【C语言进阶篇】字符函数和字符串函数——strstr&&strtok&&strerror&&strncpy&&strncat&&strcmp函数
大家好我是沐曦希
字符函数和字符串函数
- 1.前言
- 2.长度受限制的字符串函数介绍
-
- 2.1 strncpy
-
- 2.1.1 模拟实现strncpy
- 2.2 strncat
-
- 2.2.1 模拟实现strncat
- 2.3 strncmp
-
- 2.3.1 模拟实现strncmp
- 3.字符串查找
-
- 3.1.strstr
-
- 模拟实现strstr
- 3.2.strtok
- 4.错误信息报告
- 4.1strerror
- 5.字符操作
-
- 5.1 字符分类函数
- 5.2 字符转换
- 6.写在最后
1.前言
前面学到了求字符串函数strlen和长度不受限制的字符串函数,那么现在学习学习另一些字符串函数。
2.长度受限制的字符串函数介绍
2.1 strncpy
char * strncpy ( char * destination, const char * source, size_t num );

1.Copies the first num characters of source to destination. If the end of the source C string (which is signaled by a null-character) is found before num characters have been copied, destination is padded with zeros until a total of num characters have been written to it.
2.拷贝num个字符从源字符串到目标空间。
3.如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。
#include
调试看一下,为复制之前:

复制后:
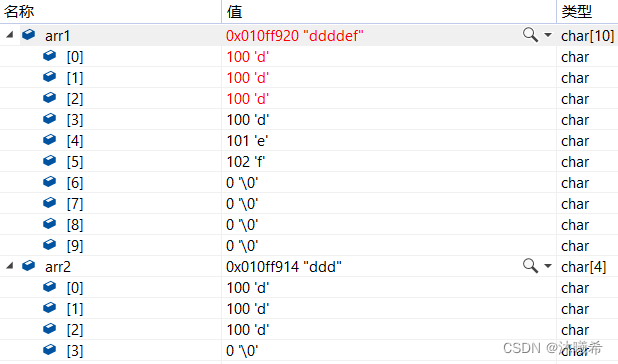
arr1的前三个字节改变成arr2的内容,arr2没有变化。
如果要复制的字节数大于源字符串呢?
源字符串字节小于复制的字节数:
#include复制之前:

复制之后:

可以清楚的看到,内容不够时会用’\0’来补充!
2.1.1 模拟实现strncpy
#include
2.2 strncat
char * strncat ( char * destination, const char * source, size_t num );

1.Appends the first num characters of source to destination, plus a terminating null-character.
2.If the length of the C string in source is less than num, only the content up to the terminating null-character is copied.
#include
追加之前:

追加之后:

可以清楚看到追加的字符串后面会加‘\0’作为结束标志,并且在目标字符串的’\0’位置开始追加的源字符串的。
那么如果追加的字节数大于源字符串的字节数呢?
#include
追加之前:

追加之后:

可以清楚看见并没有继续追加’\0’,只会添加一个’\0’。
2.2.1 模拟实现strncat
#include
2.3 strncmp
int strncmp ( const char * str1, const char * str2, size_t num );

1.比较到出现另个字符不一样或者一个字符串结束或者num个字符全部比较完。

#include 
strncmp与strcmp一样比较的是字符的ASCII码值。
2.3.1 模拟实现strncmp
#include);
return 0;
}

3.字符串查找
3.1.strstr
const char * strstr ( const char * str1, const char * str2 );
char * strstr ( char * str1, const char * str2 );

Returns a pointer to the first occurrence of str2 in str1, or a null pointer if str2 is not part of str1.
#include 
模拟实现strstr
查找字符串分两种情况:
第一种情况是:一次匹配完成。

第二种情况是:要多次匹配才能找到。

#include
3.2.strtok
char * strtok ( char * str, const char * delimiters );

1.sep参数是个字符串,定义了用作分隔符的字符集合
2.第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
3.strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
4.strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
5.strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
6.如果字符串中不存在更多的标记,则返回 NULL 指针。
#include
for循环实现
#include4.错误信息报告
4.1strerror
char * strerror ( int errnum )
C语言的库函数在执行失败的时候,都会设置错误码。
errno是C语言设置的一个全局的错误码存放的变量。
#include 
#include
5.字符操作
5.1 字符分类函数
| 函数 | 如果他的参数符合下列条件就返回真 |
|---|---|
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行’\n’,回车‘\r’,制表符’\t’或者垂直制表符’\v’ |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母af,大写字母AF |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母az或AZ |
| isalnum | 字母或者数字,az,AZ,0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
5.2 字符转换
int tolower ( int c );
int toupper ( int c );
#include 
6.写在最后
那么这一次的字符函数和字符串函数的笔记就到这里啦。小沐会持续更新字符函数和字符串函数。
不去努力争取,那你连失败的资格都没有!
