MySQL索引原理与性能调优
MySQL 应该是最流行的后端数据库,尽管 NOSQL 近几年越来越火爆,可是相信大部分架构师还是会选择 MySQL 来做数据存储。
作为一名Java程序员相信MySQL我们都不陌生,但真的了解MySQL底层实现与性能优化吗?
一直想写几篇关于MySQL,JVM,多线程等底层实现与调优的博客,最近时间比较充足,那就让我们开启第一站之 “MySQL”。
首先来了解一下MySQL都有哪些引擎
MySQL引擎主要有InnoDB,MyISAM,CSV,Archive,Memory等,本文只讲常用的两种InnoDB和MyISAM。
InnoDB
InnoDB是MySQL5.5.8后默认的事务型引擎,也是最重要、最广泛的存储引擎,使用这个存储引擎,每个MyISAM在磁盘上存储成两个文件:
(1)frm文件:存储表的定义数据
(2)ibd文件:索引与数据文件(它的index和数据放在了一起,下文会详细分析基于b+tree实现的底层原理)
它的主要特点有:
(1)可以通过自动增长列,方法是auto_increment
(2)支持事务。默认的事务隔离级别为可重复读,通过MVCC(并发版本控制)来实现的(重点)
(3)使用的锁粒度为行级锁,可以支持更高的并发(重点)
(4)支持外键约束;外键约束其实降低了表的查询速度,但是增加了表之间的耦合度
(5)在InnoDB中存在着缓冲管理,通过缓冲池,将索引和数据全部缓存起来,加快查询的速度
(6)对于InnoDB类型的表,其数据的物理组织形式是聚簇表。所有的数据按照主键来组织。数据和索引放在一块,都位于B+树的叶子节点上
MyISAM
使用这个存储引擎,每个MyISAM在磁盘上存储成三个文件。
(1)frm文件:存储表的定义数据
(2)MYD文件:存放表具体记录的数据
(3)MYI文件:存储索引
有一个重要的特点就是不支持事务,但是这也意味着他的存储速度更快,如果你的读写操作允许有错误数据的话,只是追求速度,可以选择这个存储引擎;MyISAM使用表级锁,混合读写性能不佳,并发性差。
索引定义
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
索引分类
常见的索引数据结构有:hash索引、二叉树、平衡二叉树/红黑树、 b树、b+树
【hash索引】
哈希索引基于hash表实现,类似于Java中的HashMap,通过计算key的hash值定位index下标,在不发生hash冲突的情况下时间复杂度为常数级别,MySQL的hash索引会对所有的索引列计算一个hash码,由于hash的索引的特点,它的缺点也显而易见,只有精确匹配索引所有列的查询才有效,hash索引数据也并不是按照索引值顺序存储的,所以也无无法用于排序,只支持等值查询,不支持范围查询,总结如下:
优点:等值查询的时候效率非常高
缺点:Hash算法 数据存放散列 不支持范围查询
【二叉树】
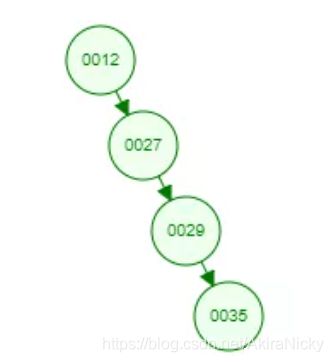
二叉树是每个结点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”,左子树比根节点值要小,右子树比根节点值要大

但二叉树有个致命的缺点,如果ID是自增的,则会出现斜树,形成酷似单向链表的结构:
【平衡二叉树 avl/红黑树】
平衡二叉树是一种特殊的二叉树,所以它也满足二叉树的基本特征,同时它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树,所以不会出现上面斜树的情况(旋转/变色);
这棵树始终满足平衡二叉树的几个特性而保持平衡!这样我们的树也不会退化为线性链表了!我们需要查找一个数的时候就能沿着树根一直往下找,这样的查找效率和二分法查找是一样的;
