大话系列 | SVM(下)—时间刺客带你做项目
↑关注+星标,听说他有点东西
全文共1811字,阅读全文需14分钟
写在前面的话
大家好,我是小一
本节实战是我们大话系列的第4个实战项目,也是本系列的第11篇原创文章
还记得前面写Python高阶系列的时候也一口气写了10篇原创,那10篇文章用了不到两个星期,丝毫不带犹豫的。
那会写文章都是在下班之后才开始,并且还抽空在牛客网刷完了所有的SQL题,在力扣上也刷了不少算法题,现在想来也不明白当时哪来的时间。
如果非要形容一下那段时间的话,那只能一个词来形容:时间刺客
有空再聊其他的,我们先来看今天的实战项目
实战之前你还需了解这些
我们知道针对样本有线性SVM和非线性SVM
同样的在sklearn 中提供的这两种的实现,分别是:LinearSVC和SVC
SVC?不应该是SVM吗?
SVC:Support Vector Classification 用作处理分类问题
那是不是意味着还可以处理回归问题?
是的,没错。但我们常用SVM来做分类问题,处理回归问题会用到LinearSVR和SVR(R代表Regression)
SVC和LinearSVC
LinearSVC是线性分类器,用于处理线性分类的数据,且只能使用线性核函数
SVC是非线性分类器,即可以使用线性核函数进行线性划分,也可以使用高维核函数进行非线性划分
SVM的使用
在sklearn 中,同样还是一句话调用SVM
from sklearn import svm如何创建SVM分类器呢?
主要说一下SVC的创建,因为它的参数比较重要
model = svm.SVC(kernel='rbf', C=1.0, gamma=0.001)分别解释一下三个重要参数:
kernel代表核函数的选择,有四种选择,默认rbf(即高斯核函数)
参数C代表目标函数的惩罚系数,默认情况下为 1.0
参数gamma代表核函数的系数,默认为样本特征数的倒数
其中kernel代表的四种核函数分别是:
linear:线性核函数,在数据线性可分的情况下使用的
poly:多项式核函数,可以将数据从低维空间映射到高维空间
rbf:高斯核函数,同样可以将样本映射到高维空间,但所需的参数较少,通常性能不错
