一种基于机器学习的电影推荐系统设计
资源下载地址:https://download.csdn.net/download/sheziqiong/85995378
资源下载地址:https://download.csdn.net/download/sheziqiong/85995378
摘 要
在互联网时代下,信息量呈指数级增长。海量数据以0、1 方式编码存放在磁盘等设备中非常方便,但是对于人类来说,我们的脑容量有限,在海量数据中挑选出适合自己的信息变得非常困难。简直如大海捞针,即使使用了分类方法和搜索引擎,我们还是要花大量时间去挑选适合自己的信息,并且经常选取了错误的信息。在这样的情况下, 个性化推荐系统应运而生。从起初的基于内容的推荐,到现在最常用的协同过滤推荐等推荐算法,我们从繁琐庞大的信息中解脱出来,可以接受大量系统推荐给我们的信息。
在大多数电子商务网站上,都运行着个性化推荐系统,不仅提高了用户购买率,还提高了用户体验。其系统内部实现由于基础数据不同也各有不同,而协同过滤算法被广泛应用到这些系统中,发挥着巨大的作用。
本文首先详细介绍了协同过滤算法与推荐系统概要,分析了各种协同过滤算法的优缺点。然后设计了一个简易的电影资源推荐系统,并使用 python、微信公众号等技术实现了这个推荐系统,最后对这个推荐系统做了简单的测试和结果分析。
关键词:个性化推荐系统;协同过滤;机器学习;数据挖掘;数据分析;python
Abstract
In the Internet age, the amount of information is exponential. Huge amounts of data to 0, 1, encoded in devices such as disk is very convenient, but for humans, our brain capacity is limited, selected for their own information in the huge amounts of data becomes very difficult.It’s like looking for a needle in a haystack, and even using a taxonomy and search engine, we still have to spend a lot of time sorting out what’s right for us and often picking the wrong information. In this case, the personalized recommendation system comes into being.Based on the recommendations from the content, from the beginning to now, the most commonly used collaborative filtering recommendation recommendation algorithm, such as free from complex huge information, we can accept a large number of system is recommended for our information.