一颗平衡二叉树能容纳多少的结点呢?这跟树的高度是有关系的,假设树的高度为h,那每一层最多容纳的结点数量为2^(n-1),这样计算100w数据树的高度大概在20左右,那也就是说从有着100w条数据的平衡二叉树中找一个数据,最坏的情况下需要20次查找。如果是内存操作,效率也是很高的!但是我们数据库中的数据基本都是放在磁盘中的,每读取一个二叉树的结点就是一次磁盘IO,这样我们找一条数据如果要经过20次磁盘的IO?那性能就成了一个很大的问题了!那我们是不是可以把这棵树压缩一下,让每一层能够容纳更多的节点呢?虽然我矮,但是我胖啊~
【B - Tree】
这颗矮胖的树就是B-Tree,注意中间是杠精的杠而不是减,所以也不要读成B减Tree了,顾名思义就是B树~
为了描述B -Tree,首先定义一条数据记录为一个二元组 [key, data],key为记录的键值,对于不同数据记录,key是互不相同的;data为数据记录除key外的数据。那么B-Tree是满足下列条件的数据结构:
d为大于1的一个正整数,称为B-Tree的度
h为一个正整数,称为B-Tree的高度
每个非叶子节点由n-1个key和n个指针组成,其中d<=n<=2d
每个叶子节点最少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶节点的指针均为null
所有叶节点具有相同的深度,等于树高h
key和指针互相间隔,节点两端是指针
一个节点中的key从左到右非递减排列
所有节点组成树结构
每个指针要么为null,要么指向另外一个节点

上图是一个d,h为2的B - Tree示意图,由于B-Tree的特性,在B-Tree中按key检索数据的算法非常直观:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到null指针,前者查找成功,后者查找失败。
缺点:由于插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质;
叶子节点存放索引和data数据(index与data放在一起),每页缓存数据不会太多(Mysql服务器读取硬盘数据是以页为单位16kb读取硬盘中数据到缓存冲区内存中);
本文不打算完整讨论B-Tree这些内容,感兴趣的朋友可以去找资料学习一下。
【B +Tree】
MySQL默认索引结构,B+Tree是在B-Tree基础上的一种优化,它与B树最大的不同就是:B+Tree 分成叶子节点和非叶子节点,叶子节点存放索引和data数据,不存放指针;非叶子节点不存放data数据,只存放索引。
备注:15,18...是叶子节点,叶子节点没有子节点。
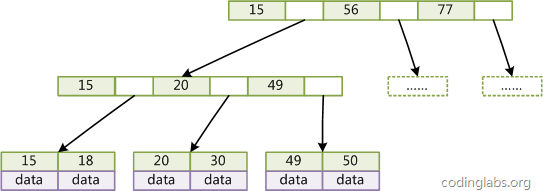
优点:索引和data数据分开,按照页读取范围更大
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针,如下图:
备注:一般都会采用自增主键或者雪花算法(也是自增的)来当主键

在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如上图中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
站在B+Tree角度分析InnoDB与MyISAM的区别
【MyISAM索引实现】
1. 主键索引
MyISAM引擎使用B+Tree作为索引结构,叶子节点的data域存放的是数据记录的地址
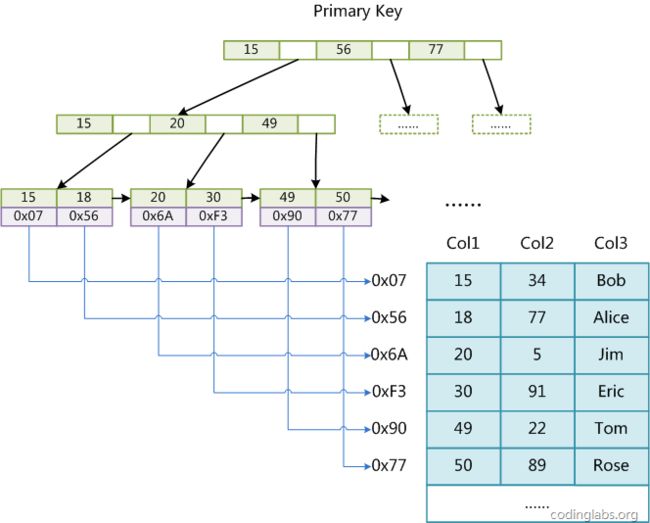
这里假设表一共有三列,假设我们以Col1为主键,上图是一个MyISAM表的主索引(Primarykey)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。
2. 辅助索引(Secondarykey)
在MyISAM中,主索引和辅助索引(Secondarykey)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复;如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
