Kubernetes集群搭建以及基本使用【具详细】;
文章目录
- 前言
- 一、有了docker为什么还需要k8s
- 二、K8s介绍、集群架构、服务器配置推荐
-
- 1.kubernetes是什么
- 2.Kubernetes集群架构与组件
- 3.生产环境部署K8s的两种方式
- 4.服务器硬件配置推荐
- 5.使用kubeadm快速部署一个k8s集群
- 三.部署网络组件的意义,起到了什么作用
- 四.k8s将移出对docker支持的插件
-
- 如何应对?
- 五.切换容器引擎为Containerd,K8s基本核心资源
- 六.Kubectl集群管理工具
-
- 1.kubeconfig配置文件
- 2.kubectl 管理命令概要
- 3.快速部署一个网站
-
- 1).使用Deployment控制器部署镜像
- 2).使用Service将创建的pod暴露出去
- 3).访问应用
- 七.基本资源概念
-
- 1.命名空间的概念
- 2.命名空间的应用场景
- 3.命名空间存在的意义/作用
- 4.namespace默认命名空间
- 5.创建并指定命名空间
- 八.资源编排(YAML)
-
- 1.YAML文件格式说明
- 2.YAML文件创建资源对象
-
- 1).使用YAML创建deployment应用
- 2).使用YAML创建service应用
- 3).运行创建好的yaml文件
- 3.YAML文件中字段太多,记不住怎么办
-
- 1).第一种方式:通过官方提供的模板,直接拿过来改
- 2).第二种方式:用命令生成示例,然后再修改(这种方式适用于所有资源)
-
- **场景一:想使用yaml文件创建资源但是不知道怎么写**;
- **场景二:想查看正在运行pod的资源信息,但是找不到源yaml文件或者本来就不是yaml文件创建的 而是通过命令的方式创建的;**
- **场景三:如果有某个字段的拼写忘记了,或者不清除某个字段下都有那些字段支持;**
- 总结
前言
随着容器化和微服务的不断发展,Kubernetes这门技术也越来越重要,本人也从头开始学起了Kubernetes,可能学的时间稍微有点晚了哈哈,接下来我就把我所学习到有关kubernetes的知识分享给大家;
一、有了docker为什么还需要k8s
如图:

企业需求:为了提高业务并发和高可用,会使用多台服务器,因此会面临这些问题:
- 多容器跨主机如何提供服务?
- 多容器如何分布式部署到节点?
- 多主机多容器怎么升级?
- 怎么高效的管理这些容器?
因此为了解决这些的核心问题出现了容器集群管理系统:
容器编排系统
- Kubernetes
- Swarm
- Mesos Marathon
kubernetes
kubernetes是google开源的强大的容器集群管理系统,也是我们接下来要学习的主角;
Swarm
Swarm是Docker的官方研发的,它的优势是集成在docker里面了,不用再额外的部署,直接可以将多个docker主机,在docker daemon层面直接启用集群模式,来组建集群,这样一来就能满足集群的管理能力;现在swarm已经被弃用了,主要是因为swarm的功能比较单一,还有一个原因是因为kubernetes的出现,导致很少人去使用了;
Mesos Marathon
Mesos主要是一个集群的分布式调度系统,主要从事调度方面的能力,Mesos Marathon是Mesos研发出的一个框架,实现了对容器的一个管理;
回归主题,我们再从一个全局的视角,去按层次看待一下这个kubernetes容器集群管理系统的层次结构;这里主要是了解一下kuberntes处于我们技术架构的哪一层,这一层具体做了什么作用,我们来宏观的看一下;
如图:

IaaS基础设施层:
这层是我们接触最多的,我们平常做的运维工作都是维护的IaaS层,我们平常维护的虚机、物理机、网络、存储、数据库都是属于IaaS层;
容器引擎层:
这层对运维来说也是主要进行去维护的,主要是进行管理容器,docker只是其中一个容器引擎;
docker的特点:
- 环境的标准化;
- 隔离性(弱隔离);
- 轻量级;
- 应用部署的最小单元,可以实现快速部署;
- 可移植性强;可以在任何地方去运行这个容器;
容器编排层Kubernetes:
主要是做集群化的管理docker的这些容器,包括弹性伸缩,资源共享、调度,近一步实现逻辑上的隔离,对多个docker主机进行集群化的管理;docker+kubernetes是目前组成容器平台的核心技术栈;
需要做的事有
前期:基础建设;
中期:开发各种各样的管理系统,发布系统,监控系统,日志系统;
后期:对k8s做一些安全方面的工作,优化方面的工作,再去完善平台化;
接下来我们再总结下有了docker为什么还用kubernetes,举一个生活上的例子,kubernetes就好比一个篮子,在kubernetes管辖的这些docker主机上运行的都是些容器,这些容器就好比是鸡蛋,鸡蛋多了就要去用篮子去乘,方便后面的搬运;
二、K8s介绍、集群架构、服务器配置推荐
1.kubernetes是什么