On most e-commerce sites, the personalized recommendation system is running, which not only improves the user purchase rate, but also improves the user experience.The internal implementation of the system is different due to the different basic data, and the collaborative filtering algorithm is widely applied to these systems and plays a huge role.
In this paper, we first introduce the collaborative filtering algorithm and recommendation system profile, and analyze the advantages and disadvantages of various collaborative filtering algorithms.Then design a simple movie recommendation system resources, and using the python, micro letter of public technology implements this recommendation system, finally, the recommendation system has made the simple test and the result analysis.
Key words:Personalized recommendation system;Collaborative filtering;Machine learning;Data mining;Data analysis;Python
目 录
摘 要 I
Abstract II
第一章 绪论 1
1.1 课题背景及意义 1
1.2 国内外研究现状 2
1.3 论文内容结构 2
第二章 协同过滤与相关技术 3
2.1 推荐算法介绍 3
2.1.1 基于内容的推荐算法 3
2.1.2 协同过滤算法 4
2.1.3 协同过滤算法分类 4
2.1.4 协同过滤优化 5
2.1.5 协同过滤推荐的优缺点 5
2.1.6 应用场景 7
2.2 相关技术介绍 7
第三章 系统分析与设计 9
3.1 需求分析 9
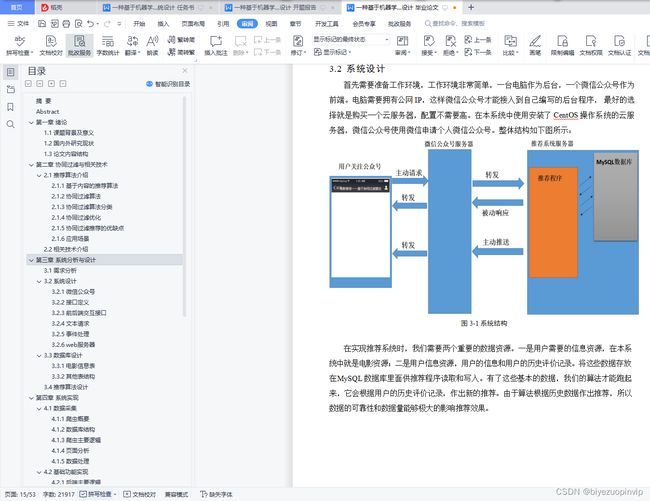
3.2 系统设计 10
3.2.1 微信公众号 11
3.2.2 接口定义 12
3.2.3 前后端交互接口 13
3.2.4 文本请求 14
3.2.5 事件处理 14
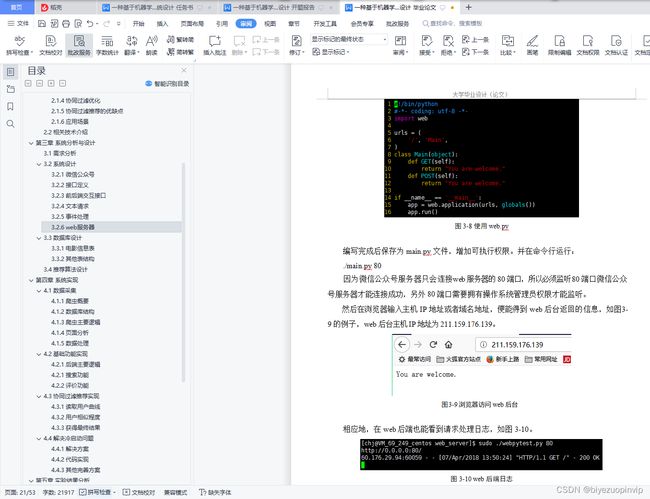
3.2.6 web服务器 15
3.3 数据库设计 17
3.3.1 电影信息表 17
3.3.2 其他表结构 17
3.4 推荐算法设计 18
第四章 系统实现 20
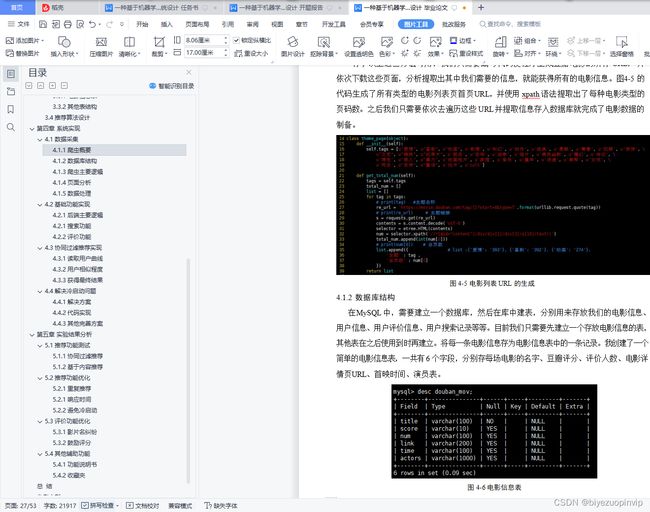
4.1 数据采集 20
4.1.1 爬虫概要 20
4.1.2 数据库结构 22
4.1.3 爬虫主要逻辑 23
4.1.4 页面分析 24
4.1.5 数据处理 25
4.2 基础功能实现 26
4.2.1 后端主要逻辑 26
4.2.1 搜索功能 30
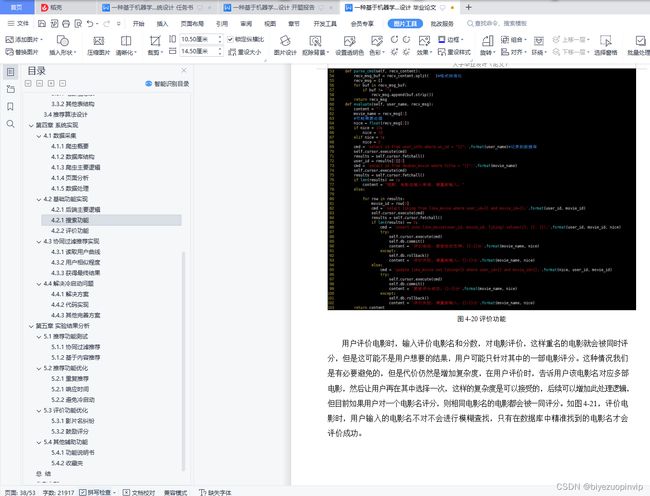
4.2.2 评价功能 32
4.3 协同过滤推荐实现 35
4.3.1 读取用户曲线 35
4.3.2 用户相似程度 36
4.3.3 获得最终结果 37
4.4 解决冷启动问题 38