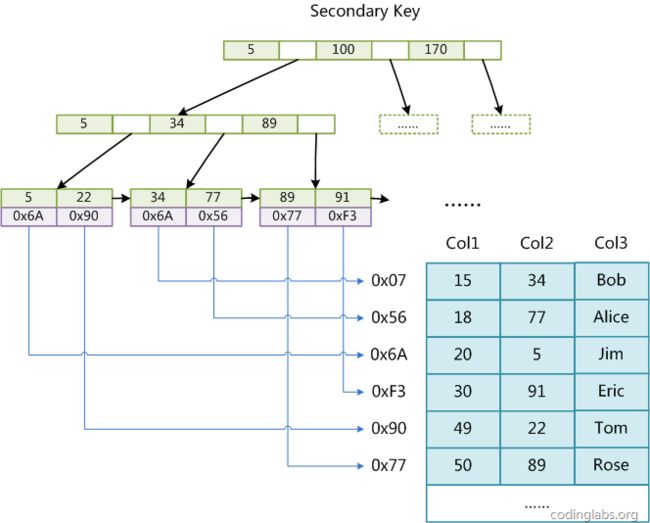
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录;
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
【InnoDB索引实现】
InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同
1. 主键索引
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点 data 域 保存了完整的数据记录; 这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引,InnoDB主键索引的示意图如下:
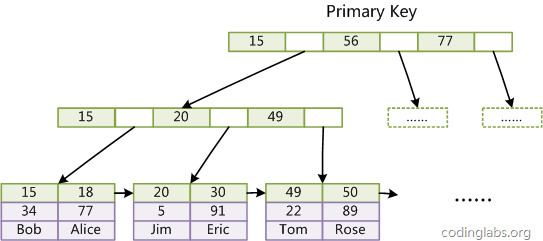
上图所示,InnoDB主键索引的叶节点包含了完整的数据记录(数据文件),这种索引叫做 聚集索引。
因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),
如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,
如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
2. 辅助索引(Secondarykey)
InnoDB的所有辅助索引都引用主键作为data域。 例如,下图为定义在Col3上的一个辅助索引:
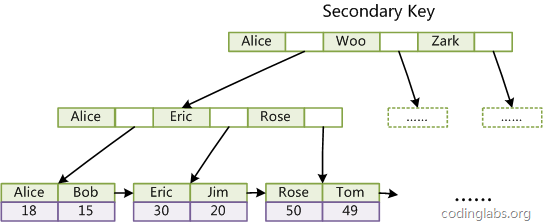
InnoDB表是基于聚簇索引建立的,因此InnoDB的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引(SecondaryIndex,也就是非主键索引)也会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义、很多索引,则争取尽量把主键定义得小一些,InnoDB不会压缩索引。
文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索 两遍索引 :首先 检索辅助索引获得主键,然后 用主键到主索引中检索获得记录。
总结 - InnoDB索引和MyISAM索引的区别:
一是主索引的区别,InnoDB的数据文件本身就是索引文件,即索引和数据没有分开;而MyISAM的索引和数据是分开的
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别
另外,InnoDb 叶子节点data数据存放对应行数据;MyISAM叶子节点data数据通过指针指向MYD数据文件对应行
MySQL索引实战与调优
1. 【定位慢查询】
MySQL的慢查询,全名是慢查询日志,是MySQL提供的一种日志记录,用来记录在MySQL中响应时间超过阈值的语句
具体环境中,运行时间超过long_query_time值的SQL语句,则会被记录到慢查询日志中。
long_query_time的默认值为10,意思是记录运行10秒以上的语句。
默认情况下,MySQL数据库并不启动慢查询日志,需要手动来设置这个参数。
当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。
慢查询日志支持将日志记录写入文件和数据库表。
官方文档,关于慢查询的操作命令如下(部分资料,具体参考官方相关链接):
show variables like '%query%' 查询慢日志相关信息
slow_query_log 默认是off关闭的,使用时,需要改为on 打开
slow_query_log_file 记录的是慢日志的记录文件
