特征提取方法:One-hot、TF-IDF、Word2vec
文章目录
- 1.One-hot
-
- 定义
- 优点与缺点
- Python实现
- 2.TF-IDF
-
- 定义
- 算法原理
-
- TF(Term Frequency)
- IDF(Inverse Document Frequency)
- TF-IDF(Term Frequency–Inverse Document Frequency)
- 存在缺点与改进方案
- Python实现
-
- CountVectorizer & TdidfTransfomer
- TfidfVectorizer
- 3.Word2vec
-
- 定义
- CBOW & Skip-gram模型
- Python实现
- 参考资料
1.One-hot
定义
one-hot编码又称独热码,该编码使用n位状态寄存器对n个状态进行编码,而且只有一个比特位为1,其他位全为0。也就是说,每个状态都有其独立的寄存器位和编码表示,且在任意时刻有且仅有一位有效。
优点与缺点
优点:使得离散状态的原始数据变得“连续”且有序,便于后续分类器等处理;在一定程度上扩充了特征的取值空间,便于分析计算。
缺点:One-hot编码属于词袋模型,未考虑词与词之间的顺序关系和语义关系(而这两点因素对于文本分类等工作具有重要影响);产生的特征还是离散稀疏的。
Python实现
借助Python的sklearn库中提供的工具类,可以实现one-hot编码功能。代码演示如下:
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
# X为输入语料
#X = [['Male', 1], ['Female', 3], ['Female', 2]]
# 训练编码
enc.fit(X)
# 生成编码序列
arr = enc.transform([['Female', 1], ['Male', 3]]).toarray()
2.TF-IDF
定义
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
——百度百科
算法原理
TF(Term Frequency)
TF为词频,表示单个词条在目标文档中出现的频次,即 t f i j = n i j tf_{ij}=n_{ij} tfij=nij,其中 n i j n_{ij} nij表示文档 d j d_j dj中词 t i t_i ti出现的次数。
但考虑到同一个词条在不同篇幅的文章中出现的次数对TF值的干扰,因此考虑将TF值进行归一化,即将原始词频除以该文档的词条总数作为最终值。其计算公式如下: t f i j = n i j ∑ k n k j tf_{ij}=\frac{n_{ij}}{\sum_kn_{kj}} tfij=∑knkjnij其中,分母即表示目标文档的词条总数目。
IDF(Inverse Document Frequency)
IDF为逆文本频率指数,见名思义,其对应于DF(文本频率指数)的逆向指标。DF表示在总体语料库中包含指定词条的文档数目,其计算公式如下: d f i j = ∣ { j : t i ∈ d j } ∣ df_{ij} = \mid\lbrace j:t_i\in d_j \rbrace\mid dfij=∣{j:ti∈dj}∣上式即表示给定语料库中包含词条 t i t_i ti的文档数目。
理论上,IDF只需取DF的倒数即可表明其意义。但这样做存在以下三点问题:
- 可能存在某一词条在所有文档中均未包含,此时DF的值取0
- 上述关于DF的计算方式,一方面会像计算原始TF一样受到语料库中文档规模的影响
- 当总体语料库中的文档达到一定规模之后,可以想到,IDF的值不再会随着文档数目的增加而进行类似的线性增长
因此,针对第一个问题,我们设定在原始DF的基础上统一加1,进行非零化处理;而针对第二个问题,我们同样采取归一化的策略,即将原始文本频率指数除以总体语料库中的文档总数。改进后的DF计算公式如下: d f i j = ∣ { j : t i ∈ d j } ∣ + 1 ∣ D ∣ df_{ij}=\frac{\mid\lbrace j:t_i\in d_j \rbrace\mid+1}{\mid D\mid} dfij=∣D∣∣{j:ti∈dj}∣+1其中, ∣ D ∣ \mid D\mid ∣D∣表示语料库中的文档总数。
此时,通过对上述公式计算出的DF值取反,可以初步得到对应的IDF值。但为了解决第三个问题,我们需要利用对数函数变换来对初步得到的IDF进行处理。因此,最终的IDF计算公式如下: i d f i = log 1 d f i = log ∣ D ∣ ∣ { j : t i ∈ d j } ∣ + 1 idf_i=\log \frac{1}{df_i}=\log \frac{\mid D\mid}{\mid\lbrace j:t_i\in d_j \rbrace\mid+1} idfi=logdfi1=log∣{j:ti∈dj}∣+1∣D∣
TF-IDF(Term Frequency–Inverse Document Frequency)
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,通过综合考虑TF和IDF的值,即可得到最终的TF-IDF属性值。其计算公式如下。
t f i d f i j = t f i j × i d f i = n i j ∑ k n k j × log ∣ D ∣ ∣ { j : t i ∈ d j } ∣ + 1 tfidf_{ij}= {tf_{ij}}\times{idf_i}=\frac{n_{ij}}{\sum_kn_{kj}}\times\log \frac{\mid D\mid}{\mid\lbrace j:t_i\in d_j \rbrace\mid+1} tfidfij=tfij×idfi=∑knkjnij×log∣{j:ti∈dj}∣+1∣D∣
存在缺点与改进方案
TF-IDF算法的实现原理比较简单,但也存在一些缺点与不足:
- 对于文本中意义相近的词语,诸如TF-IDF这类基于词频统计的分词算法只能将其分开统计而不能合并处理,一定程度上影响了提取出的关键词结果的精确度。
- IDF简单地以文本频率来判断单词的重要性,一方面使得文中的一些生僻词可能因IDF值较高被误当作关键词提取出来,另一方面使得同类别文本语料库中的关键词可能因IDF值过低无法被完整提取,这些问题的存在使得IDF无法有效地反映单词的重要性和特征词的分布情况。
- 通过TF-IDF算法计算出的词语权值一般很小(趋近于0),精确度也不是很高。
基于上述问题,可从多个角度对现有的TF-IDF方法进行适当地改进:
- 对文本进行段落标注,对不同位置的词语赋予不同的权重以体现其重要性。
- 对同词性非生僻词(比如词频$\geq$2)进行相似度计算,对满足相似度阈值要求的词语组合进行合并处理。
- 将IDF优化为IWF(Inverse Word Frequency): I W F i = log ∑ i = 1 n n t i n t i IWF_i=\log\frac{\sum\limits_{i=1}^nnt_i}{nt_i} IWFi=logntii=1∑nnti其中,对数内分子表示语料库中所有词语的频数总和,分母表示特定词语 t i t_i ti在语料库中出现的总频数。
Python实现
借助Python的sklearn库中提供的相关工具类,可以实现TF-IDF的相关功能。代码演示如下:
CountVectorizer & TdidfTransfomer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
# 将文本中的词转化为词频矩阵
vectorizer=CountVectorizer()
# corpus表示语料输入
# corpus = ['This is the first document.\n', 'This document is the second document.\n', 'And this is the third one.\n', 'Is this the first document?']
