Flink Configuration 配置文件的配置
Flink Configuration | flink-conf.yaml中的配置
-
-
-
- Basic Setup | 常用配置
-
- Hostnames / Ports
- Memory Sizes(内存大小)
- Parallelism (并行度)
- Checkpointing(检查点)
- Web UI
- Other
- Common Setup Options | 通用的配置
-
- Hosts and Ports
- Fault Toleranc(容错)
- Checkpoints and State Backends(检查点和状态后端)
-
-
引流:FLINK 的命令 FLINK 的配置 Flink执行说明
本篇博客只对flink-conf.yaml中的配置进行介绍
持续更新…
参考文章:
Flink Configuration - flink-conf.yaml 中的配置
Flink 配置文件 flink-conf.yaml 中的配置基本都是通过键值对的方式进行配置
当 Flink 进程启动时,配置会被解析和配置,因此配置文件是全局配置,更改配置文件需要重新启动 Flink 相关的进程
Flink 使用的 JAVA_HOME 为当前环境默认的 JAVA 环境,如果要使用自定义的 JAVA ,需要在该配置文件中通过 env.java.home 进行配置
Flink 解压后有一个 conf 文件夹,我们一般在该文件夹中 flink-conf.yaml 配置文件进行配置。对于非会话部署模式,我们也可以复制该文件夹到其他的地方,并通过环境变量 FLINK_CONF_DIR 指定配置文件夹的位置,从而实现不同的作业使用不同的配置
Basic Setup | 常用配置
默认配置支持在不做任何更改的情况下启动单节点 Flink 会话集群
这里主要是常用的配置
Hostnames / Ports
这个配置用于 standalone 或 Session 模式,如果使用 YARN, hostnames 和 ports 会自动配置和发现
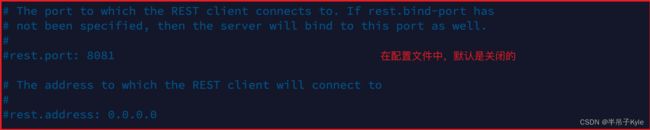
# 该配置用于客户端 client 连接 Flink, 将此设置为 JobManager 运行的主机名和端口(该配置决定WEB的地址和端口)
# 默认为 '0.0.0.0'
rest.address
# 默认为 '8081'
rest.port
# 该配置用于 TaskManager 连接 JobManager, 一般将此设置为 JobManager 运行的主机名(该配置决定TaskManager连接JobManager时的地址和端口)
# 默认为 'localhost'
jobmanager.rpc.address
# 默认为 '6123'
jobmanager.rpc.port
# 我们在 FLINK bin 目录中开启一个会话模式,测试一下默认不开启时的情况
# 该命令在 node02 执行
bin/yarn-session.sh
启动后提示WEB 的地址为图中所示,我们访问下该地址

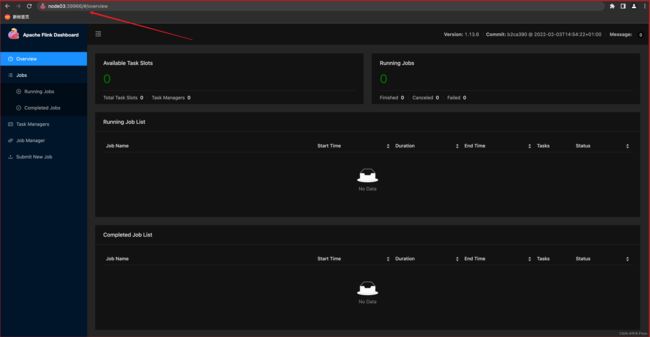
由此说明,该配置如果没有开启,那么 hostname 和 port 随机指定
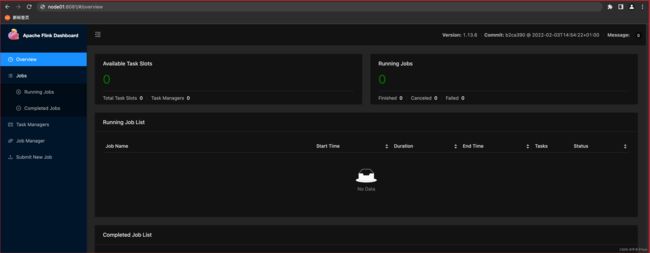
# 配置后重新开启会话
rest.address : 127.0.0.1
rest.port : 8081

Memory Sizes(内存大小)
默认内存大小支持简单的流/批处理应用程序,但太低可能无法为更复杂的应用程序产生良好的性能
# JobManager(JobMaster / ResourceManager / Dispatcher) 进程的总内存大小
jobmanager.memory.process.size: 1600m
# taskmanager 进程的总内存大小
taskmanager.memory.process.size: 1728m
该内存大小为 JAVA 进程的内存,Flink 会为 JVM 自身的内存需求(元空间等)减去一些内存,在其组件之间自动划分和配置其余部分(JVM 堆、堆外,对于任务管理器,还有网络、托管内存等)
配置的格式一般为 xxm 或 xxg , 例如 2048m 或 2g
Parallelism (并行度)
TaskManager 提供的槽数(默认值:1),每个插槽可以接受一个任务,TaskManager 中拥有多个插槽有助于在并行 task 或 pipeline 之间分摊某些恒定开销(JVM、应用程序库或网络连接)
运行多个较小的 TaskManager,每个都有一个插槽是一个很好的策略,可以让任务之间的保持最佳隔离
运行少量较大的 TaskManager,每个 TaskManager 都有多个 slots,可以提高资源利用率,但代价是任务之间的隔离较弱(多个任务共享一个JVM)