long_query_time 默认是10S,每次执行的sql达到这个时长,就会被记录
show status like '%slow_queries%' 查看慢查询状态
set global long_query_time = 1 修改慢查询时间1s
set global slow_query_log = 1 开启慢查询,1开启,0关闭
show variables like '%slow_query_log%'; 查看慢查询是否开启,默认off状态
注意:修改慢查询时间后,记得需要重新连接数据库客户端(Navicat)才可以生效
① slow_query_log
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的,可以通过设置slow_query_log的值来开启,如下所示:
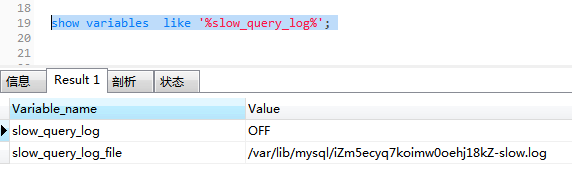
set global slow_query_log = 1set global slow_query_log=1开启了慢查询日志只对当前数据库生效,MySQL重启后则会失效。
如果要永久生效,就必须修改配置文件my.cnf(其它系统变量也是如此)。
my.cnf要增加或修改参数slow_query_log 和slow_query_log_file,如下所示
slow_query_log = 1
slow_query_log_file = /tmp/mysql_slow.log② long_query_time
开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢?
这个是由参数long_query_time控制,默认情况下long_query_time的值为10秒,可以使用命令修改,也可以在my.cnf参数里面修改
从MySQL 5.1开始,long_query_time开始以微秒记录SQL语句运行时间,之前仅用秒为单位记录
关于运行时间正好等于long_query_time的情况,并不会被记录下来
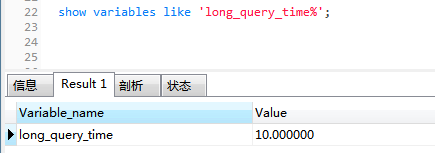
set global long_query_time = 2使用命令 set global long_query_time=2修改后,需要重新连接或新开一个会话才能看到修改值。
用show variables like 'long_query_time'查看是当前会话的变量值,也可以不用重新连接会话,而是用show global variables like 'long_query_time'
③ set globle log_output = file
这里设置为了file,就是说慢查询日志是通过file体现的,默认是none,我们可以设置为table或者file,如果是table则慢查询信息会保存到mysql库下的slow_log表中
④ 使用慢查询查询日志
cat ①中的slow.log即可查询请求时间于2s的SQL语句,并可以看到执行的时间是多少了...

2.【执行计划EXPLAIN】
MySQL 提供了一个 EXPLAIN 命令, 它可以对SELECT语句进行分析, 并输出SELECT执行的详细信息, 以供开发人员针对性优化.
EXPLAIN 命令用法十分简单, 在 SELECT语句前加上 EXPLAIN 就可以了, 例如:
EXPLAIN SELECT * from user_table WHERE id< 300![]()
EXPLAIN 输出各列的含义如下:
-
id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
-
select_type: SELECT 查询的类型.
-
table: 查询的是哪个表
-
partitions: 匹配的分区
-
type: join 类型
-
possible_keys: 此次查询中可能选用的索引
-
key: 此次查询中确切使用到的索引.
