大话YOLOV5
欢迎来到机器学习的世界
博客主页:卿云阁欢迎关注点赞收藏⭐️留言
本文由卿云阁原创!
本阶段属于练气阶段,希望各位仙友顺利完成突破
首发时间:2021年6月29日
✉️希望可以和大家一起完成进阶之路!
作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
2022年 7月7日 天气晴
最近淮北下了很多天的雨,今天终于晴天了,很开心的,今天也是我第一次走出校门,和几个好朋友一起去凤凰社区吃烧烤、喝啤酒、很nice。
目录
YOLOV3
YOLOV4
YOLOV5的核心基础

YOLOV3
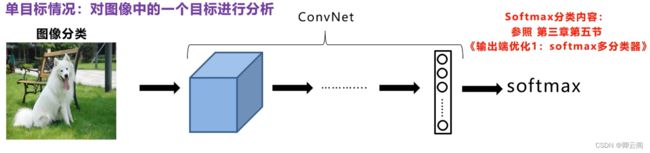
目标检测=目标的定位+分类
图像分类
假设我们的目的是动物分类(小猫、小狗、小猪、背景)最后输出属于四种类别的概率,这。就是我们之前接触到的图像分类。
如果想实现多标签的分类,这时,我们可以使用n个Sigmoid函数进行二分类,比如第一个函数代表是小猫还是背景的概率。
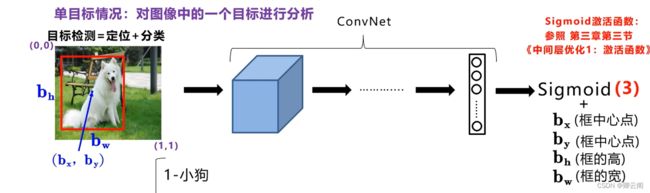
目标检测
目标框
动物+定位,在这里我们可以让神经网络多输出几个单元,比如输出一个目标框。
假设 (bx,by) bh bw (0.4,0.5)0.9 0.55
目标标签
pc表示是否含有目标对象,动物的位置信息,三者的概率。
定位
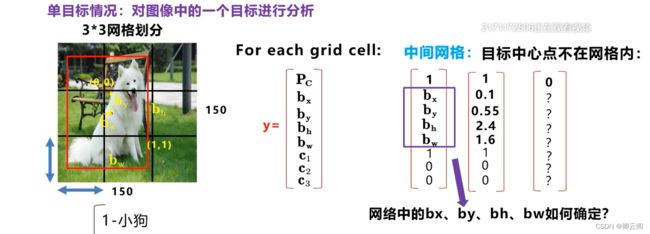
假设图像的宽和高都是150*150像素,假设使用3*3的网格进行划分,在九个网格区域逐一进行定位和分类算法,因此,我们为每一个网格制定了一个目标标签y.
pc表示是否含有目标对象的中心点,目标的位置信息,三者的概率。
bh代表小狗的高度,是相当于单元格网格的比例,比如bh=2.4,就表示2.4个网格的大小。
输入、输出