# taskmanager 提供的 slots 数量
taskmanager.numberOfTaskSlots: 1
# 默认的并行度
parallelism.default: 1
Checkpointing(检查点)
我们一般会在应用中通过代码配置检查点,为了防止代码中没有配置检查点,因此在配置文件中增加了检查点的默认配置(默认不开启,如需开启需要配置)
代码中的检查点配置的优先级大于配置文件中的检查点配置
# 要使用的状态后端, 此处定义用于创建快照的数据结构机制, 常用的是文件系统或rocksdb
state.backend: filesystem
# 检查点数据的写出目录, 例如:hdfs://namenode:port/flink/checkpoints
state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# 检查点的保存目录
state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints
# 检查点的写出时间间隔, 当在配置文件中开启后, 需要设置该配置, 通常配置的值大于0
execution.checkpointing.interval: 10
Web UI
FLINK 的 WEB 界面的一些配置
# 启用通过 Flink UI 上传和启动作业(默认为 true)
# 注意: 即使禁用此功能,会话集群仍会通过 REST 请求(HTTP 调用)接受作业, 该配置仅保护在 UI 中上传作业的功能
web.submit.enable: true
# 启用通过 Flink UI 取消作业(默认为 true)
# 注意: 即使禁用此功能,会话集群仍会通过 REST 请求(HTTP 调用)取消作业, 该配置仅保护取消 UI 中的作业的功能
web.cancel.enable
# 存储上传作业的目录, 仅在 web.submit.enable 为 true 时使用
web.upload.dir
# 设置打印 Flink 为作业处理的最近失败的异常历史记录的大小
web.exception-history-size
Other
# Flink 存放本地数据的目录, 默认为系统临时目录(java.io.tmpdir 属性), 如果配置了目录列表,Flink 将在目录之间轮换文件
# 默认情况下,放在这些目录中的数据包括 RocksDB 创建的文件、溢出的中间结果(批处理算法)和缓存的 jar 文件
# 此数据不依赖于持久性/恢复,但如果此数据被删除,通常会导致重量级恢复操作, 因此建议将其设置为不会自动定期清除的目录
io.tmp.dirs
Common Setup Options | 通用的配置
Hosts and Ports
为不同 Flink Components 配置主机名和端口的选项
JobManager 主机名和端口仅与没有高可用性的独立设置相关
在该设置中,TaskManager 使用配置值来查找(并连接到)JobManager
在所有高可用设置中,TaskManagers 通过 High-Availability-Service(例如 ZooKeeper)发现 JobManager
注意:不需要配置任何 TaskManager 主机和端口,除非设置需要使用特定的端口范围或特定的网络接口来绑定
| Key | Default | Type | Description |
|---|---|---|---|
| jobmanager.rpc.address | (none) | String | 配置参数定义要连接到JobManager的网络地址,以便与其进行通信 该值仅在存在具有静态名称或地址的 Single JobManager 时进行配置(simple standalone 或具有动态服务名称解析的容器设置), JobManager 为高可用时不配置该项 |
| jobmanager.rpc.port | 6123 | Integer | 配置要连接到的网络端口以与JobManager通信 |
| metrics.internal.query-service.port | “0” | String | Flink 内部 Metric 查询服务使用的端口范围 可以配置一个端口列表,例如 (“50100,50101”); 也可以配置一个范围, 例如(“50100-50200”) 或者两种都可以.建议设置一个端口范围,以避免在同一台机器上运行多个 Flink 组件时发生冲突.默认情况下, Flink 会选择一个随机端口. |
| rest.address | (none) | String | 客户端应该用来连接到服务器的地址 注意: 仅当高可用性配置为 NONE 时才考虑此选项的配置. |