- kubernetes是Google在2014年开源的一个容器集群管理系统,kubernetes简称K8s(原因是K到s之间有8个字母哈哈);
- kubernetes主要是用于容器化应用程序的部署,扩展和管理,目标是让部署容器化应用简单高效;
官方网站:https://kubernetes.io
官方文档:https://kubernetes.io/zh/docs/home/
2.Kubernetes集群架构与组件
如图:
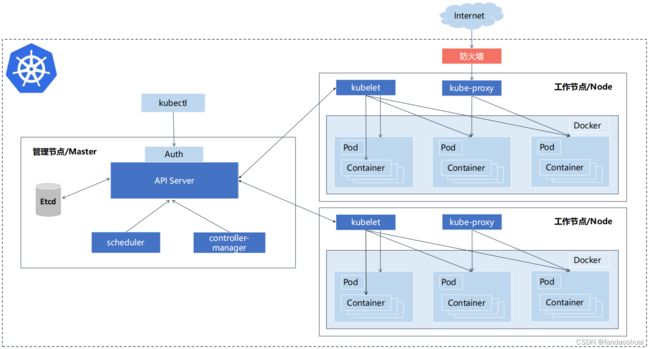
kubernetes整体的架构是分为了管理节点和工作节点,上图左侧部分就是管理节点/master节点,主要负责整个集群的管理工作;右侧是工作节点/node节点,工作节点是实际运行容器的地方,我们后面部署的应用,应用产生的容器都是在工作节点上运行的;
Master组件:
-
Kube-api-server:Kubernetes API,集群的统一访问入口,各组件协调者,以RESTful API提供接口服务,所有对象资源的增删改查和监听操作都交给API Server处理后再提交给Etcd存储;
功能一:以后自己开发了k8s管理系统,管理的就是k8s集群,就会需要去调用集群的api(API Server),去进行操作;
功能二:API Server是各个组件的协调者,像工作节点的组件,管理节点的组件都会去向API Server获取一些数据,然后完成自己的工作; -
Kube-scheduler:根据调度算法为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上;
-Kube-controller-manager:处理集群中常规后台任务,一个资源对应着一个控制器,而ControllerManager就是负责管理这些控制器的; -
kubectl:命令行管理工具,用于连接k8s api管理集群,后面我们主要使用kubectl来管理k8s集群;
-
Etcd:分布式键值存储系统,说白了这里就是一个k8s的数据库,用于保存集群状态数据,比如Pod、Service等对象信息;
node组件:
- Kubelet:Kubelet是Master再Node节点上的Agent,管理本机运行容器的生命周期,比如创建容器、pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器;
主要负责的是负责容器的创建、销毁、挂载数据卷,维护容器; - Kube-proxy:在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作;为容器提供一个网络转发,如何访问容器以及如何访问到k8s里面的应用;
- 第三方容器引擎:例如docker、containerd、podman容器引擎,运行容器;
上面是细分一点的,下面是稍微概要性的集群架构

一个k8s集群会有多个worker node节点,里面会运行docker、kubelet和kube proxy这三个组件,master节点会运行api server、controller-manager、scheduler这三个组件负责管理节点,其中api server会连接etcd来去读写数据;
3.生产环境部署K8s的两种方式
-
kubeadm
kubeadm是一个工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群(由于二进制部署复杂,所以官方提供了这个工具),现在已经成熟了,可以在生产环境使用;
部署地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/ -
二进制
从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群;二进制搭建是比较复杂的,但是可以帮助我们熟悉在搭建过程中的各种配置文件,各种组件启动的关联关系;
下载地址:https://github.com/kubernetes/kubernetes/releases -
第三方工具:本质上来说都是根据官方提供的二级制或kubeadm来实现的,万变不离其宗~
结论:kubeadm和二进制现在在市场上的份额是各占50%的,都相差不多,所以说两种方式都可以来使用,但是两种方式都要会,因为各有各的有点;
4.服务器硬件配置推荐
推荐最低配置:
| 实验环境 | k8s master/node | 2C2G+ | |
| 测试环境 | k8s-master | CPU | 2核 |
| 内存 | 4G | ||
| 硬盘 | 20G | ||
| k8s-node | CPU | 4核 | |
| 内存 | 8G | ||
| 硬盘 | 20G | ||
| 生产环境 | k8s-master | CPU | 8核 |
| 内存 | 16G | ||
| 硬盘 | 100G | ||
| k8s-node | CPU | 16核 | |
| 内存 | 64G | ||
| 硬盘 | 500G | ||
我们在申请配置时该如何申请?