最后网络输出的特征图的尺寸是3*3*8. 在训练时只要有输入图像和对应的标签y,就可以采用监督学习的方式计算损失函数,从而通过梯度下降反向更新网络参数不断优化网络的预测值
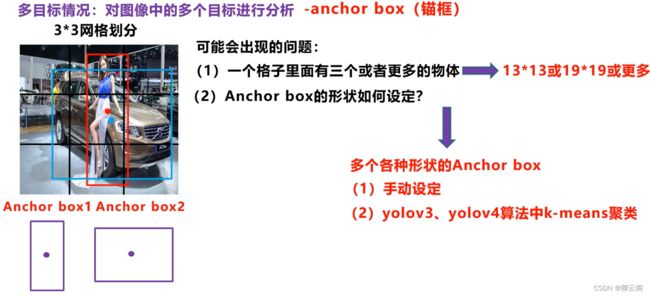
多目标情况-锚框
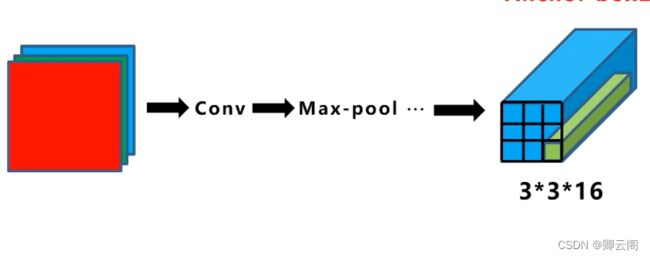
锚框与物体边界框不同,是由人们假想出来的一种框。先设定好锚框的大小和形状,再以图像上某一个点为中心画出矩形框。而在YOLO中,生成规则是将图片分割成mxn个区域,然后在每个格子的中心,按照设定的长宽比等,生成一系列的锚框。这里说一下,设定的长宽,在YOLO中是采用聚类的方法产生的,而在YOLOV5中具体为采用k-means聚类+遗传算法计算得到。
为了解决在同一个网格内有多个物体的中心点。我们首先定义两个不同形状的锚框,我们要做的就是把预测的结果和两个锚框相关联。在实际应用中可以采用更多的锚框,这里只有两个目标,我们暂时只定义两个锚框此时的目标标签y,会发生变化。还有一个问题需要解决,不同的物体如何于与锚框确定关系。实际上我们是计算每个锚框和目标框的iou。将iou最大的锚框分配给目标框。
此时的输入、输出
可能出现的问题
检测细节
这里我们没有采用最大池化的方式,而是采用了卷积的方式。
多尺度融合
为了避免前面模特和车在一个网格内的情况。
输入端的图片的变换
(1)强制的变换
(2) 把图片放到新建的黑色全零矩阵的中心位置
这两种方式,并没有对错之分,但是要保证训练和测试的处理方式一样。 一般情况下比较推荐第二种方式。
锚框的计算机制
- 为了方便计算,bx的变成到图像边界的距离。
- 预测网络就是不断计算实际标签和预测标签的距离,从而不断的梯度下降,不断的更新网络的参数,减少两者之间的差距。
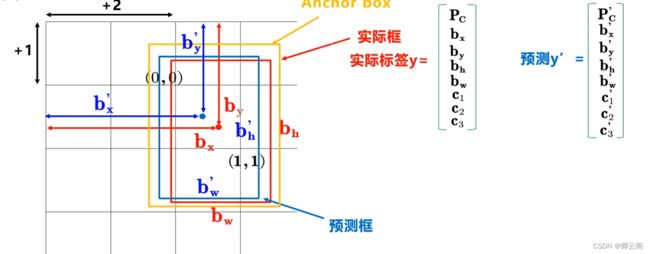
- 在这三个框中,红色的框是人工标注的,是已知的,黄色的框是算法提前设置好的也是已知的,只有蓝色的预测框是不断的变化的。