4.4.1 解决方案 38
4.4.2 代码实现 39
4.4.3 其他完善方案 39
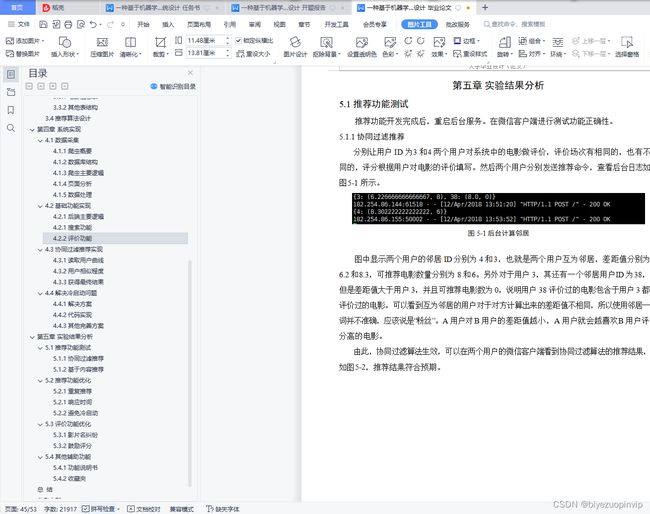
第五章 实验结果分析 40
5.1 推荐功能测试 40
5.1.1 协同过滤推荐 40
5.1.2 基于内容推荐 41
5.2 推荐功能优化 43
5.2.1 重复推荐 43
5.2.1 响应时间 43
5.2.2 避免冷启动 43
5.3 评价功能优化 43
5.3.1 影片名纠纷 44
5.3.2 鼓励评分 44
5.4 其他辅助功能 44
5.4.1 功能说明书 44
5.4.2 收藏夹 45
总 结 46
参考文献 47
致 谢 48
3.1 需求分析
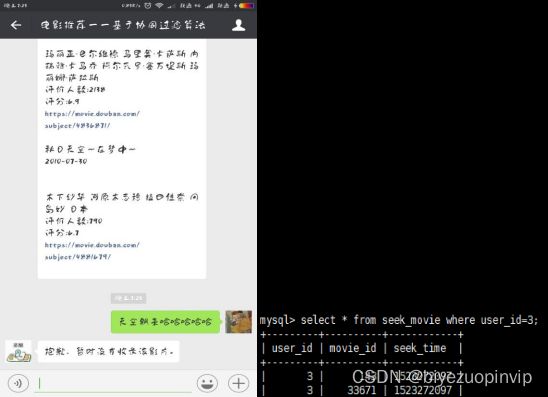
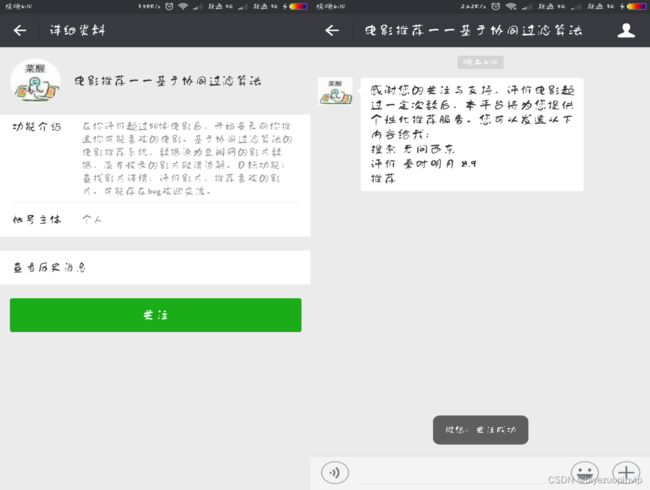
本文将利用上一章中介绍的技术搭建一个电影资源个性化推荐系统。本系统对用户提供一个微信公众号,微信用户对公众号添加关注后就能享受到电影个性化推荐服务。
在用户使用推荐系统时,会用到几个功能:
个性化推荐功能:这是用户所需要的服务,也是推荐系统的必要功能。
评价功能:用户可以对看过的电影进行一个评价,这份数据将作为推荐算法做抉择的依据。
搜索功能:一个基本的功能,能让用户准确搜索出电影的详细信息。除了上述的必要功能,用户可能还会用到一些其他的扩展功能:
说明书:怎么与公众号进行交互,让系统进行相关的操作,把这个写成说明书给用户看。
收藏夹:用户对于喜欢的电影可以添加到收藏夹,以免忘记。
在使用该系统时,用户可以主动向公众号发出一些命令,然后公众号完成相应的功能,可能还需要返回结果内容。
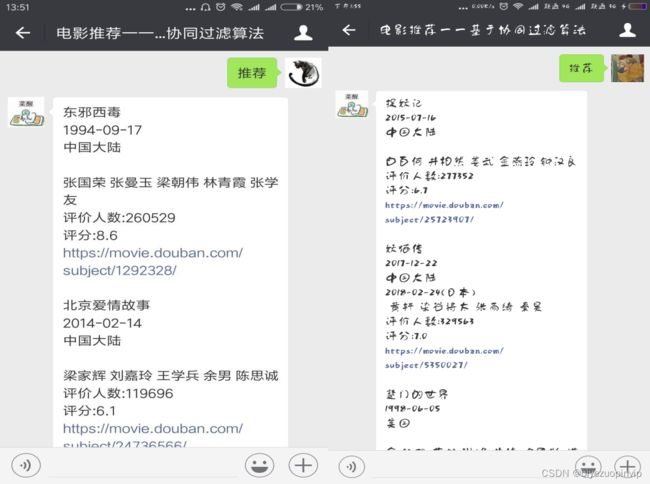
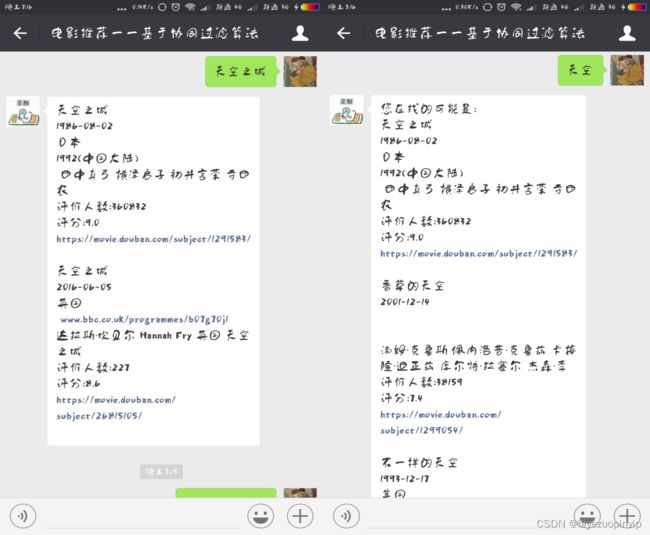
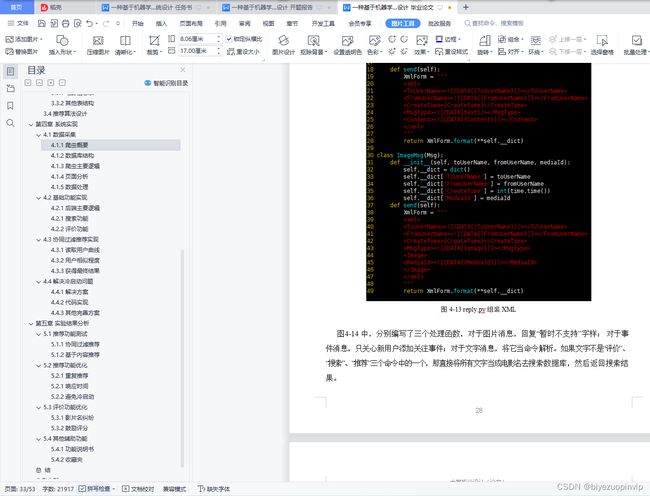
推荐功能可以将内容主动推荐给用户,也可以在用户使用系统时显示出推荐结果, 也可以让用户主动寻求推荐。由于本系统使用微信公众号,功能有限,所以使用的方法是用户主动寻求推荐,当用户发送“推荐”二字给系统时,系统做出推荐结果返回给用户。
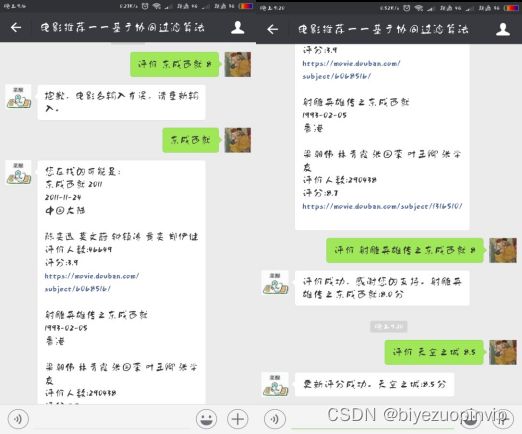
评价功能可以在用户购买商品后进行评价,或者在观看电影后对电影进行评价,但是由于本系统没有购物系统,只是简单的推荐系统,所以这个功能也是用户主动评价, 用户可以对电影进行一个 0-10 分的评价。系统将记录这个评分,用来作为个性推荐的依据。
搜索功能则比较简单,用户直接发送电影名,系统将电影详细信息返回给用户。其他功能对推荐系统的作用不是很大,本文没有做出具体实现。
3.4 推荐算法设计
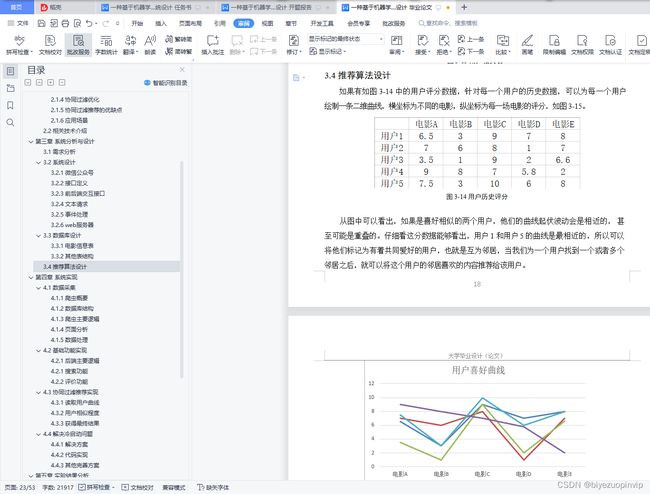
如果有如图 3-14 中的用户评分数据,针对每一个用户的历史数据,可以为每一个用户绘制一条二维曲线,横坐标为不同的电影,纵坐标为每一场电影的评分,如图 3-15。
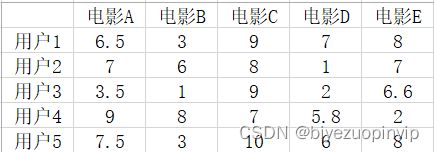
图 3-14 用户历史评分
从图中可以看出,如果是喜好相似的两个用户,他们的曲线起伏波动会是相近的, 甚至可能是重叠的。仔细看这分数据能够看出,用户 1 和用户 5 的曲线是最相近的,所以可以将他们标记为有着共同爱好的用户,也就是互为邻居,当我们为一个用户找到一个或者多个邻居之后,就可以将这个用户的邻居喜欢的内容推荐给该用户。

图 3-15 用户喜好曲线