假设一个容器1C1G;那么一个应用跑3个容器;一台node是8C16G;
这种情况下,至少能跑8个容器,节点数量+节点配置决定了能跑多少个容器(多少个应用);
5.使用kubeadm快速部署一个k8s集群
部署集群由于过长,在另一个帖子里,需要的话请看另一篇文章:kubeadm部署k8s集群手册;
三.部署网络组件的意义,起到了什么作用
在我们上面部署的k8s集群时,用了calico组件,为什么k8s要依赖这个calico组件呢,我们接下来看下calico的作用

如上图
1.docker有自己独立的网段(172.17.0.0/24)来为容器随机分配ip,一般情况下分配的ip都是172.17.0.2,这时两个主机之间的容器是不能通信的;
2.即使分配的ip不一样,假设主机1上的容器1(172.17.0.2)与主机2上的容器1(172.17.0.3),此时如果想让两个容器1与容器2之间通信,只能通过宿主机的网络转发(也就是上图的192网络)来到达对方;
3.主机1上的容器1怎么知道目标容器在哪个宿主机上;
那么我们现在知道了两台不同节点的容器需要通信必须满足三个条件
- 容器的IP不能相同
- 必须通过宿主机的网络转发才能与对方通信
- 必须得知道要通信对方的宿主机
因此为了满足这三个条件就必须要部署网络组件(当然通过一定的网络技术例如iptables、nat也可以达到上面的条件,但是过程太过繁琐、复杂)
当我们的业务在容器里进行应用的时候,服务与服务之间是需要相互调用的,这里举个简单的例子,web服务器需要与数据库进行交互,那它们两个容器之间必须是可以相互通信的,如果不能相互通信,web服务器肯定不能调用数据库;所以部署网络组件的目的是打通Pod到Pod之间的网络,Node与Pod之间的网络,从而集群中的数据包可以任意传输,形成一个扁平化(全网通)的网络;
综上所述部署网络组件的作用可以用一句话来概括:
网络组件可以实现容器跨主机网络通信;
主流的网络组件有:Flannel、Calico等;目前calico是主流的,它的扩展能力强,性能比较稳定。
CNI的解释:
CNI(Container Network Interface,容器网络接口)就是k8s对接这些第三方网络组件的接口,由k8s提供这个CNI然后其它的网络组件去适配这个网络组件接口;
四.k8s将移出对docker支持的插件
在了解这个话题之前,我们需要知道CRI是什么;
- CNI 容器网络接口
- CRI 容器运行时接口
- CSI 网络存储接口
为什么说k8s将移除对docker支持的插件呢,因为从k8s开源到现在,在中期的时候才开源了CRI,并不是说刚开始就开源了CRI,在没有这个CRI之前,k8s只支持docker,如果说别的容器引擎要去接入k8s的话只能去做适配;所以现在k8s默认的容器引擎还是docker,那么k8s为了支持docker就搞了docker-shim这个组件,这个docker-shim是k8s为了专门与docker适配的,它是kubelet实现中的组件之一,能够与Docker Engine进行通信;
k8s --> docker-shim --> docker
那么后来为了能够适配其它容器引擎,就出现了CRI
k8s --> docker-shim/CRI --> docker
那么在k8s后面(应该是1.24版本)计划会弃用kubelet中的docker-shim也就是k8s不能默认直接使用docker引擎了,那么在k8s里再想使用docker只能让docker去支持k8s的这个CRI容器运行时的接口;
k8s --> CRI --> docker(支持CRI)
那么为什么k8s会将docker-shim移除呢?