- 如何得到预测框得信息?本质上,黄色得锚框是蓝色得预测框和红色的实际框之间的桥梁,预测框在锚框的基础上和实际框通过iou进行关联,并且在锚框的基础上预测出预测框的大小,并进行修正。
- 如何得到预测标签?在这里,我们并不是直接的得到bx,by 等的值,而是基于tx,ty,th,tw这里的tx,ty 表示预测框中心点的坐标的偏移量,距离单元格左边和上边的距离,但是网络直接预测的值有可能大于1,所以通常在tx,ty的外面采用激活函数Sigmoid进行处理把它们约束到0—1之间。
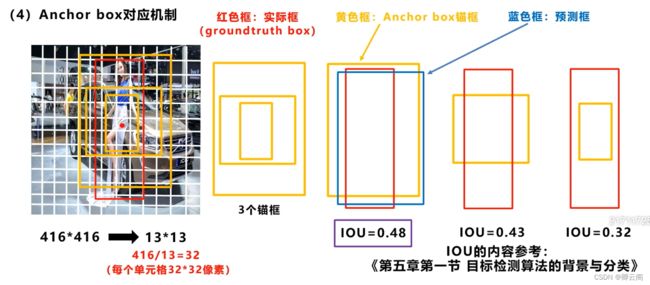
锚框的对应机制
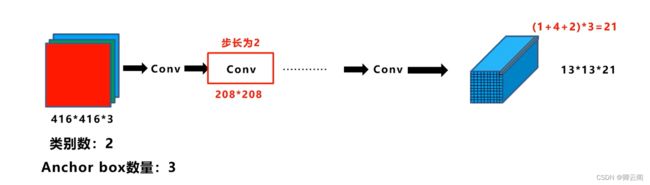
我们对下面的图片使用13*13的网格进行划分,这样每个单元格的长和宽就是32*32像素,我们将人的目标框画出来,我们看到目标的中心点在第六行,第八列的网格当中,在yolov3中会对每个单元格设置3个不同大小的锚框。神经网络对目标检测预测的值是tx,ty,tw,th,在这里我们有了三个固定的锚框,因此会产生3个预测框。在训练时我们会分别计算三个锚框和实际框之间的iou,选择iou大的锚框产生的预测框进行计算和修正
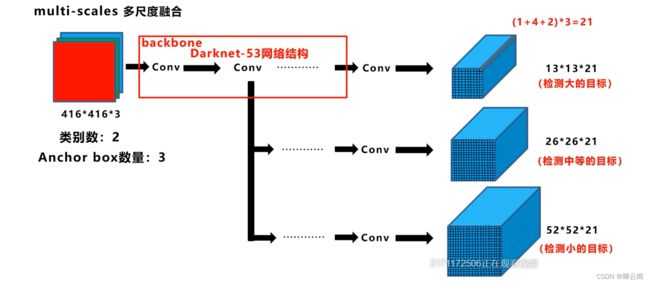
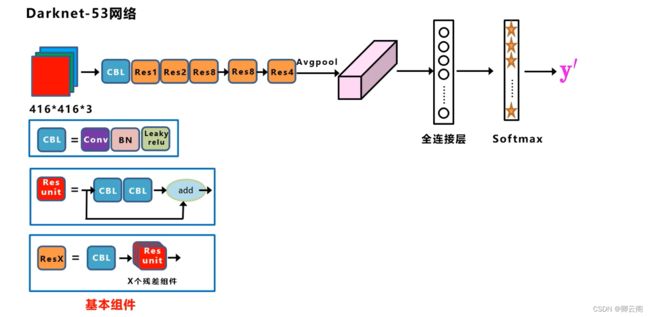
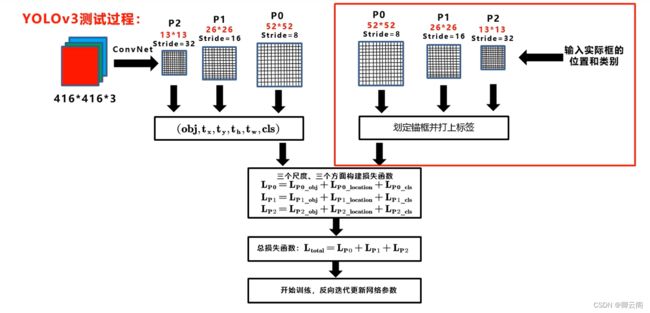
yolov3的网络结构
红色部分是主干网络
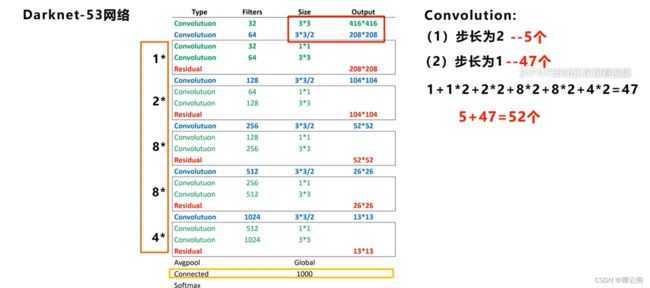
下面这张网络是主干网络的整体的分布,第一列是网络的类型,第二列是卷积核的数量,第三列是卷积核的大小,第四列是输入输出矩阵的大小。
- 第一层来看:大部分都是卷积,我们可以看到输入的尺寸是416*416,所以n=416,填充的大小在卷积下采样的时候默认是1,f=3,s=2,我们将数值代入公式中.
