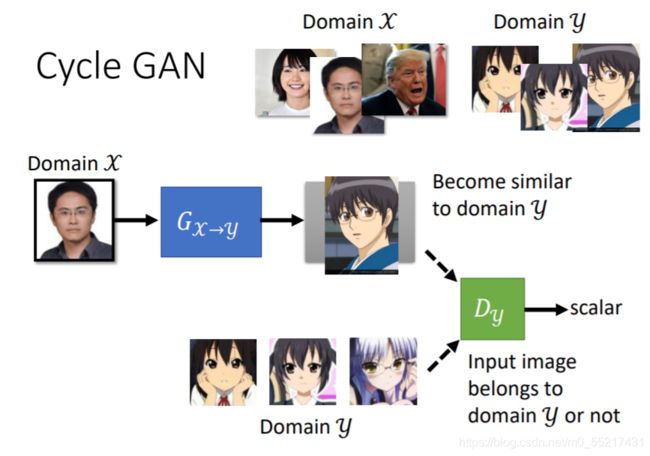
G可以为了骗过D生成卡通图,但是生成的图片可能和我们的输入x没有关系,所以这种做法是不够的,那么如何强化输入和输出的问题呢,我们无法套用conditonal GAN,因为我们没有成对的资料做监督
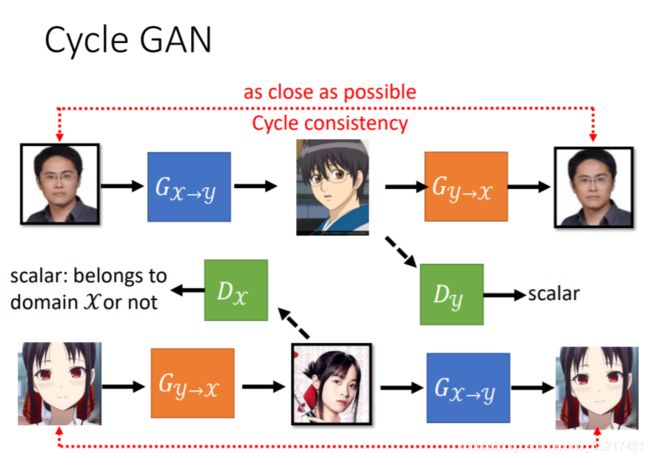
Cycle GAN可以解决这一问题,在生成图片后,我们需要把他还原成原图,经过两次转换,输入和输出越接近越好,这样前面的G就有了限制
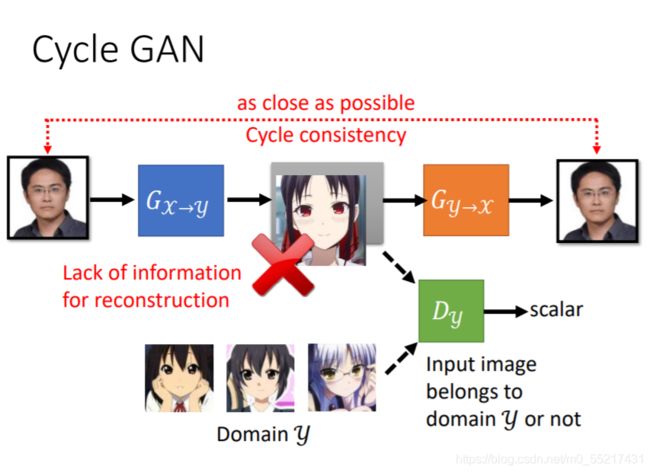
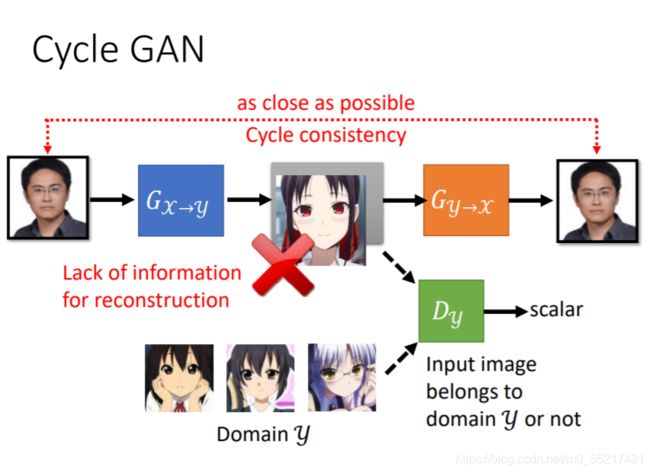
但是机器可能也会学习到一些奇怪的转换,并没有按照我们想要的方式生成图片,他只有保证最后输出和输入相近,中间生成方式未必是我们期待的,比如把眼镜特征转换为别的东西,在转换回来,目前没有特别好的解法,但是实际上一般不会遇到,因为网络一般不会学习太复杂的转换。