sigmoid:sigmoid核函数,常用在神经网络的映射中
SVM的使用就介绍这么多,来实战测试一下
实战项目
1. 数据集
SVM的经典数据集:乳腺癌诊断
医疗人员采集了患者乳腺肿块经过细针穿刺 (FNA) 后的数字化图像,并且对这些数字图像进行了特征提取,这些特征可以描述图像中的细胞核呈现。通过这些特征可以将肿瘤分成良性和恶性
本次数据一共569条、32个字段,先来看一下具体数据字段吧
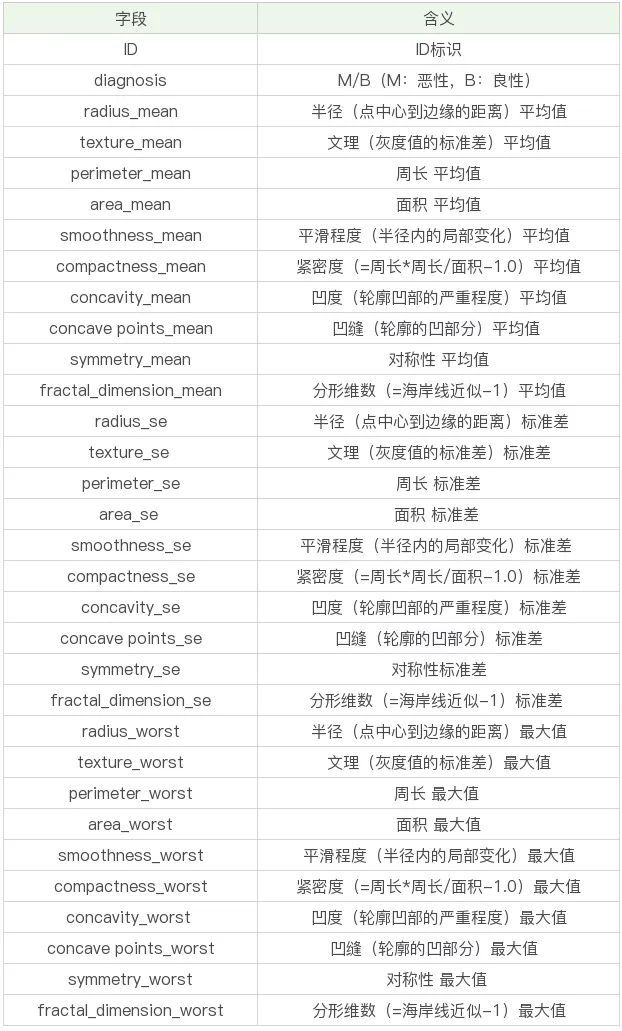 字段含义
字段含义
其中mean结尾的代表平均值、se结尾的代表标准差、worst结尾代表最坏值(这里具体指肿瘤的特征最大值)
所有其实主要有10个特征字段,一个id字段,一个预测类别字段
我们的目的是通过给出的特征字段来预测肿瘤是良性还是恶性
准备好了吗?3,2,1 开始
2. 数据EDA
EDA:Exploratory Data Analysis探索性数据分析
先来看数据分布情况
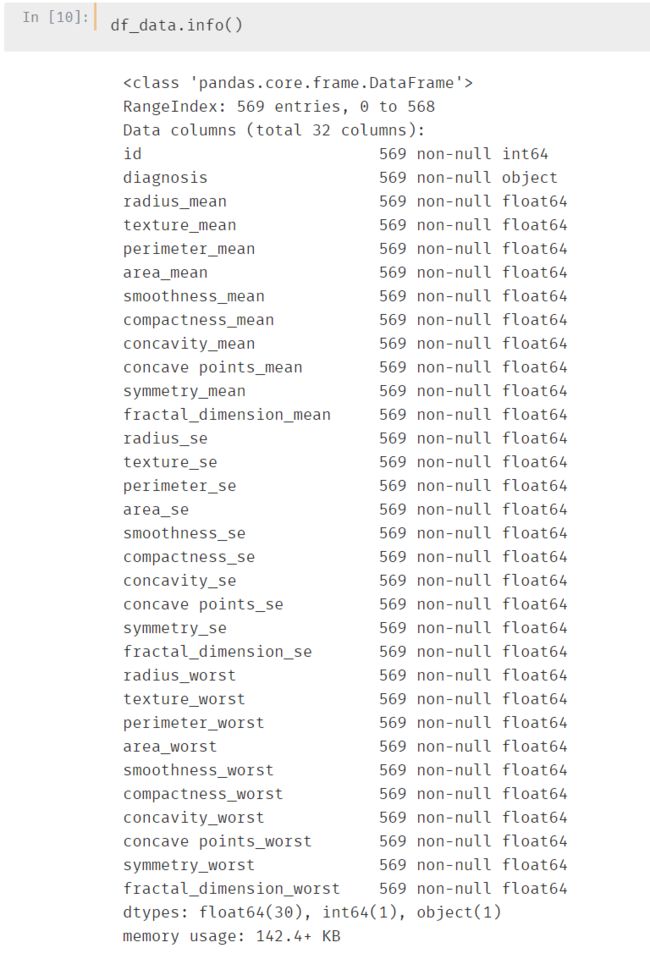 数据整体分布情况
数据整体分布情况
一共569条、32个字段。32个字段中1个object类型,一个int型id,剩下的都是float 类型。
另外:数据中不存在缺失值
大胆猜测一下,object类型可能是类别型数据,即最终的预测类型,需要进行处理,先记下
再来看连续型数据的统计数据:
 连续型数据
连续型数据
好像也没啥问题(其实因为这个数据本身比较规整)
那直接开始特征工程吧
3. 特征工程
首先就是将类别数据连续化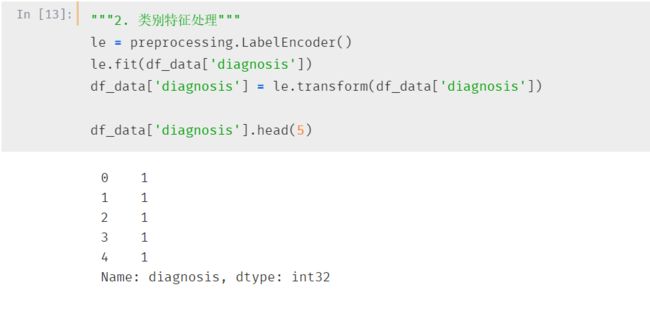
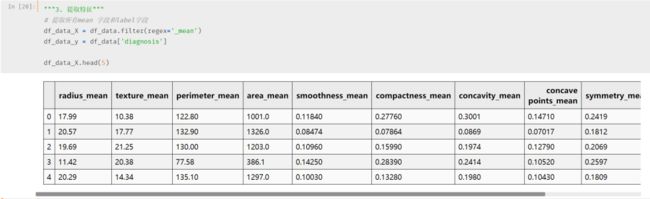
再来观察每一个特征的三个指标:均值、标准差和最大值。
优先选择均值,最能体现该指特征的整体情况
现在还有十个特征,我们通过热力图来看一下特征之间的关系
# 热力图查看特征之间的关系
sns.heatmap(df_data[df_data_X.columns].corr(), linewidths=0.1, vmax=1.0, square=True,