- 我们把步长为二的用蓝色的标出来,步长为一的卷积操作我们用绿色的部分表示,网络结构旁边的1,2,8,8,4表示重复连接的组件,比如中间的2表示两个卷积层+一个残差层之后再连接两个卷积层+一个残差层。52+1=53
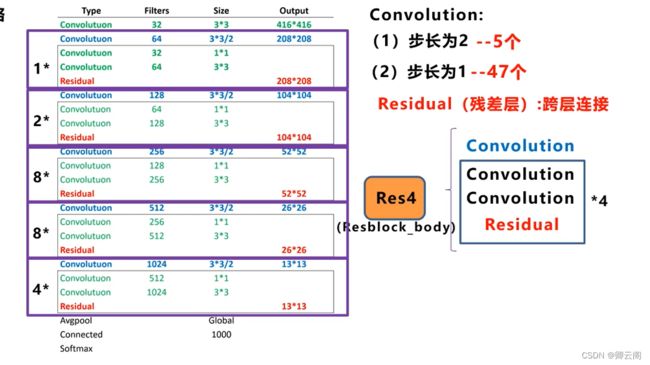
- 从整体来看,网络主要是由卷积层和残差层组成,残差层是参照Resnet网络的方式进行跨层连接。
- 残差组件的组成=用于降维的卷积层+两个卷积层=残差层
- 这里的卷积层是简写,可以简写成CBL。
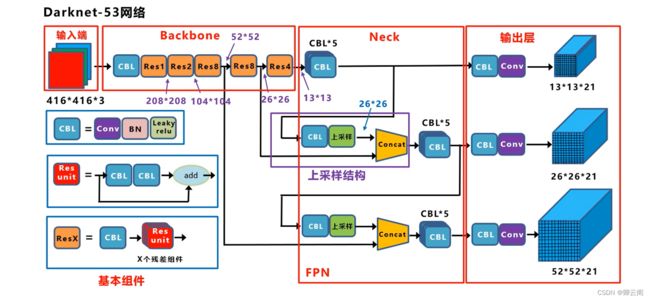
- 为了更好的理解我们把网络的结构进一步改写网络的输入是一个416*416*3的彩色图像在经过一个CBL卷积层后面再加上前面讲的5大组件,最后在经过一个平均池化层,一个全连接层,和一个Softmax,这就是用于分类的网络结构,此外我们还需要完成后面的目标检测任务,这里我们将后面的部分全部去掉,加上我们前面所说的三种特征图这样就可以得到完整的网络结构。
- 我们可以把整个网络分为4个部分,现在我主要介绍下面的三部分,Backbone有三个基本组件,第一个是CBL卷积层,第二个是由两个卷积层和一个跨层连接构成的一个残差组件,第三个是一个卷积层和n个残差组件共同构成了一个Resx结构,在主干网络中有5个步长为2的卷积层,在主干网络的不同的阶段我们可以看到特征图尺寸下降的变化
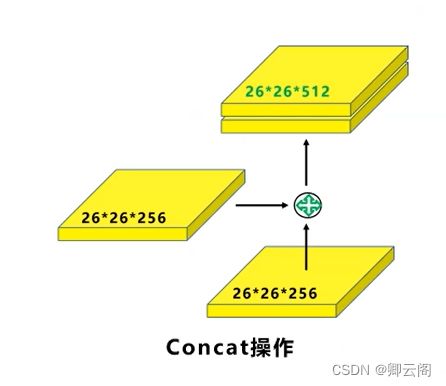
- Concat操作(输入和输出的尺寸不变但是通道的数量进行连接
yolov3的网络结构的立体视角
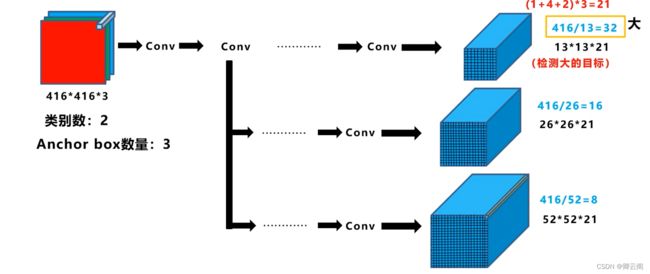
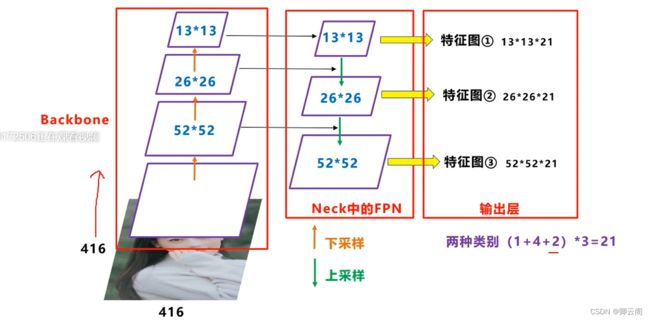
- 首先输入是416*416大小的彩色图像,经过主干网络提取特征可以得到不同阶段的52*52,26*26,13*13的特征图的信息
yolov3的训练过程
- 损失函数
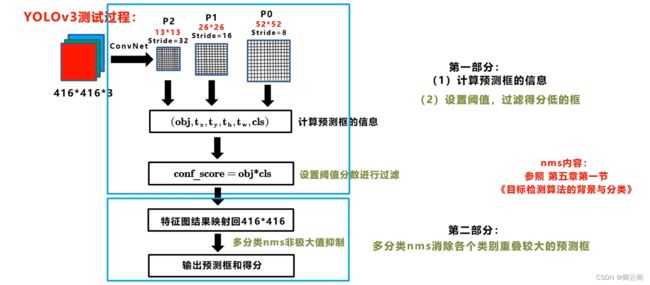
- 实际使用 第一步计算预测框的信息,设置阈值,计算得分。 到了这里我们得到了三个特征图上预测框的信息,但是现在的框可能还是太多了, 第二步 消除重叠度很高的框 将三个特征图上的结果映射到输入图像上,这样在原始的图像上就会有多种类别的多个框了