主要有两个客观原因:
- Docker内部调用链比较复杂,多层封装核调用,导致性能降低、提升故障率、不易排查;
- Docker还会在宿主机创建网络规则、存储卷,也带来了一定的安全隐患;
- k8s要做一定的代码优化;

大家可以看下这张图,这是创建一个容器所经历的阶段,可以发现中间要经过好几个阶段,那么自然而然会带来一些故障率;
如何应对?
那么在未来的kubernetes版本彻底放弃Docker支持之前,引入支持的容器运行时。
除了docker之外,CRI还支持很多容器运行时,例如
- containerd:containerd与Docker相兼容,相比Docker轻量很多,目前较为成熟;
- cri-o,podman:都是红帽(RedHat)项目,目前红帽主推podman;
大家有没有感觉这个container很熟悉?其实containerd就是上图中的containerd,在之前docker分为社区版和企业版时,将docker进行了解耦,解耦发生最大的变化就是将containerd成为了一个独立运行时并支持CRI,也就是说containerd可以脱离docker独立的管理容器;后来docker又把containerd捐献给了CNCF基金会。
所以在以后可能containerd可能会成为主流(大家可以未雨绸缪的去了解下),很多大企业现在都已经换成containerd了,包括我之前在阿里云上创建ACK的时候,会出现让选择容器运行时的一个选项,上面就涵盖了containerd和docker两项;
提示:目前docker还是能用的,因为我们企业中用的版本大多是1.18---1.20左右,并不是最新的版本;
五.切换容器引擎为Containerd,K8s基本核心资源
切换容器引擎这个内容蛮多的,我们单开一个帖子去做,有兴趣的可以看下:Kubernetes切换Docker容器引擎为Containerd
六.Kubectl集群管理工具
1.kubeconfig配置文件
kubeconfig配置文件作用:
用于kubectl去连接k8s集群,使用kubectl config指令可以生成config指令生成kubeconfig文件;

2.kubectl 管理命令概要
| 类型 | 命令 | 描述/作用 | |
| 基础命令 | create | 通过文件名或标准输出创建资源 | |
| expose | 为Deployment,Pod创建Service | ||
| run | 在集群中运行一个特定的镜像 | ||
| set | 在对象上设置特定的功能 | ||
| explain | 命令行文档参考资料 | ||
| get | 显示一个或多个资源 | ||
| edit | 使用系统编辑器编辑一个资源 | ||
| delete | 通过文件名、标准输入、资源名称或标签选择器来删除资源 | ||
| 部署命令 | rollout | 管理Deployment,Daemonset资源的发布(例如状态、发布记录、回滚等) | |
| scale | 对Deployment、ReplicaSet、RC或Job资源扩容或缩容pod数量 | ||
| autoscale | 为Deploy,RS,RC配置自动伸缩规则(依赖metrics-server和HPA) | ||
| 集群管理命令 | certificate | 修改证书资源 | |
| cluster-info | 显示集群信息 | ||
| top | 查看资源利用率(依赖metrics-server) | ||
| cordon | 标记节点不可调度 | ||
| uncordon | 标记节点可调度 | ||
| drain | 驱逐节点上的应用,准备下线维护 | ||
| taint | 修改节点taint标记 | ||
| 故障诊断和调试命令 | describe | 显示资源详细信息 | |
| logs | 查看Pod内容器日志,如果Pod中有多个容器,-c参数指定容器名称 | ||
| attach | 附加到Pod内的一个容器 | ||
| exec | 在容器内执行命令 | ||
| port-forward | 为Pod创建本地端口映射 | ||
| proxy | 为Kubernetes API server创建代理 | ||
| cp | 拷贝文件或目录到容器中,或者从容器内向外拷贝 | ||
| auth | 检查授权 | ||
| debug | 创建调试会话,用户排查工作负载和工作节点故障 | ||
| 高级命令 | diff | 将在线配置与指定的文件对比 | |
| apply | 从文件名或标准输入对资源创建/更新 | ||
| patch | 使用补丁方式修改,更新资源的某些字段 | ||
| replace | 从文件名或标准输入替换一个资源 | ||
| kustomize | 从目录或者URL构建kustomization目标 | ||
| 设置命令 | label | 给资源设置、更新标签 | |
| annotate | 给资源设置、更新注解 | ||
| completion | kubectl工具自动补全,source <(kubectl completion bash) (依赖软件包base-completion) | ||
| 其它命令 | api-resources | 查看所有资源 | |
| api-versions | 打印受支持的API版本 | ||
| config | 修改kubeconfig文件(用于访问API,比如配置认证信息) | ||
| version | 查看kubectl和k8s版本 | ||
3.快速部署一个网站
部署应用流程:

首先使用dockerfile构建镜像,然后可以传到镜像仓库,再使用k8s控制器(Deployment、Statefulset、Daemonset)去部署镜像,然后再使用Service、Ingress去对外暴露应用,最后再对应用进行监控(Prometheus+Grafana)、收集日志(ELK)等;