| rest.bind-address | (none) | String | 客户端提供对外访问的地址和端口是rest.port和rest.address 如果没有配置rest.bind-port, 那么其他服务也使用rest.port端口,所以只要使用其中一个启动模式,其他模式在启动时就会报错端口无法启动 因此配置该项后, 其他 Job 启动后,就会在 rest.bind-address 和 rest.bind-port 随机选择并占用. |
| rest.bind-port | “8081” | String | 配合 rest.bind-address 和 rest.port 使用 如果 rest.port 的端口占用, 则使用 rest.bind-port 指定的端口范围 |
| rest.port | 8081 | Integer | 配合 rest.address 使用 |
| taskmanager.data.port | 0 | Integer | 用于数据交换操作的TaskManager的外部端口 |
| taskmanager.host | (none) | String | TaskManager 暴露的网络接口的外部地址 因为不同的 TaskManager 需要不同的值来设置这个选项, 所以通常在一个额外的非共享 TaskManager 特定的配置文件中指定 |
| taskmanager.rpc.port | “0” | String | TaskManager 暴露的外部 RPC 端口 接受端口列表(“50100,50101”)、范围(“50100-50200”)或两者的组合 建议设置一个端口范围, 以避免在同一台机器上运行多个 TaskManager 时发生冲突 |
Fault Toleranc(容错)
这些配置选项控制 Flink 在执行过程中出现故障时的重启行为。 通过在 flink-conf.yaml 中配置这些选项,我们以定义集群的默认重启策略
注意:只有在没有通过 ExecutionConfig 配置作业特定的重启策略时,默认重启策略才会生效
| Key | Default | Type | Description |
|---|---|---|---|
| restart-strategy | (none) | String | JOB 执行失败时的重启策略,共有以下几种: ① none :默认没有重启策略② disable: 没有重启策略③ fixeddelay:固定重试次数的任务失败策略④ failurerate:一段时间内失败率达到阈值,则停止重试⑤ exponentialdelay: 指数延迟重启策略尝试无限重启作业,延迟增加直到最大延迟 |
No Restart Strategy
作业直接失败, 不尝试重新启动
restart-strategy: none
Fixed Delay Restart Strategy
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
| Key | Default | Type | Description |
|---|---|---|---|
| restart-strategy.fixed-delay.attempts | 1 | Integer | 失败重试的次数 |
| restart-strategy.fixed-delay.delay | 1 s | Duration | 如果 restart-strategy 已设置为 fixed-delay,该配置为两次连续重启尝试之间的延迟s时间, 当程序与外部系统交互时, 延迟重试会很有帮助, 例如连接或挂起的事务应该在尝试重新执行之前达到超时. 可以使用符号来指定:“1 min”、“20 s” |
Failure Rate Restart Strategy
失败率重启策略在失败后重新启动作业, 但是当超过失败率(每个时间间隔的失败次数)时, 作业最终会失败
在两次连续重启尝试之间,重启策略会等待固定的时间
# 重试策略设置为: failure-rate
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
| Key | Default | Type | Description |
|---|---|---|---|
| restart-strategy.failure-rate.delay | 1 s | Duration | 两次连续重启尝试之间的延迟, 可以使用符号来指定:“1 min”、“20 s” |
| restart-strategy.failure-rate.failure-rate-interval | 1 min | Duration | 测量故障率的时间间隔, 可以使用符号来指定:“1 min”、“20 s” |
| restart-strategy.failure-rate.max-failures-per-interval | 1 | Integer | 作业失败之前给定时间间隔内的最大重新启动次数 |
Exponential Delay Restart Strategy
