Python数据分析刷题:(一)查看数据
Python数据分析刷题:(一)查看数据
最近小伙伴问我有什么刷题网站推荐,在这里推荐一下牛客网,里面包含各种面经题库,全是免费的题库,可以全方面提升你的职业竞争力,提升编程实战技巧,赶快来和我一起刷题吧!
牛客网链接|Python数据分析篇
参考资料:Python数据分析大杀器之Pandas基础2万字详解
注册后点击题库——在线编程即可进入到我们的刷题界面,大家可以根据自己的需求选择相应的模块进行联系。本系列文章和大家一起刷牛客Python数据分析篇新题库。废话少说,直接开始刷题
Q1.使用pandas查看牛客网用户数据
描述
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
你可以使用pandas打开文件,偷偷看一下里面的内容,请输出你看到的前6行数据。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集的前6行,如下所示:


分析: 这里我们需要返回数据集的前6行,需要使用pandas的head()函数,默认是返回前5行的数据,因此我们只需要指定df.head(6)即可。对pandas不熟悉的小伙伴可以看这篇文章Python数据分析大杀器之Pandas基础2万字详解
代码
import pandas as pd #导入pandas库
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",", dtype=object)#读取数据,打开文件时需要添加dtype=object,防止年份信息读取为小数。
print(Nowcoder.head(6)) # 返回前6行数据,并打印
Q2.牛客网用户数据集的大小
描述
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
你不需要输出全部数据,请直接告诉我们这个数据集的大小,即行数与列数。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集的行数与列数,如下所示:

分析:返回数据集大小需要使用
df.shape
代码
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.shape)
Q3.牛客网的第10位用户
描述
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
现在牛牛想知道这个数据集中第10行的用户的全部信息,请你帮他输出一下。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集第10行的全部信息,每列信息单独成行,如下所示:
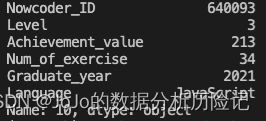
分析:要找到第十行的信息,这是一个索引问题,可以使用
iloc和loc来实现
代码
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.iloc[10])
Q4.统计牛客网部分用户使用的语言
描述
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
现在牛牛想知道这个数据集中第10行到第20行的用户的常用语言分别是什么,请你帮他输出一下。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。输出描述:
输出该数据集第10行到第20行的常用语言,每行数据单独成行,如下所示:

分析:这里需要同时对行和列进行索引,这里提供两种方案进行检索,分别使用loc和iloc
代码
# 方法一:使用iloc
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.iloc[10:21,5])
# 方法二:使用loc
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.loc[10:20,'Language'])
iloc和loc的关系:
1.iloc的列不能用列标签;loc的列只能用列标签
2.loc左闭右闭,iloc左闭右开;
Q5.查看牛客网用户没有补全的信息
描述
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
如果你想知道这份数据是不是所有列的信息都是有数据的,有没有哪些列的数据没有补全,请输出每列信息是否有为空值。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集每列信息是否有为空值,如下所示:


分析:这里需要统计缺失值的信息,使用isna()或者isnull()可以判断缺失值信息,同时注意这里我们要得到的是存在缺失值的列,因此,我们还需要使用any()
代码
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.isnull().any())
链接地址:牛客网|Python篇一起刷起来吧!