YOLOV4
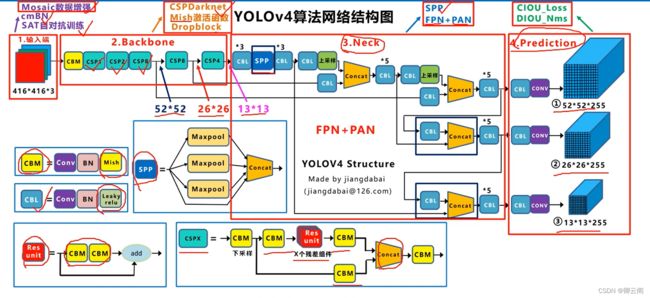
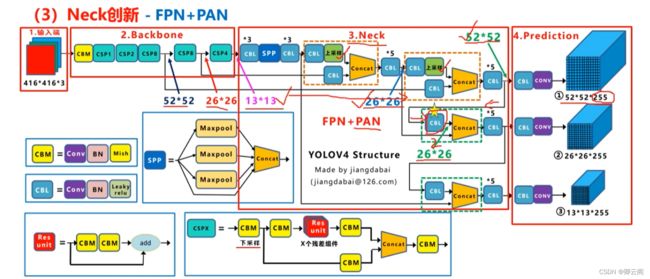
- 在yolov4中多了一种Mish的激活函数,我们把其定义成CBM,一共包括了五种基础组件。Yolov4的结构图和Yolov3相比,因为多了CSP结构,PAN结构,如果单纯看可视化流程图,会觉得很绕,不过在绘制出上面的图形后,会觉得豁然开朗,其实整体架构和Yolov3是相同的,不过使用各种新的算法思想对各个子结构都进行了改进。
- 输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练。
- BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock。
- Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构。
- Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms。
输入端创新
Mosaic数据增强 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
BackBone创新
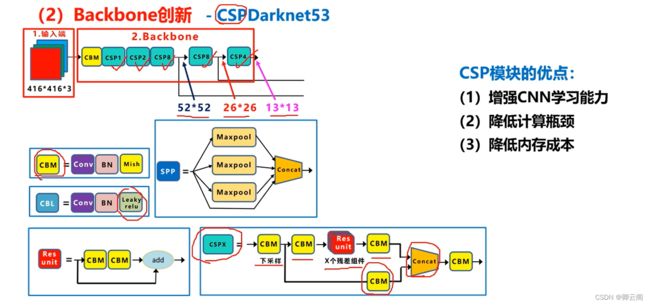
(1)CSPDarknet53
CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。每个CSP模块前面的卷积核的大小都是3*3,stride=2,因此可以起到下采样的作用。因为Backbone有5个CSP模块,输入图像是608*608,所以特征图变化的规律是:608->304->152->76->38->19
经过5次CSP模块后得到19*19大小的特征图。
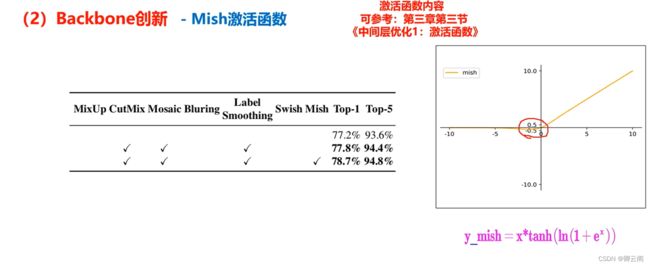
(2)Mish激活函数
CBL和CBM的最大的不同在于激活函数的不同。CBM使用了mish作为激化函数。
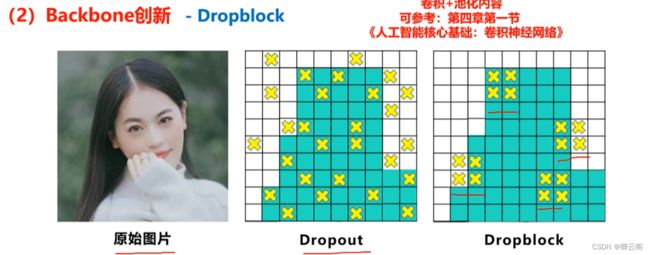
(3)Dropblock
本质是减少神经元的数量使得网络结构更简单,那么为什么不在设计时就把它设计的少一些省的后面还需要采用Dropblock的方式进行删除,这里主要是因为Dropblock的随机失活。可以避免网络对某个特征或某个样本过于依赖,大量的用于全连接的网络当中。