X=vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())
# 统计每个词语的if-idf权值
transformer=TfidfTransformer()
tf_idf=transformer.fit_transform(X)
print(tf_idf.toarray())
TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer=TfidfVectorizer()
tf_idf=vectorizer.fit_transform(corpus)
print(tf_idf.toarray())
3.Word2vec
定义
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,可用来映射每个词到一个向量,也可用来表示词对词之间的关系,该向量为神经网络之隐藏层。Word2vec可以根据给定的语料库,通过优化后的训练模型快速有效地将一个词语表达成向量形式。Word2vec依赖skip-gram或连续词袋(CBOW)模型来建立神经词嵌入,同时又可以通过hirerarchical softmax和negative sampling技术进行参数优化。
CBOW & Skip-gram模型
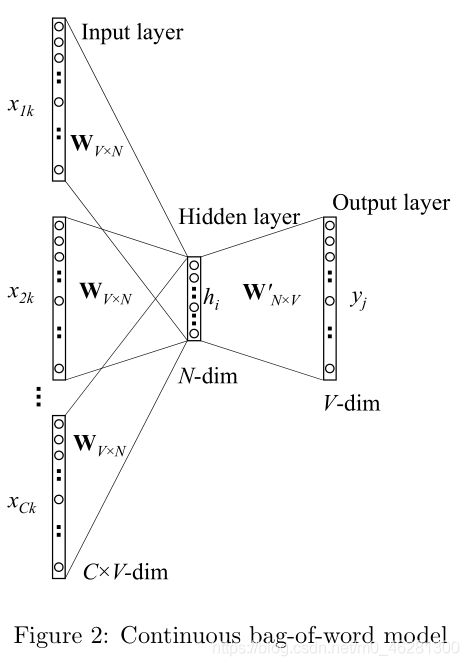
CBOW(Continuous Bag-of-Words)模型是根据输入的关于某一特定中心词的上下文相关词对应的词向量,输出这一中心词对应的词向量。
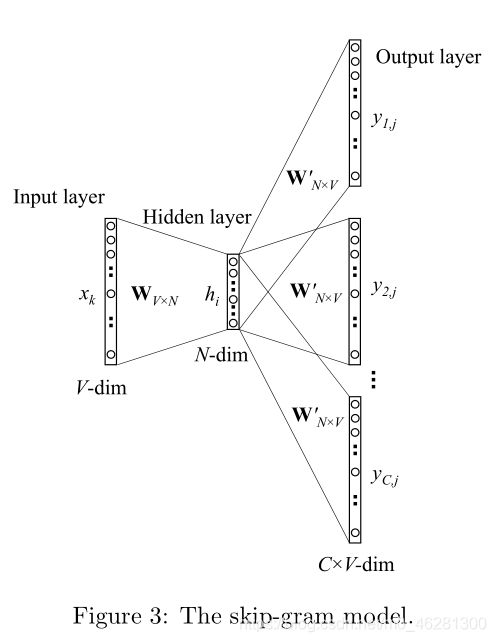
Skip-gram模型则是根据输入的特定中心词对应的词向量,输出其对应的上下文相关词的词向量。
两种模型的训练示意图如下所示:
Python实现
借助Python的gensim库中提供的Word2vec相关API,可以实现Word2vec的相关模型功能。代码演示如下:
from gensim.models import Word2Vec
# sentences为预料输入
# sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
# 初始化词向量模型
model = Word2Vec(min_count=1)
# 准备词汇语料
model.build_vocab(sentences)
# 查看特定词的词向量
print(model.wv["say"])
参考资料
[1] 王小林, 杨林, 王东,等. 改进的TF-IDF关键词提取方法[J]. computer science&\application, 2013, 03(01):64-68.
[2] scikit-learn:feature_extraction modules
[3] Rong X . word2vec Parameter Learning Explained[J]. Computer ence, 2014.
[4] gensim:Word2vec embeddings