本系统中的协同过滤算法使用这样的原理,不断为每一个用户找到喜好邻居,然后将邻居的喜好推荐给该用户。对于两条曲线,它们之间所围成的面积越小则越相近,也表示这两个用户有共同的兴趣爱好。
上述算法非常简单实用,但是数据库中的用户喜好数据往往是稀疏的,对于同一场电影不可能每个人都对它进行过评分。所以这个算法在满数据的情况下非常实用,但是在数据稀疏的情况下则不是那么有效。当然现实场景中也不需要数据全满,如果数据全满则意味着两个用户看过的电影是相同的,则无法推荐一些用户没有看过的电影给用户。
部分代码如下:
# coding=utf-8
# usr/bin/eny python
import urllib.request
import requests
from lxml import etree
import time
import random
import pymysql
'''
获取所有主题下的全部链接地址
获取每个主题下有多少页内容 (没有输入,输出字典)
'''
class theme_page(object):
def __init__(self):
self.tags = [u"爱情", u"喜剧", u"动画", u'剧情', u'科幻', u'动作', u'经典', u'悬疑', u'青春', u'犯罪', u'惊悚', \
u"文艺", u"搞笑", u"纪录片", u'励志', u'恐怖', u'战争', u'短片', u'黑色幽默', u'魔幻', u'传记', \
u'情色', u"感人", u"暴力", u'动画短片', u'家庭', u'音乐', u'童年', u'浪漫', u'黑帮', u'女性', \
u'同志', u"史诗", u"童话", u'烂片', u'cult']
def get_total_num(self):
tags = self.tags
total_num = []
list = []
for tag in tags:
# print(tag) #主题名称
re_url = 'https://movie.douban.com/tag/{}?start=0&type=T'.format(urllib.request.quote(tag))
# print(re_url) # 主题链接
s = requests.get(re_url)
contents = s.content.decode('utf-8')
selector = etree.HTML(contents)
num = selector.xpath('//*[@id="content"]/div/div[1]/div[3]/a[10]/text()')
total_num.append(int(num[0]))
# print(num[0]) # 总页数
list.append({ # list :{'爱情': '393'}, {'喜剧': '392'}, {'动画': '274'},
'主题' : tag ,
'总页数' : num[0]
})
return list
#使用lxml工具先抓到列表页中的电影简介信息和链接,然后进入到每部电影的链接里抓取详情信息。
tag = urllib.request.quote(u'爱情')
url_1 = 'https://movie.douban.com/tag/{}?start=0&type=T'.format(tag)
class douban(object):
def __init__(self,*args,**kwargs):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='186386', db='douban', charset='utf8')