而现在的网络结构基本上都是卷积层,研究者发现直接将Dropblock应用到卷积者层中的效果并不是很好。比如在网络中对左边的原始图片进行卷积操作,比如在网络中对左边的原始图片进行卷积操作,在这个过程中可以进行Dropblock操作我们可以看到图像中的某些位置
被丢弃了。所以右图Dropblock的研究者则干脆整个局部区域进行删减丢弃。
这种方式其实是借鉴2017年的cutout数据增强的方式,cutout是将输入图像的部分区域清零,而Dropblock则是将Cutout应用到每一个特征图。而且并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率。
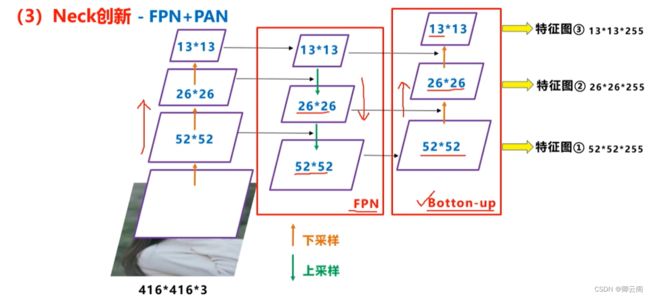
Neck创新
Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。
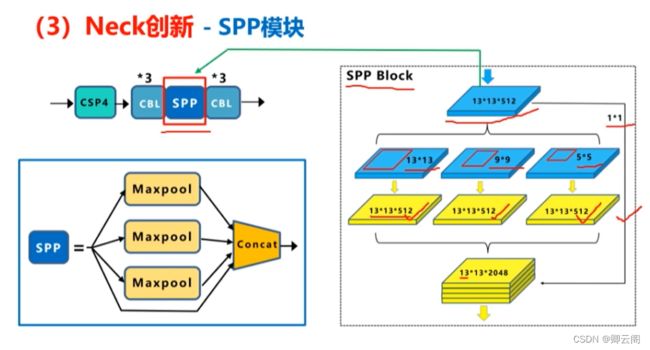
(1)SPP模块
SPP模块中,使用k={1*1 ,5*5,9*9,13*13}的最大池化的方式,再将不同尺度的特征图进行Concat操作。这里最大池化采用padding操作,移动的步长为1,比如13×13的输入特征图,使用5×5大小的池化核池化,padding=2,因此池化后的特征图仍然是13×13大小。
(2)FPN+PAN
Yolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:
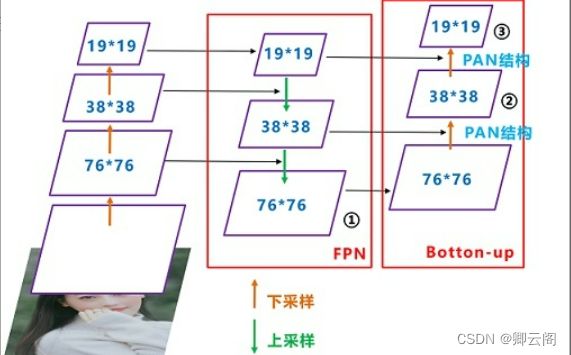
CSPDarknet53中讲到,每个CSP模块前面的卷积核都是3*3大小,步长为2,相当于下采样操作。因此可以看到三个紫色箭头处的特征图是76*76、38*38、19*19。
以及最后Prediction中用于预测的三个特征图:①76*76*255,②38*38*255,③19*19*255。
我们也看下Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。
Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。