cmap=sns.color_palette('RdBu', n_colors=256),
linecolor='white', annot=True)
plt.title('the feature of corr')
plt.show()热力图是这样的:
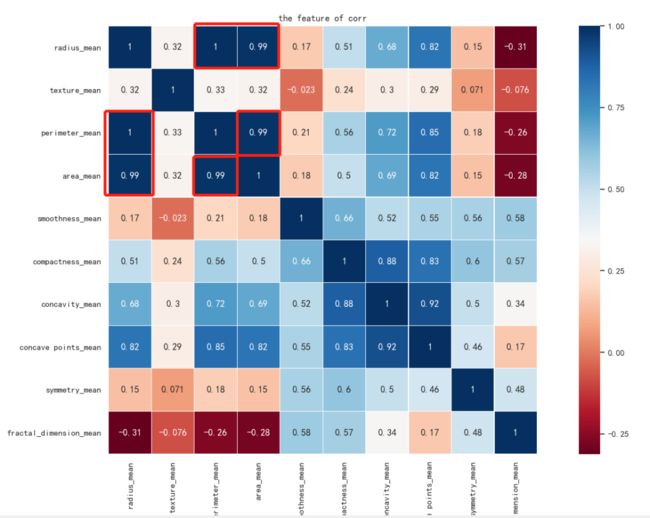 注意红框圈出的部分
注意红框圈出的部分
我们发现radius_mean、perimeter_mean和area_mean这三个特征强相关,那我们只保留一个就行了,这里保留热力图里面得分最高的perimeter_mean
最后一步,因为是连续数值,最好对其进行标准化
标准化之后的数据是这样的:
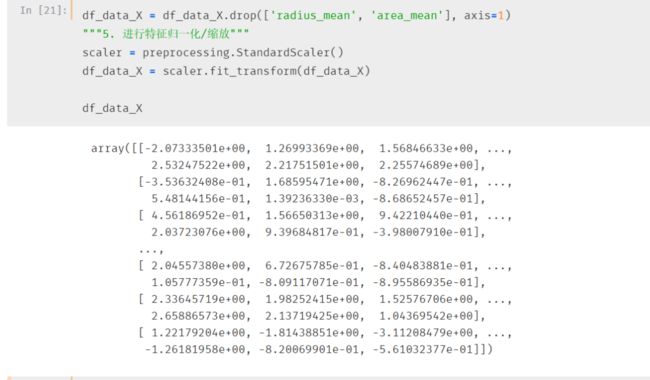 数据标准化
数据标准化
4. 训练模型
上面已经做好了特征工程,我们直接塞进模型看看效果怎么样
因为并不知道数据样本到底是否线性可分,所有我们都来试一下两种算法
先来看看LinearSVC 的效果
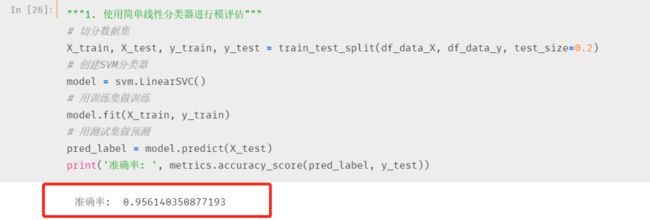 LinearSVC
LinearSVC
效果很好,简直好的不行
这个准确率就不要纠结了,后面真正做实际案例的时候再纠结准确率吧
ok,还有SVC的效果
因为SVC需要设置参数,直接通过网格搜索让机器自己找到最优参数
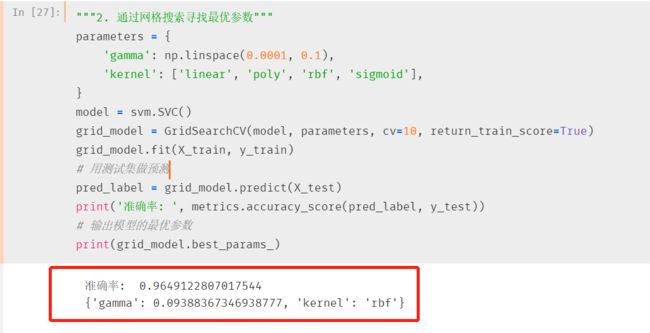 网格搜索确定最优参数并训练
网格搜索确定最优参数并训练
效果更好,小一我一时都惊呆了
可以看出,最终模型还是选择rbf高斯核函数,果然实至名归
写在后面的话
需要源代码的同学后台回复SVM
本节项目主要是介绍了SVM在skearn中的相关参数,实战项目中主要通过数据EDA+特征工程完成了数据方面的工作,然后通过交叉验证+网格搜索确定了最优模型和最优参数
算法学起来确实很吃力,不过一个算法+一个项目的学,应该会比单纯推算法有意思些,也会有成就感些。
我是小一,第一步的一,我们下节见!
即使是刺客,也会留下影子![]()