学习笔记 Graph Neural Network (李宏毅 机器学习)
Graph Neural Networks
Introduction
How to embed node into a feature space using convolution?
-
Solution 1: Generalize the concept of convolution (correlation) to graph >>
Spatial-based convolution -
Solution 2: Back to the definition of convolution in signal processing >>
Spectral-based convolution
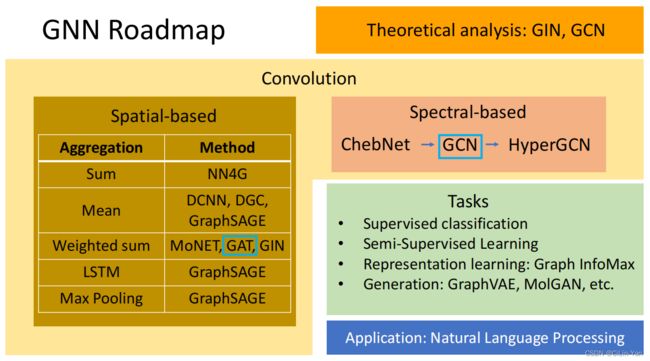
Roadmap
Tasks, Dataset
Tasks
- Semi-supervised node classification
- Regression
- Graph classification
- Graph representation learning
- Link prediction
Common dataset
CORA: citation network. 2.7k nodes and 5.4k linksTU-MUTAG: 188 molecules with 18 nodes on average
Spatial-based GNN
Terminology:
Aggregate: 用 neighbor feature update 下一層的 hidden state.Readout: 把所有 nodes 的 feature 集合起來代表整個 graph.
NN4G (Neural Networks for Graph)
Aggregate 使用 sum.
Readout 对每一个 hidden layer 的 mean of nodes’ feature 做 weighted sum 得到 prediction.
DCNN (Diffusion-Convolution Neural Network )
Aggregate 使用 mean
Readout 对每一个 hidden layer 的 nodes’ feature 做concatenate 得到一个 matrix, 对这个matrix 做 concatenate 之后与 weighted 相乘得到 prediction.
DGC (Diffusion Graph Convolution)
Readout 的时候对每个 hidden layer 的 matrix 做 add 而不是 concatenate.
MoNET (Mixture Model Networks)
-
Define a measure on node ‘distances’
-
Use weighted sum (mean) instead of simply summing up (averaging) neighbor features.
h 3 1 = w ( u ^ 3 , 0 ) × h 0 0 + w ( u ^ 3 , 2 ) × h 2 0 + w ( u ^ 3 , 2 ) × h 4 0 h_{3}^{1}=w\left(\hat{u}_{3,0}\right) \times h_{0}^{0}+w\left(\hat{u}_{3,2}\right) \times h_{2}^{0}+w\left(\hat{u}_{3,2}\right) \times h_{4}^{0} h31=w(u^3,0)×h00+w(u^3,2)×h20+w(u^3,2)×h40
w ( ⋅ ) w(\cdot) w(⋅) is a NN, u ^ \hat{u} u^ is a transform from u u u, where u ( x , y ) = ( 1 deg ( x ) , 1 deg ( y ) ) ⊤ \mathbf{u}(x, y)=\left(\frac{1}{\sqrt{\operatorname{deg}(\mathrm{x})}}, \frac{1}{\sqrt{\operatorname{deg}(\mathrm{y})}}\right)^{\top} u(x,y)=(deg(x)1,deg(y)1)⊤
GraphSAGE
-
SAmple and aggreGatE -
Can work on both transductive and inductive setting
-
GraphSAGE learns how to embed node features from neighbors
-
AGGREGATION: mean, max-pooling, or LSTM
GAT (Graph Attention Networks)
✓ \checkmark ✓ Input: node features h = { h ⃗ 1 , h ⃗ 2 , … , h ⃗ N } , h ⃗ i ∈ R F \mathbf{h}=\left\{\vec{h}_{1}, \vec{h}_{2}, \ldots, \vec{h}_{N}\right\}, \vec{h}_{i} \in \mathbb{R}^{F} h={h1,h2,…,hN},hi∈RF :