1).使用Deployment控制器部署镜像
[root@k8s-master ~]# kubectl create deployment my-web --image=fandaoshuai/java-demo
deployment.apps/my-web created
[root@k8s-master data]# kubectl get pod #可以看到会创建一个容器出来
NAME READY STATUS RESTARTS AGE
my-web-7b758f45b7-dpjwz 1/1 Running 0 3m23s
镜像来源:
docker hub(https://hub.docker.com)默认的拉取镜像地址,即镜像地址里没有包含ip或者域名的都是在这里下载;
私有镜像仓库:即镜像地址里包含ip或者域名的都是属于指定的镜像仓库拉去的;
2).使用Service将创建的pod暴露出去
[root@k8s-master ~]# kubectl expose deployment my-web --port=80 --target-port=8080 --type=NodePort
service/my-web exposed
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 18d
my-web NodePort 10.107.158.175 <none> 80:30817/TCP 4s
提示:因为这里我的这个镜像是基于tomcat封装的,所以targetpod为8080
我们可以通过kubectl get endpoints来查看service关联的容器(target-pord端口)
[root@k8s-master ~]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.1.1:6443 18d
my-web 10.244.169.130:8080 66m
- –port:service端口,内部使用,用于集群内其它pod访问的端口;
- –target-port:容器中服务运行的端口,可以理解为是容器内应用的端口;例如nginx 80、tomcat 8080、mysql 3306;
- NodePort:外界访问的端口;如果不指定的话端口会随机生成,通过kubectl get svc获取;这里我的NodePort为30817;
3).访问应用
现在这个应用的pod已经创建好了,也已经通过service暴露出去了,现在就可以根据http://NodeIP:NodePort去访问了;
到这里一个简单的网站部署基本上完成了;能访问到这个网站就没有问题;
七.基本资源概念
- Pod:K8s最小部署单元,一组容器的集合;
- Deployment:最常见的控制器,用于高级别部署和管理Pod
- Service:为一组Pod提供负载均衡,对外提供统一访问入口;
- Label:标签,附加到某个资源上,用于关联对象、查询和筛选;
kubectl get pod --show-labels #可以查看资源标签;
kubectl get pod -l app=my-web #根据标签过滤资源 - Namespace:命名空间,将对象逻辑上隔离,也利于权限控制(RBRC);
1.命名空间的概念
命名空间(Namespace):Kubernetes将资源对象逻辑上隔离,从而形成多个虚拟集群;
k8s命名空间不隔离网络;
namespace在Docker上也有这个概念,他是用来实现容器隔离的,也就是虚拟化必备的几个维度的隔离,文件系统隔离(每个容器都有自己独立的视图);
随着后面我们的应用越来越多(pod,deployment,svc等),查看起来就会非常麻烦,这时我们可以用namespace来划分不同的工作区;
2.命名空间的应用场景
- 根据不同团队划分命名空间
- 根据项目划分命名空概念
- 根据环境话分命名空间
我们公司现在就是根据环境来进行划分namespace,例如dev开发环境,fat测试环境各是一个命名空间,dev下只有开发的项目,fat只有测试的项目,后面想查看开发环境下的应用,直接kubectl get pod -n dev就可以;非常之方便
3.命名空间存在的意义/作用
- 类似工作区,实现分类、便于管理
- 后面可以根据命名空间进行权限管理
4.namespace默认命名空间
kubectl get namespace
- default:默认命名空间,创建资源时没有指定命名空间的话,都会分配到这个命名空间下;查询资源也一样;
- kube-system:k8s集群方面服务的命名空间,主要存放一些k8s相关的组件;
- kube-public:公开的命名空间,谁都可以访问,不受权限的管理;
- kube-node-lease:k8s内部使用的空间,尽量不要删除,以免引发血案;
5.创建并指定命名空间
创建一个命名空间team-a
kubectl create namespace team-a
[root@k8s-master ~]# kubectl create namespace team-a
namespace/team-a created
[root@k8s-master ~]# kubectl get ns
NAME STATUS AGE
default Active 18d
kube-node-lease Active 18d
kube-public Active 18d
kube-system Active 18d
team-a Active 3s
指定命名空间的两种方式:
- 命令行加 -n
- yaml资源元数据里指定namespace字段
例如在team-a命名空间下创建一个pod并查看