self.cursor = self.conn.cursor()
self.sql_info = "INSERT IGNORE INTO `douban_mov` VALUES(%s,%s,%s,%s,%s,%s)"
def search(self,content):
'''
爬取页面内电影信息
'''
try:
selector = etree.HTML(content)
textslist = selector.xpath('//div[contains(@class,"grid-16-8 clearfix")]/div[1]/div[2]/table')
except Exception as e:
print(e)
try:
for text in textslist:
lists = []
title = text.xpath('tr/td[2]/div/a/text()')
score = text.xpath('tr/td[2]/div/div/span[2]/text()')
num = text.xpath('tr/td[2]/div/div/span[3]/text()')
link = text.xpath('tr/td/a/@href')
content = text.xpath('tr/td[2]/div/p/text()')
if title:
title = title[0].strip().replace('\n', "").replace(' ', "").replace('/', "") if title else ''
score = score[0] if score else ''
num = num[0].replace('(', "").replace(')', "") if num else ''
link = link[0] if link else ''
time = content[0].split(' / ')[0] if content else ''
actors = content[0].split(' / ')[1:6] if content else ''
lists.append({
'电影名' : title,
'评分' : score,
'评价人数' : num,
'详情链接' : link,
'上映时间' : time,
'主演' : actors
})
if lists:
lists = lists.pop()
else:
lists = u' '
print(lists)
try:
self.cursor.execute(self.sql_info,(str(lists['电影名']),str(lists['评分']),str(lists['评价人数']),str(lists['详情链接']), str(lists['上映时间']),str(lists['主演'])))
self.conn.commit()
except Exception as e:
print(e)
except Exception as e:
pass
#从列表页中找到每部电影链接,进去抓详情
def get_detail(self,url):
'''
抓取每页详细信息
'''
try:
detail_contents = requests.get(url)
detail_contents =detail_contents.content.decode('utf-8')
selector = etree.HTML(detail_contents)
except Exception as e:
print(e)
detail = []