✓ \checkmark ✓ Calculate energy: e i j = a ( W h ⃗ i , W h ⃗ j ) e_{i j}=a\left(\mathbf{W} \vec{h}_{i}, \mathbf{W} \vec{h}_{j}\right) eij=a(Whi,Whj)
✓ \checkmark ✓ Attention score (over the neighbors)
α i j = exp ( LeakyReLU ( a → T [ W h ⃗ i ∥ W h ⃗ j ] ) ) ∑ k ∈ N i exp ( LeakyReLU ( a → T [ W h ⃗ i ∥ W h ⃗ k ] ) ) \alpha_{i j}=\frac{\exp \left(\operatorname{LeakyReLU}\left(\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}_{j}\right]\right)\right)}{\sum_{k \in \mathcal{N}_{i}} \exp \left(\operatorname{LeakyReLU}\left(\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}_{k}\right]\right)\right)} αij=∑k∈Niexp(LeakyReLU(aT[Whi∥Whk]))exp(LeakyReLU(aT[Whi∥Whj]))
GIN (Graph Isomorphism Network)
-
A GNN can be at most as powerful as WL isomorphic test
-
Theoretical proofs were provided
-
h v ( k ) = MLP ( k ) ( ( 1 + ϵ ( k ) ) ⋅ h v ( k − 1 ) + ∑ u ∈ N ( v ) h u ( k − 1 ) ) h_{v}^{(k)}=\operatorname{MLP}^{(k)}\left(\left(1+\epsilon^{(k)}\right) \cdot h_{v}^{(k-1)}+\sum_{u \in \mathcal{N}(v)} h_{u}^{(k-1)}\right) hv(k)=MLP(k)((1+ϵ(k))⋅hv(k−1)+∑u∈N(v)hu(k−1))
-
Sum instead of mean or max 使用 sum 比 mean 和 max 好
-
MLP instead of 1-layer
Graph Signal Processing and Spectral-based GNN
Spectral Graph Theory
✓ \checkmark ✓ Graph: G = ( V , E ) , N = ∣ V ∣ G=(V, E), N=|V| G=(V,E),N=∣V∣
✓ A ∈ R N × N \checkmark A \in \mathbb{R}^{N \times N} ✓A∈RN×N, adjacency matrix (weight matrix).
A i , j = 0 if e i , j ∉ E , else A i , j = w ( i , j ) A_{i, j}=0 \text { if } e_{i, j} \notin E \text {, else } A_{i, j}=w(i, j) Ai,j=0 if ei,j∈/E, else Ai,j=w(i,j)
✓ \checkmark ✓ We only consider undirected graph
✓ D ∈ R N × N \checkmark D \in \mathbb{R}^{N \times N} ✓D∈RN×N, degree matrix
D i , j = { d ( i ) if i = j (Sum of row i in A ) 0 if i ≠ j D_{i, j}= \begin{cases}d(i) & \text { if } i=j \quad \text { (Sum of row } i \text { in } A \text { ) } \\ 0 & \text { if } i \neq j\end{cases} Di,j={d(i)0 if i=j (Sum of row i in A ) if i=j
✓ f : V → R N \checkmark f: V \rightarrow \mathbb{R}^{N} ✓f:V→RN, signal on graph (vertices). f ( i ) f(i) f(i) denotes the signal onvertex i i i
✓ \checkmark ✓ Graph Laplacian L = D − A , L ⩾ 0 L=D-A, L \geqslant 0 L=D−A,L⩾0 (Positive semidefinite)
✓ L \checkmark L ✓L is symmetric (for undirected graph)
✓ L = U Λ U T \checkmark L=U \Lambda U^{\mathrm{T}} ✓L=UΛUT (spectral decomposition)