其中包含两个PAN结构。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。
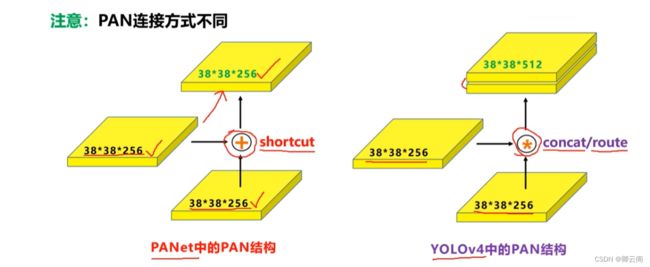
原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用concat(route)操作,特征图融合后的尺寸发生了变化。
Prediction创新
在这方面主要是两个方面的改进,对回归损失函数创新使用了CIOU_loss,对nms的方式的改进DIOU_nms。
(1)CIOU_loss
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。
再来综合的看下各个Loss函数的不同点:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
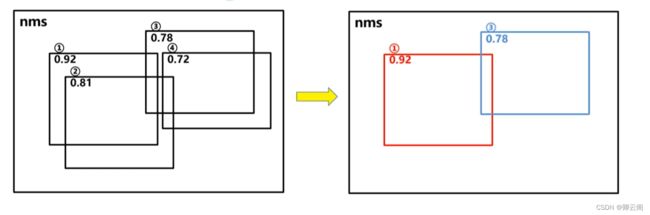
(2)DIOU_nms
当网络训练好之后进行前向推理时,一般会有很多多余的目标框,比如像左图这样,一般情况下,我们会用nms将多余的框删除留下最准确的框,nms主要就是基于iou
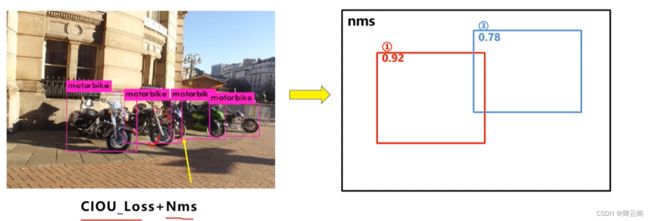
在下图重叠的摩托车检测中,中间的摩托车因为考虑边界框中心点的位置信息,也可以回归出来。因此在重叠目标的检测中,DIOU_nms的效果优于传统的nms。
YOLOV5的核心基础
众所周知,YOLOv5 算法是在 YOLOv4 和 YOLOv3 的基础 上发展而来,YOLOv5 按大小分为四个模型yolov5s、yolov5m、yolov5l、yolov5x。和 YOLOv4 相比,YOLOv5 的架构小 了大约 90%,在准确度上,YOLOv5 的表现优于目前市场YOLOv3 和 YOLOv4 算法。废话少说,我们开始进入我们的知识干货部分。
实际上yolov5s、yolov5m、yolov5l、yolov5x的骨架网络都是相同的,其区别在于深度因子和宽度因子。Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的3种都是在此基础上不断加深,不断加宽。
效果图的展示:
YOLOv5 的网络结构
YOLOv5 的网络结构图,分为输入端,Backbone,Neck 和 Prediction 四个部分.