[root@k8s-master ~]# kubectl create deployment my-web --image=fandaoshuai/java-demo -n team-a
deployment.apps/my-web created
[root@k8s-master ~]# kubectl get pod -n team-a
NAME READY STATUS RESTARTS AGE
my-web-7b758f45b7-2s6hc 0/1 Running 0 8s
八.资源编排(YAML)
1.YAML文件格式说明
k8s是个容器编排引擎,使用YAML文件编排要部署的应用,因此在学习之前,应先了解YAML语法格式:
- 缩进表示层级关系
- 不支持制表符 “tab” 缩进,使用空格缩进
- 通常开头(层级关系)缩进 2 个空格
- 字符后缩进 1 个空格,如冒号、逗号等
- “- - -” 表示YAML格式,一个文件的开始(可以通过 - - - 将多个yaml文件放进一个yaml进行管理,- - -用于隔离多个yaml文件)
- “#” 注释
2.YAML文件创建资源对象
命令行创建应用的方式主要用于测试
YAML创建应用的方式方便版本管理,长久保存;
1).使用YAML创建deployment应用
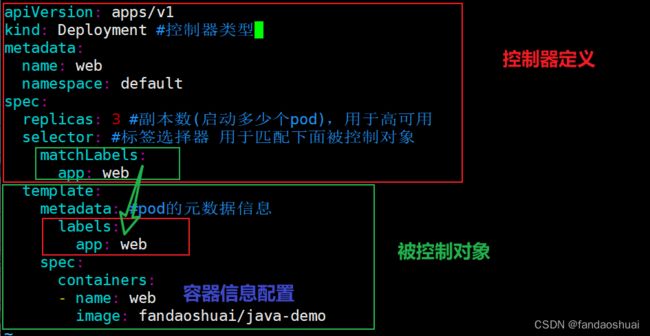
注:matchLabels必须与下面的labels保持一致,否则apply时会报错
这个yaml创建的应用等同于命令创建 kubectl create deployment web --image=lizhenliang/java-demo --replicas=3 -n default
| apiVersion | API版本 |
|---|---|
| kind | 资源类型 |
| metadata | 资源元数据 |
| spec | 资源规格 |
| replicas | 副本数量 |
| selector | 标签选择器 |
| template | Pod模板 |
| metadata | Pod元数据 |
| spec | Pod规格 |
| containers | 容器配置 |
如果大家不清除资源支持的API版本是什么,就是上图的apiVersion这个字段,可以用
kubectl api-resources 来进行查看;
例如deployment的api版本
kubectl api-resources | grep deployments
![]()
可以看到deployment支持的API版本为apps/v1
kubectl api-resources命令解释

NAME:资源名称;
SHORTNAMES:短格式(缩写),例如kubectl get endpoints可以写成kubectl get ep,kubectl get service可以写成kubectl get svc;
APIVERSION:支持的API版本;
NAMESPACED:是否支持命名空间;
KIND:你想使用资源的KIND值;例如上面我想创建一个deployment的资源,那么这个deployment对应的kind值为Deployment;
2).使用YAML创建service应用

提示:service是根据标签去关联pod的
这个yaml创建的service等同于命令创建kubectl expose deployment java-demo --port=80 --target-port=8080 --type=NodePort -n default
| ports | 端口 |
|---|---|
| selector | 标签选择器 |
| type | Service类型 |
3).运行创建好的yaml文件
将你需要创建的资源描述到YAML文件中
- 部署:kubectl apply -f xxx.yaml
- 卸载:kubectl delete -f xxx.yaml
例如部署我上面创建的deployment和service两个yaml
[root@k8s-master data]# kubectl apply -f deployment.yaml
deployment.apps/web created
[root@k8s-master data]# kubectl apply -f service.yaml
service/web666 created
[root@k8s-master data]# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/web-5dc9c9f9d8-55pph 1/1 Running 0 58s
pod/web-5dc9c9f9d8-75dpq 1/1 Running 0 58s
pod/web-5dc9c9f9d8-xkx99 1/1 Running 0 58s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
service/web666 NodePort 10.104.115.222 <none> 80:30603/TCP 54s
删除这两个yaml创建的资源
[root@k8s-master data]# kubectl delete -f deployment.yaml
deployment.apps "web" deleted
[root@k8s-master data]# kubectl delete -f service.yaml
service "web666" deleted
[root@k8s-master data]# kubectl get pod,svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
kubectl apply与create区别
- apply:可以创建或者更新资源
- create:只是创建资源
3.YAML文件中字段太多,记不住怎么办
