使用BERT + Bi-LSTM + CRF 实现命名实体识别
文章目录
- 1.前言
- 2.数据预处理
-
-
- 2.1本地查看数据转换后的结果
-
- 3.构建数据集
- 4.数据集分割
- 5.模型架构
-
-
- 5.1模型初始化
- 5.2前向传播过程
-
- 6.模型训练
-
-
- 6.1训练一个epoch
- 6.2训练所有epoch
- 6.3evaluate函数
-
- 7.整体训练过程
1.前言
- 本文主要分析本次实验的代码,讲解主要流程和代码含义,并不关注参数的选择和模型的选择
- 后续可能还会更新
model的原理 - 如果有问题,欢迎评论或私聊讨论
- 若分析过程出现错误,请及时指正,谢谢
2.数据预处理
- 原始标注:对句子中的每个字标注上一个标签,可以简单地看成是直接对每个字分类(需要融合上下文信息),因此可以使用一个多分类器,分类器输出类别就是该字的标签
- 联合标注:对一串连续的字标注相同的标签。在NER任务中,实体由一个或多个字组成,所以它属于联合标注任务。
但是在联合标注中,相邻词语标签之间可能会存在依赖关系。这一问题可以通过标签转化的方式,把联合标注转化成原始标注解决。
我们这里使用的是BIOS标注
| 标签 | 含义 |
|---|---|
| B-X | 该字是词片段 X 的起始字 |
| I-X | 该字是词片段 X 起始字之后的字 |
| S-X | 该字单独标记为 X 标签 |
| O | 该字不属于事先定义的任何词片段类型 |
在process.py中,我们将.json文件中的语句和标签,按照BIOS方式,处理转换成了.npz文件。主要代码如下。分析过程写在注释中,依据样例.json。
text = json_line['text']
words = list(text) # 自动将句子按字符分开
# 如果没有label,则返回None
label_entities = json_line.get('label', None) # 参照下面的例子, 该项对应 label 之后的内容
labels = ['O'] * len(words) # [len(words) 个 'O'] 都初始化为 `O`
if label_entities is not None:
for key, value in label_entities.items(): # key 对应 name 和 company, value 对应后面存储内容
for sub_name, sub_index in value.items(): # sub_name 对应 叶老桂等, sub_value 对应后面的索引
for start_index, end_index in sub_index: # 对应列表中的两个数,是标签开始和结束的位置
assert ''.join(words[start_index:end_index + 1]) == sub_name
if start_index == end_index: # 单个字作为索引
labels[start_index] = 'S-' + key
else:
labels[start_index] = 'B-' + key # 开头
labels[start_index + 1:end_index + 1] = ['I-' + key] * (len(sub_name) - 1) # 中间的字
-
字符串转
list验证- 这里很重要的一点是,输入的字符串都转成单字符了,下面使用 tokenize 的时候会看到为什么
a = "你好,我是nsy,哈哈哈" print(list(a)) >>['你', '好', ',', '我', '是', 'n', 's', 'y', ',', '哈', '哈', '哈']
.json文件中,数据存储结构如下所示
{
"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,",
"label": {
"name": {
"叶老桂": [
[9, 11],
[32, 34]
]
},
"company": {
"浙商银行": [
[0, 3]
]
}
}
}
2.1本地查看数据转换后的结果
-
code
import numpy as np a = np.load(r'D:\2022 spring\nlp\exp4\code\BERT-LSTM-CRF\data\clue\test.npz', allow_pickle=True) index = 0 words = a['words'] labels = a['labels'] print(words[0]) print(labels[0]) -
结果
['彭', '小', '军', '认', '为', ',', '国', '内', '银', '行', '现', '在', '走', '的', '是', '台', '湾', '的', '发', '卡', '模', '式', ',', '先', '通', '过', '跑', '马', '圈', '地', '再', '在', '圈', '的', '地', '里', '面', '选', '择', '客', '户', ','] ['B-name', 'I-name', 'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-address', 'I-address', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
3.构建数据集
我们构建自己的数据集Dataset类。该类主要属性为
self.tokenizer = BertTokenizer.from_pretrained(config.bert_model, do_lower_case=True)
self.label2id = config.label2id
self.id2label = {_id: _label for _label, _id in list(config.label2id.items())}
self.dataset = self.preprocess(words, labels)
self.word_pad_idx = word_pad_idx # 起初始化作用的
self.label_pad_idx = label_pad_idx # 起初始化作用的
self.device = config.device
-
因为我们加载的数据是
.npz文件中的,数据(不是label)是存在列表中的单个字符,我们不进行分词工作了。所以这里的tokenizer属性主要是将大写字母转化为小写字母 -
一个比较难理解的属性是
self.dataset,我们来看看里面到底是什么内容。preprocess函数如下。函数主要功能为- 在每句话前面加一个开头
CLS - 将原始字符/字都转换成
id,并存储有label的字的开始位置的索引 - 将
label转成成id - 注意:代码中
