数据分析中的numpy ,pandas (1)
目录
一、numpy
1 np.arange数组
2 np.random
3 reshape函数
二 pandas
1 Series
2 DataFrame
修改索引
set_index
rename
reset_index
一、numpy
1.大前提:应用numpy并重命名为np
import numpy as np
2.列表可以存放任意类型
lis1 = ["as",1.34,34,None]
lis1 
3.ndarry是python中的一个类对象,而array是numpy中用来创建数组的一种方法。
import numpy as np #应用numpy并重命名
np.array([1,2,3,4,5,6,7,8,9])

4.ndarray会自动把元素类型统一
- ndarray与Python列表的最大的不同就是列表可以存入不同数据类型的元素,而ndarray要求所有元素的数据类型必须一致。Numpy会自动识别ndarray中的数据类型,如果数据类型不一致Numpy会将所有元素自动转换成一个合适的数据类型。
- 为了方便运算
- 可以看到 列表后面会有dtype=object
np.array (["as",1.34,34,None])
5.通过构造方法
#构造方法
ages = [17,28,8,16,38]
ages_array = np.array(ages)
# ages_array 执行所有ndarray类型的方法
ages[0],age[-1]

ages_array[0]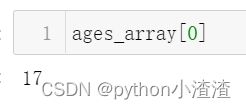
ages_array.sum()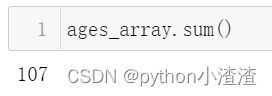
6. 切片; 左闭右开;
ages_array[0:2]array1 = np.array([1,2,3,4,5])
array2 = np.array([[1,2],[3,4]])
array1
array2array2[0,1]
1 np.arange数组
1.arange用法
np.arange(5)np.arange(5,10)np.arange(5,10,0.5)
2 np.random
1.random用法
#生成标准正态分布
data = np.random.randn(100)import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(data)呈现一个正态分布的图