try:
detail_director = selector.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') # 导演
detail_time = selector.xpath('//span[contains(@property,"v:runtime")]/text()') # 片长
detail_type_1 = selector.xpath('//*[@id="info"]/span[5]/text()') # 类型
detail_type_2 = selector.xpath('//*[@id="info"]/span[6]/text()')
detail_type_3 = selector.xpath('//*[@id="info"]/span[7]/text()')
except Exception as e:
print(e)
if detail_director:
detail_director = detail_director[0] if detail_director else ''
detail_time = detail_time[0] if detail_time else ''
detail_type_1 = detail_type_1[0] if detail_type_1 else ''
detail_type_2 = detail_type_2[0] if detail_type_2 else ''
detail_type_3 = detail_type_3[0] if detail_type_3 else ''
type = detail_type_1 + u' ' + detail_type_2 + u' ' + detail_type_3
detail.append({
'导演' : detail_director,
'片长' : detail_time,
'类型' : type,
})
else:
pass
return detail
#让程序run起来
random.seed(100)
page = theme_page()
page_list = page.get_total_num()
print(page_list)
run = douban()
for page_info in page_list: # 遍历所有主题
tags = page_info['主题']
page = page_info['总页数']
tag = urllib.request.quote(tags)
threads = []
for i in range(int(page)): # 每个主题下的所有页数
url = 'https://movie.douban.com/tag/{0}?start={1}&type=T'.format(tag, i * 20)
s = requests.get(url)
s = s.content.decode('utf-8')
lists = run.search(s)
sleep_time_mix = random.randint(30, 70)
time.sleep(sleep_time_mix)
sleep_time_max = random.randint(600, 3000)
time.sleep(sleep_time_max)


资源下载地址:https://download.csdn.net/download/sheziqiong/85995378
资源下载地址:https://download.csdn.net/download/sheziqiong/85995378