指数延迟重启策略尝试无限重启作业, 延迟增加直到最大延迟
工作永远不会失败, 在两次连续的重启尝试之间, 重启策略保持指数增长, 直到达到最大次数, 它将延迟保持在最大数量
当作业正确执行时, 指数延迟值会在一段时间后重置, 这个阈值是可配置的
restart-strategy: exponential-delay
restart-strategy.exponential-delay.initial-backoff: 10 s
restart-strategy.exponential-delay.max-backoff: 2 min
restart-strategy.exponential-delay.backoff-multiplier: 2.0
restart-strategy.exponential-delay.reset-backoff-threshold: 10 min
restart-strategy.exponential-delay.jitter-factor: 0.1
| Key | Default | Type | Description |
|---|---|---|---|
| restart-strategy.exponential-delay.backoff-multiplier | 2.0 | Double | 每次失败后, backoff value 都会乘以该值 |
| restart-strategy.exponential-delay.initial-backoff | 1 s | Duration | 重新启动之间的启动持续时间, 可以使用符号来指定:“1 min”、“20 s” |
| restart-strategy.exponential-delay.jitter-factor | 0.1 | Double | 抖动指定为退避的一部分, 它表示将在退避中添加或减去多大的随机值, 如果想避免同时重新启动多个作业时很有用 |
| restart-strategy.exponential-delay.max-backoff | 5 min | Duration | 重新启动之间可能的最长持续时间, 可以使用符号来指定:“1 min”、“20 s” |
| restart-strategy.exponential-delay.reset-backoff-threshold | 1 h | Duration | 退避重置为其初始值时的阈值 它指定作业必须运行多长时间才能将指数增加的退避重置为其初始值,可以使用符号来指定:“1 min”、“20 s” |
Checkpoints and State Backends(检查点和状态后端)
| Key | Default | Type | Description |
|---|---|---|---|
| state.backend | (none) | String | 用于存储状态的状态后端 |
| state.checkpoint-storage | (none) | String | 用于检查点状态的检查点存储实现 |
| state.checkpoints.dir | (none) | String | Flink 支持的文件系统中用于存储检查点的数据文件和元数据的默认目录 存储路径必须可以从所有参与的进程/节点(即所有 TaskManager 和 JobManager)访问 |
| state.savepoints.dir | (none) | String | 保存点的默认目录。 由将保存点写入文件系统的状态后端使用 (HashMapStateBackend, EmbeddedRocksDBStateBackend) |
| state.backend.incremental | false | Boolean | 选择状态后端是否应创建增量检查点 对于增量检查点,只存储与前一个检查点的差异,而不是完整的检查点状态 启用后, Web UI 中显示的状态大小或从 Rest API 获取的状态大小仅表示增量检查点大小, 而不是完整检查点大小 一些状态后端可能不支持增量检查点并忽略此选项 |
| state.backend.local-recovery | false | Boolean | 此选项为此状态后端配置本地恢复, 默认情况下,本地恢复已停用 本地恢复目前仅涵盖键控状态后端, 目前, MemoryStateBackend 不支持本地恢复并忽略此选项 |
| state.checkpoints.num-retained | 1 | Integer | 要保留的已完成检查点的最大数量 |
| taskmanager.state.local.root-dirs | (none) | String | config 参数定义用于存储基于文件的状态以进行本地恢复的根目录本地恢复 目前仅涵盖键控状态后端, 目前 MemoryStateBackend 不支持本地恢复, 忽略该选项 |