输入端:包括Mosaic 数据增强、自适应图片缩放、 自适应锚框计算。
Backbone:是一个卷积神经网络,对输入的图片提取特征,包括 Focus 结构、CSP 结 构。
Neck:通常使用 SSD 或者 FPN 等方法对特征图进行混合或者组合,形成一些更为复杂的 特征,包括 FPN+PAN 结 构。
Prediction:d用于对图像特征进行预测,生成边界框并预测类别,包括GIOU_Loss 结构。
输入端
Input 端包含 Mosaic 数据增强、自适应锚框计算 和自适应图片缩放。
1.首先我们需要输入图片
把图片放到网络里,图片会自动改变相应的大小,且改变的大小是可以变化的。(V1不可改变其大小,因为全连接层的存在) ,默认情况下图片的大小会被修改为608*608*3。
2.数据增强
yolov5里提供了13种数据增强方式,这个文件夹里是整个项目的参数配置。
YOLOv5在输入端的数据增强方法上同 YOLOv4一样,参考2019年底提出的CutMix数据增强的方式,不同于CutMix的是,Mosaic数据增强则采用了4张图片,每次读取 4 张图片,然后依次将 4 张图片通过随机缩放、随机裁剪、随机排布的方式进行拼接, 这种随机机制丰富了检测目标的背景并且丰富了数据集样本,以便网络可以从增强后的图像中提取到更多的特征,使得网络具有更好的鲁棒性。
2.自适应锚框计算
自适应锚框计算,不同于YOLOv3、YOLOv4 中通过单独的程序来计算初始锚框的值。 在YOLOv5 的网络训练中将计算初始锚框功能嵌入到代码中,在设定的初始锚框上输出预测锚框,然后计算两者误差,,再反向更新,迭代网络参数, 自适应的计算最佳锚框值。
3.自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。对原始图像自适应的添加最少的黑边。
自适应图片缩放是指将不同长宽的图片统一 缩放到一个标准尺寸,然后再当作数据集用来检测处理。图片缩放后,如果图片两边填充的黑边多, 则存在信息冗余,影响速度。对此 YOLOv5 进行了 改修改了 letterbox 函数,使得原始图片能够自 适应减少信息冗余,即减少黑边。可以在推理时降低计算量,提高目标检测的速度。
Backbone
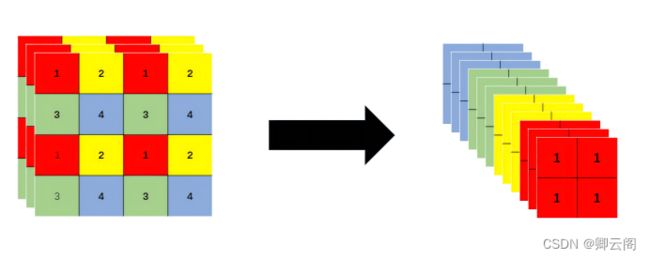
(1)Focus结构
如下图所示
4*4*3的图像切片后变成2*2*12的特征图。
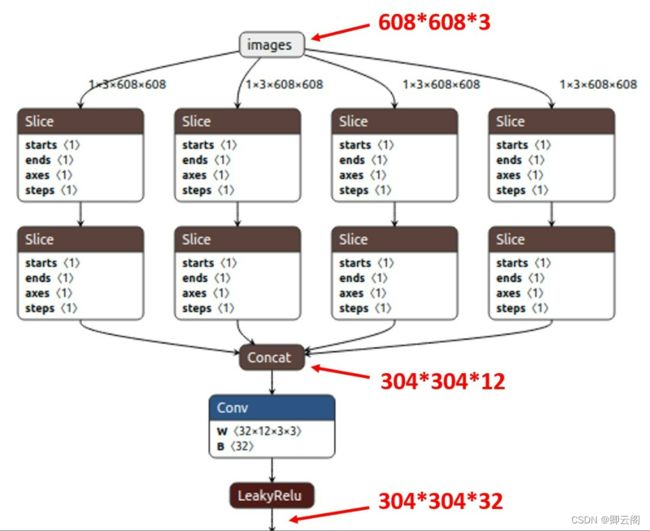
以Yolov5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。
(2)CSP结构
Yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
Cross Stage Partial(CSP)结构的设计初衷是减 少冗余计算量和增强梯度。在 YOLOv5 中设计了两 种不同的 CSP 结构,以 YOLO5s 网络为例,通过 图 1 可以看出,CSP1_X 结构应用于 Backbone 主干 网络,另一种 CSP2_X 结构则应用于 Neck 中。
Neck
YOLOv5 的 Neck 结构和 YOLOv4 的一样,均 用了 FPN+PAN 的结构,不同的是 YOLOv5 网络中 的其他部分进行了调整。如图 5 所示,在 FPN 层 的后面还添加了一个自底向上的特征金字塔,包括 2 个 PAN 结构。YOLOv5 网络结构通过这种方式结 合,FPN 层自顶向下传递强语义特征,PAN 层自底向上传递强定位特征,从不同的主干层对不同的 检测层进行参数聚合,进一步提高特征提取的能力。Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
Prediction
目标检测任务的损失函数一般由 Classification Loss(分类损失函数)和 Bounding Box Regression Loss(回归损失函数)2 部分构成。Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。