2.生成一组随机数列
- np.random.randint(起始值,终止值,(行,列))
np.random.randint(1,100,(6,3)) 
3 reshape函数
1.用法: reshape(行,列)
#reshape函数
data = np.arange(2,10,1)
data.reshape((2,4))#数据个数要配的上
二 pandas
大前提 ,pandas知识点记得从这里往下看哦
import numpy as np
import pandas as pdnp.array(['dancer','love','cute']) 
1 Series
1.显示索引 ;
index行 :可以改每一行的名字
data1 = pd.Series(['dancer','love','cute'],index=['one','two','three'])
data1 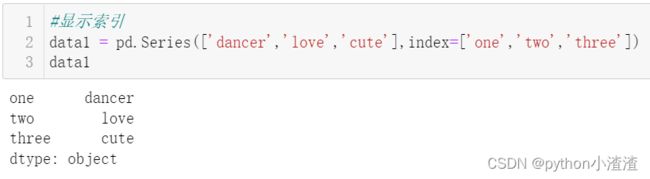
data2 = pd.Series([18,191,10],index=['one','two','three'])
data2 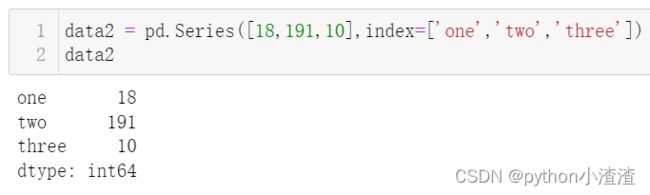
2 DataFrame
1.字典构造
将上面的data1和data2两个数据结合起来,用法如下
pd.DataFrame(data={
'data1':data1,
'data2':data2
})
column列 :可以改列名
pd.DataFrame([['fg',18],['fgh',191],['hjk',10]],index=['one','two','three'],columns = ['name','age'])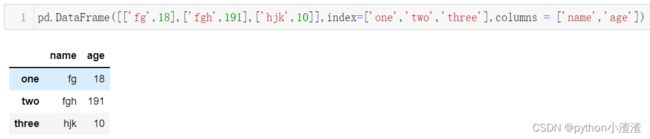
2.把DataFrame对象当成字典使用
mdata = [1,2,3,4,5,6,7]
score = [2,334,45,56,77,1,29]
#把DataFrame对象当成字典使用
a = pd.DataFrame()
a['count1'] = mdata
a['count2'] = score
a
3.通过字典创建DataFrame
b = pd.DataFrame({'a':[1,2,3,4],'b':[4,5,6,7]},index=["彩头","奖金","名次","位次"])
print(b)
默认为列索引
data = {'a':[4,5,6,7],'b':[0,9,8,7]}
pd.DataFrame(data=data)
4.让字典键变成行索引,可通过from_dict的方式,并同时设置orient参数为index
c = pd.DataFrame.from_dict({'a':[4,5,6,7],'b':[0,9,8,7]},
orient = "index"
)
print(c)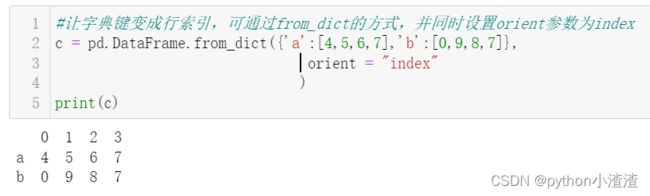
5.让我们整体来写一下
pd.DataFrame(data=np.arange(12).reshape(3,4),index=["hjk","hjo","hjp"],columns=['A','B','C','D'])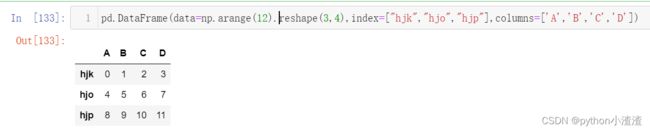
修改索引
c = ['万科','阿里','百度']
s = [2,4,6]
t = [1,3,5]
data = pd.DataFrame(data={
'公司':c,'分数':s,'日期':t
})
data
set_index
#把日期变成索引set_index
data.set_index('日期')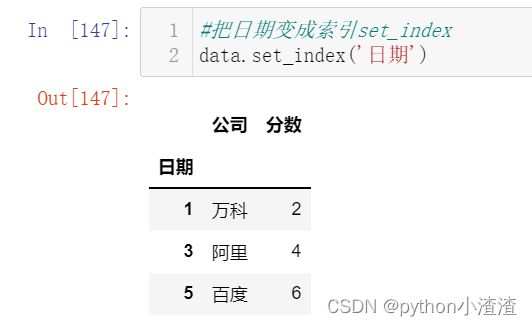
set_index不会修改原始数据,如果希望修改,设置inplace=True
- inplace作用是:是否在原对象基础上进行修改
- inplace = True:不创建新的对象,直接对原始对象进行修改;
- inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果。
- 默认是False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似。
rename
#要修改列名称,使用columns,要修改行名称,使用index
#使用字典来表达映射关系{原始数据:新数据}
data.rename(columns={'公司':'公司名称'},index={1:2})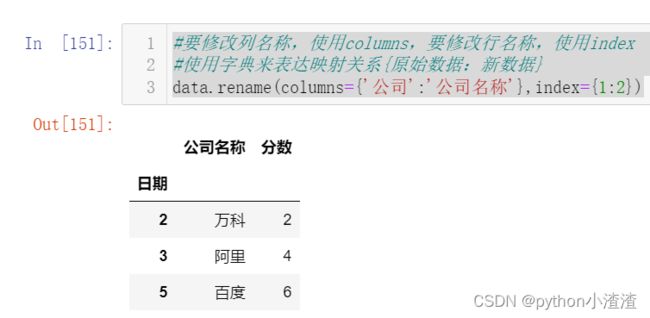
reset_index
#把索引重新设置为列
data.reset_index()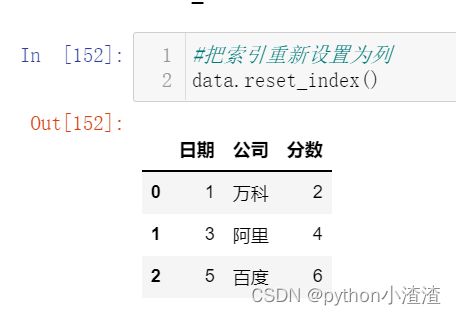
当我们添加了inplace=True则说明我们不创建新的对象,直接对原始对象data进行修改;如下图可知
data.reset_index(inplace=True)data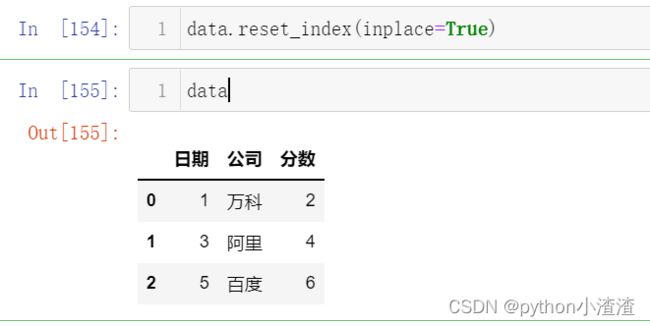
总结
可能文章有点点乱,但整体用法应该是没有写错的,记得从上往下看,因为我都是放在同一个文件里面打的,有些用法会直接采用上一条语句的结果,所以要关连起来看,避免出错了。友友们都看到这里了,觉得有用的话,能否给个小赞赞o(* ̄▽ ̄*)ブ比心。