✓ Λ = diag ( λ 0 , … , λ N − 1 ) ∈ R N × N \checkmark \Lambda=\operatorname{diag}\left(\lambda_{0}, \ldots, \lambda_{N-1}\right) \in \mathbb{R}^{N \times N} ✓Λ=diag(λ0,…,λN−1)∈RN×N
✓ U = [ u 0 , … , u N − 1 ] ∈ R N × N \checkmark U=\left[u_{0}, \ldots, u_{N-1}\right] \in \mathbb{R}^{N \times N} ✓U=[u0,…,uN−1]∈RN×N, orthonormal
✓ λ l \checkmark \lambda_{l} ✓λl is the frequency, u l u_{l} ul is the basis corresponding to λ l \lambda_{l} λl
图卷积: y = g θ ( L ) x y=\operatorname{g}_{\theta}(L) x y=gθ(L)x
Lemma 3 Let G G G be a weighted graph, and L \mathscr{L} L the graph Laplacian of G G G. Fix an integer s > 0 s>0 s>0, and pick vertices m m m and n n n. Then ( L s ) m , n = 0 \left(\mathscr{L}^{s}\right)_{m, n}=0 (Ls)m,n=0 whenever d G ( m , n ) > s . d_{G}(m, n)>s . dG(m,n)>s.
ChebNet
Use polynomial to parametrize g θ ( L ) \mathrm{g}_{\theta}(L) gθ(L)
g θ ( L ) = ∑ k = 0 K θ k L k g_{\theta}(L)=\sum_{k=0}^{K} \theta_{k} L^{k} gθ(L)=k=0∑KθkLk
✓ \checkmark ✓ Now it is K-localized
✓ \checkmark ✓ Parameters to be learnt: O ( K ) O(K) O(K)
Problem: Time complexity: O ( N 2 ) O\left(N^{2}\right) O(N2) Use a polynomial function that can be computed recursively from L L L
✓ \checkmark ✓ Chebyshev polynomial
T 0 ( x ) = 1 , T 1 ( x ) = x , T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) , x ∈ [ − 1 , 1 ] T_{0}(x)=1, T_{1}(x)=x, T_{k}(x)=2 x T_{k-1}(x)-T_{k-2}(x), x \in[-1,1] T0(x)=1,T1(x)=x,Tk(x)=2xTk−1(x)−Tk−2(x),x∈[−1,1]
Define Λ ~ = 2 Λ λ max − I , λ ~ ∈ [ − 1 , 1 ] \displaystyle \widetilde{\Lambda}=\frac{2 \Lambda}{\lambda_{\max }}-\mathrm{I}, \tilde{\lambda} \in[-1,1] Λ =λmax2Λ−I,λ~∈[−1,1], we have:
T 0 ( Λ ~ ) = I , T 1 ( Λ ~ ) = Λ ~ , T k ( Λ ~ ) = 2 Λ ~ T k − 1 ( Λ ~ ) − T k − 2 ( Λ ~ ) T_{0}(\widetilde{\Lambda})=\mathrm{I}, T_{1}(\widetilde{\Lambda})=\widetilde{\Lambda}, T_{k}(\widetilde{\Lambda})=2 \widetilde{\Lambda} T_{k-1}(\widetilde{\Lambda})-T_{k-2}(\widetilde{\Lambda}) T0(Λ )=I,T1(Λ )=Λ ,Tk(Λ )=2Λ Tk−1(Λ )−Tk−2(Λ )
and then,
y = g θ ′ ( L ) x = ∑ k = 0 K θ k ′ T k ( L ~ ) x = θ 0 ′ T 0 ( L ~ ) x + θ 1 ′ T 1 ( L ~ ) x + θ 2 ′ T 2 ( L ~ ) x + ⋯ + θ K ′ T K ( L ~ ) x = θ 0 ′ x ˉ 0 + θ 1 ′ x ˉ 1 + θ 2 ′ x ˉ 2 + ⋯ + θ K ′ x ˉ K = [ x ˉ 0 x ˉ 1 … x ˉ K ] [ θ 0 ′ θ 1 ′ … θ K ′ ] \begin{aligned} y=g_{\theta^{\prime}}(L) x &=\sum_{k=0}^{K} \theta_{k}^{\prime} T_{k}(\tilde{L}) x \\ &=\theta_{0}^{\prime} T_{0}(\widetilde{L}) x+\theta_{1}^{\prime} T_{1}(\widetilde{L}) x+\theta_{2}^{\prime} T_{2}(\widetilde{L}) x+\cdots+\theta_{K}^{\prime} T_{K}(\widetilde{L}) x \\ &=\theta_{0}^{\prime} \bar{x}_{0}+\theta_{1}^{\prime} \bar{x}_{1}+\theta_{2}^{\prime} \bar{x}_{2}+\cdots+\theta_{K}^{\prime} \bar{x}_{K} \\ &=\left[\begin{array}{llll} \bar{x}_{0} & \bar{x}_{1} & \ldots & \bar{x}_{K} \end{array}\right]\left[\begin{array}{lll} \theta_{0}^{\prime} & \theta_{1}^{\prime} & \ldots \theta_{K}^{\prime} \end{array}\right] \end{aligned} y=gθ′(L)x=k=0∑Kθk′Tk(L~)x=θ0′T0(L )x+θ1′T1(L )x+θ2′T2(L )x+⋯+θK′TK(L )x=θ0′xˉ0+θ1′xˉ1+θ2′xˉ2+⋯+θK′xˉK=[xˉ0xˉ1…xˉK][θ0′θ1′…θK′]
where x ˉ 0 = x , x ˉ 1 = L ~ x , x ˉ k = 2 L ~ x ˉ k − 1 − x ˉ k − 2 \bar{x}_{0}=x, \bar{x}_{1}=\tilde{L} x, \bar{x}_{k}=2 \tilde{L} \bar{x}_{k-1}-\bar{x}_{k-2} xˉ0=x,xˉ1=L~x,xˉk=2L~xˉk−1−xˉk−2
Calculating x ˉ k = 2 L ~ x ˉ k − 1 − x ˉ k − 2 \bar{x}_{k}=2 \tilde{L} \bar{x}_{k-1}-\bar{x}_{k-2} xˉk=2L~xˉk−1−xˉk−2 cost O ( E ) O(E) O(E), Total complexity: O ( K E ) O(K E) O(KE).
GCN
y = g θ ′ ( L ) x = ∑ k = 0 K θ k ′ T k ( L ~ ) x , K = 1 y = g θ ′ ( L ) x = θ 0 ′ x + θ 1 ′ L ~ x = θ 0 ′ x + θ 1 ′ ( 2 L λ max − I ) x = θ 0 ′ x + θ 1 ′ ( L − I ) x = θ 0 ′ x − θ 1 ′ ( D − 1 2 A D − 1 2 ) x = θ ( I + D − 1 2 A D − 1 2 ) x \begin{aligned} y=g_{\theta^{\prime}}(L) x &=\sum_{k=0}^{K} \theta_{k}^{\prime} T_{k}(\tilde{L}) x, K=1 \\ y=g_{\theta^{\prime}}(L) x &=\theta_{0}^{\prime} x+\theta_{1}^{\prime} \tilde{L} x \\ &=\theta_{0}^{\prime} x+\theta_{1}^{\prime}\left(\frac{2 \mathrm{~L}}{\lambda_{\max }}-\mathrm{I}\right) x \\ &=\theta_{0}^{\prime} x+\theta_{1}^{\prime}(L-\mathrm{I}) x \\ &=\theta_{0}^{\prime} x-\theta_{1}^{\prime}\left(D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\right) x \\ &=\theta\left(I+D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\right) x \end{aligned} y=gθ′(L)xy=gθ′(L)x=k=0∑Kθk′Tk(L~)x,K=1=θ0′x+θ1′L~x=θ0′x+θ1′(λmax2 L−I)x=θ0′x+θ1′(L−I)x=θ0′x−θ1′(D−21AD−21)x=θ(I+D−21AD−21)x
where L ~ = 2 L λ max − I \displaystyle \tilde{\mathrm{L}}=\frac{2 \mathrm{~L}}{\lambda_{\max }}-\mathrm{I} L~=λmax2 L−I, λ max ≈ 2 \lambda_{\max } \approx 2 λmax≈2, L = I − D − 1 2 A D − 1 2 L=I-D^{-\frac{1}{2}} A D^{-\frac{1}{2}} L=I−D−21AD−21, θ = θ 0 ′ = − θ 1 ′ \theta=\theta_{0}^{\prime}=-\theta_{1}^{\prime} θ=θ0′=−θ1′