1).第一种方式:通过官方提供的模板,直接拿过来改

2).第二种方式:用命令生成示例,然后再修改(这种方式适用于所有资源)
场景一:想使用yaml文件创建资源但是不知道怎么写;
可以使用create的方式尝试运行一个deployment,然后导出这个deployment的yaml:
kubectl create deployment my-web --image=fandaoshuai/java-demo -n team-a --dry-run=client -o yaml > xxx.yaml
–dry-run:尝试运行,不实际的进行操作;有clinet/server两个参数可选:这条参数代表在哪里验证,client是在客户端本身kubectl内置的校验方法去验证;server在服务端验证,会把请求提交到apiserver里去验证,默认是client,一般使用client就行;
-o yaml :导出资源信息
[root@k8s-master ~]# kubectl create deployment my-web --image=fandaoshuai/java-demo -n team-a --dry-run=client -o yaml > deployment.yaml
[root@k8s-master ~]# vim deployment.yaml
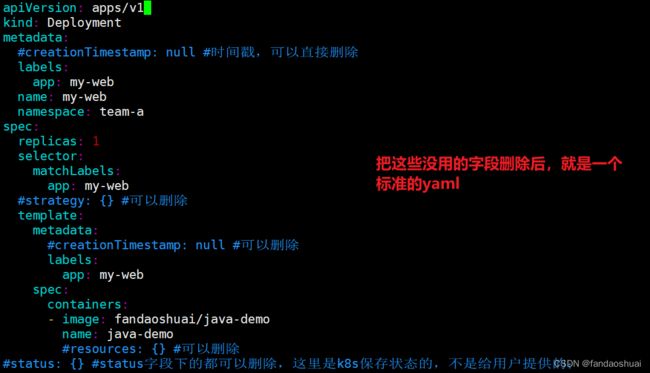
场景二:想查看正在运行pod的资源信息,但是找不到源yaml文件或者本来就不是yaml文件创建的 而是通过命令的方式创建的;
可以使用get的方式导出,然后也可以把没用的字段删除来进行查看;
kubectl get pod -o yaml > xxx.yaml
场景三:如果有某个字段的拼写忘记了,或者不清除某个字段下都有那些字段支持;
可以使用kubectl explain 命令来进行查看
例如在写deployment时忘记了spec都有那些字段
[root@k8s-master ~]# kubectl explain Deployment.spec
KIND: Deployment
VERSION: apps/v1
RESOURCE: spec <Object>
DESCRIPTION:
Specification of the desired behavior of the Deployment.
DeploymentSpec is the specification of the desired behavior of the
Deployment.
FIELDS:
minReadySeconds <integer>
Minimum number of seconds for which a newly created pod should be ready
without any of its container crashing, for it to be considered available.
Defaults to 0 (pod will be considered available as soon as it is ready)
paused <boolean>
Indicates that the deployment is paused.
progressDeadlineSeconds <integer>
The maximum time in seconds for a deployment to make progress before it is
considered to be failed. The deployment controller will continue to process
failed deployments and a condition with a ProgressDeadlineExceeded reason
will be surfaced in the deployment status. Note that progress will not be
estimated during the time a deployment is paused. Defaults to 600s.
replicas <integer>
Number of desired pods. This is a pointer to distinguish between explicit
zero and not specified. Defaults to 1.
revisionHistoryLimit <integer>
The number of old ReplicaSets to retain to allow rollback. This is a
pointer to distinguish between explicit zero and not specified. Defaults to
10.
selector <Object> -required-
Label selector for pods. Existing ReplicaSets whose pods are selected by
this will be the ones affected by this deployment. It must match the pod
template's labels.
strategy <Object>
The deployment strategy to use to replace existing pods with new ones.
template <Object> -required-
Template describes the pods that will be created.
总结
以上就是我通过学习给大家分享出来的k8s基础概念和基本使用;还请大家多多指教;