-
ref: 哪个字段或常数与 key 一起被使用
-
rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
-
filtered: 表示此查询条件所过滤的数据的百分比
-
extra: 额外的信息
接下来分析一些比较重要的列:
① select_type
1> SIMPLE(简单SELECT,不使用UNION或子查询等)
2> PRIMARY(子查询中最外层select,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
3> UNION(UNION中的第二个或后面的SELECT语句)
4> DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
5> UNION RESULT(UNION的结果,union语句中第二个select开始后面所有select)
6> SUBQUERY(子查询中的第一个SELECT,结果不依赖于外部查询)
7> DEPENDENT SUBQUERY(子查询中的第一个SELECT,依赖于外部查询)
8> DERIVED(派生表的SELECT, FROM子句的子查询)
9> UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
SIMPLE上面案例讲过了,那么一条SQL如果使用了 UNION 查询, 那么 EXPLAIN 输出 的结果类似如下(其它的自己测试一下即可):
explain select * from user_table where id < 2 union select * from user_table where id >=2
![]()
② type
表示MySQL在表中找到所需行的方式,或者叫访问类型。常见访问类型如下,从上到下,性能由差到最好:(一般来说,得保证查询达到range级别,最好达到ref)
| ALL | 全表扫描(一般是没有where条件或者where条件没有使用索引的查询语句) eg: explain select * from user_table where sex = 0 |
|---|---|
| index | 索引全扫描(index与ALL区别为index类型只遍历索引树,MySQL遍历整个索引来查询匹配行,并不会扫描表,一般是查询的字段都有索引的查询语句) eg: explain select id from user_table |
| range | 索引的范围扫描(常用于<、<=、>、>=、between等操作,注意这种情况下比较的字段是需要加索引的,如果没有索引,则MySQL会进行全表扫描) eg: explain select * from user_table where id > 10 and id < 20 |
| ref | 非唯一索引扫描(不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较"=",可能会找到多个符合条件的行) eg: explain select * from user_table where name = '张三' (name字段存在普通索引,非唯一索引) |
| eq_ref | 唯一索引扫描(primary key 或 unique key 索引的所有部分被连接使用,最多只会返回一条符合条件的记录,eq_ref一般出现在多表连接时使用primary key或者unique index作为关联条件) eg: explain select * from user_table inner join user_info on user_table.id = user_info.user_id |
| const,system | 单表最多有一个匹配行(const/system出现在根据主键primary key或者 唯一索引 unique index 进行的查询) eg: explain select * from user_table where id = 6 |
| NULL | 不用扫描表或索引(MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成) |
③ possible_keys: 表示查询可能使用的索引
key: 实际使用的索引
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。 如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
explain select * from user_table where name = '张三' ![]()
④ key_len: 使用索引字段的长度,计算规则如下:
- 字符串
- char(n):n字节长度
- varchar(n):2字节存储字符串长度,如果是utf-8,则长度 3n + 2
- 数值类型 — tinyint:1字节; smallint:2字节; int:4字节 ; bigint:8字节
- 时间类型 — date:3字节; timestamp:4字节; datetime:8字节
- 如果字段允许为 NULL,需要1字节记录是否为 NULL
如上图所示,索引inx_name指向的字段name长度为20,则key_len为3n+2=62,由于该字段允许为null,则+1结果为63
⑤ Extra
1> Using Where
explain select * from user_table where sex = 0 # sex未加索引![]()
需要注意的是:
· 返回所有记录的SQL,不使用where条件过滤数据,大概率不符合预期,对于这类SQL往往需要进行优化;
· 使用了where条件的SQL,并不代表不需要优化,往往需要配合explain结果中的type(连接类型)来综合判断;
本例虽然Extra字段说明使用了where条件过滤,但type属性是ALL,表示需要扫描全部数据,仍有优化空间;常见的优化方法为,在where过滤属性上添加索引,本例sex加上索引后的查询结果为:
![]()
2> Using index 无需回表查询
Extra为Using index说明,SQL所需要返回的所有列数据均在一棵索引树上,而无需访问实际的行记录;这类SQL语句往往性能较好。
explain select id,name from user_table where name = '张三'![]()
3> Using index condition 查找使用了索引,但是需要回表查询数据,这类SQL语句性能也较高,但不如Using index。
4> Using filesort
Extra为Using filesort说明,得到所需结果集,需要对所有记录进行文件排序。
这类SQL语句性能极差,需要进行优化;典型的,在一个没有建立索引的列上进行了order by,就会触发filesort,常见的优化方案是,在order by的列上添加索引,避免每次查询都全量排序。
explain select id,name from user_table order by update_time # update_time没加索引![]()
3.【MySQL索引优化实战篇】
① 方向解读
1> MySQL 索引底层采用B+树,降低树的高度,减少磁盘 io 的次数、高效的范围查询
2> 优化原则:核心:先定位慢查询,再通过慢查询日志文件分析 sq l语句
3> 分析 sql语句工具: EXPLAIN / trace 工具
4> EXPLAIN 执行计划要求 type 最低满足range范围查询级别
5> 常见方式:分页、排序、连表、count
② 索引优化规则
1> 如果MySQL估计使用索引比全表扫描还慢,则不会使用索引。
返回数据的比例是重要的指标,比例越低越容易命中索引。记住这个范围值——30%,后面所讲的内容都是建立在返回数据的比例在30%以内的基础上
2> 模糊查询like必须遵循最佳左前缀法则防止索引失效
如果用like时前缀用了%,查询一定是全表扫描(%如果非要放到前面,则select查询列一定都加了索引,索引才会生效)
select name from user_table where name like '%zh' # name加了索引前缀不用%时,查询速度也取决于字符串的筛选力度,如果表中包含的前缀数据很多,MySQL底层不会走索引,因为这种SQL中前缀选择性太低,导致MySQL底层认为还不如全表扫描查询的速度快
3> 字符串不加单引号索引会失效
explain select * from user_table where name = 007 (type为all)
explain select * from user_table where name = '张三' (type为ref)4> 复合索引的情况下,查询条件不包含索引列最左边部分(不满足最左原则),不会命中符合索引
5> 负向条件查询不能使用索引,可以优化为in查询;负向条件有:!=、<>、not in、not exists、not like等
6> 范围条件查询可以命中索引。范围条件有:<、<=、>、>=、between等
7> 对索引列进行计算或者使用函数,不会命中索引(想让索引不失效,等号左侧不要出现任何计算/函数)
explain select * from user_table where age + 1 = 24
explain select * from user_table where TO_DAYS(c.update_date) = TO_DAYS(now())8> is null 会使用索引(大部分都是认为会使索引失效,只能说大部分情况下,不会使用索引,也有用is null 会走索引的,详情参考博客:SQL SERVER 中is null 和 is not null 将会导致索引失效吗? - 潇湘隐者 - 博客园)
is not null不会使用索引(where只要出现not关键字,索引就会失效)
9> 业务相关
a. 更新十分频繁的字段上不宜建立索引:因为更新操作会变更B+树,重建索引。这个过程是十分消耗数据库性能的。
b. 区分度不大的字段上不宜建立索引:类似于性别这种区分度不大的字段,建立索引的意义不大。因为不能有效过滤数据,性能和全表扫描相当。另外返回数据的比例在30%以外的情况下,优化器不会选择使用索引。
c. 业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。虽然唯一索引会影响insert速度,但是对于查询的速度提升是非常明显的。另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,在并发的情况下,依然有脏数据产生。
d. 多表关联时,要保证关联字段上一定有索引。
e. 创建索引时避免以下错误观念:
索引越多越好,认为一个查询就需要建一个索引;宁缺勿滥,认为索引会消耗空间、严重拖慢更新和新增速度;抵制唯一索引,认为业务的唯一性一律需要在应用层通过“先查后插”方式解决;过早优化,在不了解系统的情况下就开始优化
10> 排序优化(最佳左前缀法则避免filesort)
在order by 是单字段的情况下,索引支持升序/降序排列
11> 分页优化
12> count优化