renormalization trick: I N + D − 1 2 A D − 1 2 → D ~ − 1 2 A ~ D ~ − 1 2 I_{N}+D^{-\frac{1}{2}} A D^{-\frac{1}{2}} \rightarrow \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} IN+D−21AD−21→D~−21A~D~−21
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)}=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}\right) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
Can be rewritten as: (conclusion)
h v = f ( 1 ∣ N ( v ) ∣ ∑ u ∈ N ( v ) W x u + b ) , ∀ v ∈ V h_{v}=f\left(\frac{1}{|\mathcal{N}(v)|} \sum_{u \in \mathcal{N}(v)} W x_{u}+b\right), \quad \forall v \in \mathcal{V} hv=f⎝⎛∣N(v)∣1u∈N(v)∑Wxu+b⎠⎞,∀v∈V
Discussion
✓ \checkmark ✓ For any initial value X ( 0 ) X^{(0)} X(0), the output of l-th layer X ( l ) X^{(l)} X(l) satisfies d M ( X ( l ) ) ≤ d_{\mathcal{M}}\left(X^{(l)}\right) \leq dM(X(l))≤ ( s λ ) l d M ( X ( 0 ) ) (s \lambda)^{l} d_{\mathcal{M}}\left(X^{(0)}\right) (sλ)ldM(X(0)). In particular, d M ( X ( l ) ) d_{\mathcal{M}}\left(X^{(l)}\right) dM(X(l)) exponentially converges to 0 when s λ < 1 s \lambda<1 sλ<1. 所以,如果 s λ < 1 s \lambda<1 sλ<1,多层的MLP表现不如浅层的MLP.
✓ \checkmark ✓ In reality, graph is usually not too sparse, so GCN is still applicable
✓ \checkmark ✓ Find the sweet-spot to make the singular value of the weight not too small and not too big
✓ \checkmark ✓ Remedy for over-smoothing: sample edges while training to make the graph sparser
✓ \checkmark ✓ DropEdge Randomly drop the edge of input graph with probability p p p, 可上避免 over-smoothing 的問題
- 每一層都用同一個 drop 過的 adjacency matrix
- 每一層都用不同的 drop 過的 adjacency matrix
Online Resources
✓ \checkmark ✓ PyG (PyTorch Geometric) is a library built upon PyTorch to easily write and train Graph Neural Networks (GNNs) for a wide range of applications related to structured data.
✓ \checkmark ✓ DEEP GRAPH LIBRARY
Summary and Take Home Notes
✓ \checkmark ✓ GAT and GCN are the most popular GNNs
✓ \checkmark ✓ Although GCN is mathematically driven, we tend to ignore its math
✓ \checkmark ✓ GNN (or GCN) suffers from information lose while getting deeper
✓ \checkmark ✓ Many deep learning models can be slightly modified and designed to fit graph data, such as Deep Graph InfoMax, Graph Transformer, GraphBert.
✓ \checkmark ✓ Theoretical analysis must be dealt with in the future
✓ \checkmark ✓ GNN can be applied to a variety of tasks
Reference
博文所有内容摘抄自 Hung-yi Lee 机器学习, 国内可访问 Bilibili 搬运视频,课件可见 GNN.