token的长度都是1,这是由.npz中的数据作为输入决定的
def preprocess(self, origin_sentences, origin_labels): # 输入的是 .npz 里面的数据 """ Maps tokens and tags to their indices and stores them in the dict data. examples: word:['[CLS]', '浙', '商', '银', '行', '企', '业', '信', '贷', '部'] sentence:([101, 3851, 1555, 7213, 6121, 821, 689, 928, 6587, 6956], array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])) label:[3, 13, 13, 13, 0, 0, 0, 0, 0] """ data = [] sentences = [] labels = [] for line in origin_sentences: # 处理每一句话,类型为 list words = [] word_lens = [] for token in line: # 一句话中的每个词 words.append(self.tokenizer.tokenize(token)) # tokennize结果:'浙'->['浙'] word_lens.append(len(token)) # len(token) 全是 1 # 开头加上[CLS] words = ['[CLS]'] + [item for token in words for item in token] # token 是字符列表, item 是 token 中的项, 也就是单个字 token_start_idxs = 1 + np.cumsum([0] + word_lens[:-1]) # 除了 `[CLS]` 之外的索引, 写成一个列表 sentences.append((self.tokenizer.convert_tokens_to_ids(words), token_start_idxs)) # 将 token 的 id 和 index 一起加入 setences for tag in origin_labels: # tag 是每一行的 origin_sentences 中的字对应的 label label_id = [self.label2id.get(t) for t in tag] # 每个字的 label -> id labels.append(label_id) for sentence, label in zip(sentences, labels): data.append((sentence, label)) return data # 作为 self.dataset-
比较难理解的部分
for token in line: words.append(self.tokenizer.tokenize(token)) word_lens.append(len(token)) words = ['[CLS]'] + [item for token in words for item in token] token_start_idxs = 1 + np.cumsum([0] + word_lens[:-1])-
对上面的例子来说,
tokenize效果就是浙->['浙']-
tokenize其实有分词的作用,比如import torch import numpy as np from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained('pretrained_bert_models/bert-base-chinese/', do_lower_case=True) print(tokenizer.tokenize("unwanted")) print(tokenizer.tokenize("===+")) >>['u', '##n', '##wan', '##ted'] >>['=', '=', '=', '+'] -
如果有上述功能,
len(token)和 真实索引开始位置就对不上了,比如unwanted进行tokenize之后提供四个部分,但是索引却要 + 8 -
这里的字符全是单个的(上面解释过),因此只有大写 -> 小写的作用
-
-
for循环之后,得到words = [['浙'], ['商'], ['银'], ['行'], ['企'], ['业'], ['信'], ['贷'], ['部']],大写变小写在这里没有体现。word_lens=[1,1,1,1,1,1,1,1,1] -
下一步
words->['[CLS]', '浙', '商', '银', '行', '企', '业', '信', '贷', '部'] -
word_lens去掉最后一个,前面添加一个0,然后前向求和 + 1,得到[ 1, 2, 3, 4, 5, 6, 7, 8, 9]。我认为样例的数字错了(代码没问题,本人已经测试过)。我感觉直接对word_lens前向求和就行
-
- 在每句话前面加一个开头
-
该部分还有一个主要函数是
collate_fn(self, batch)。主要功能为:- 将每个
batch的data扩充到同一长度(batch中最长的data的长度)- 先找到最大的长度
- 初始化一个矩阵(句子个数, 最大句子长度), 初始化值为
0 - 将相应的值放到对应的索引上
- 将每个
batch的label扩充到统一长度(batch中最长的label的长度)- 先找到最大的长度
- 初始化一个矩阵(句子个数, 最大
label长度) - 将相应的值放到对应的索引上
- 将
batch_data, batch_label_starts, batch_labels转换为tensor并移动到GPU上,然后返回
- 将每个
4.数据集分割
我们按照9:1的比例,将训练数据分割成训练集和验证集,代码在run.py中。
# 分离出验证集
word_train, word_dev, label_train, label_dev = load_dev('train')
函数load_dev()代码如下
def dev_split(dataset_dir): # 分出训练集和验证集 参数: BERT-LSTM-CRF/data/clue/train.npz
"""split dev set"""
data = np.load(dataset_dir, allow_pickle=True)
words = data["words"]
labels = data["labels"]
x_train, x_dev, y_train, y_dev = train_test_split(words, labels, test_size=config.dev_split_size, random_state=0) # 测试集大小为 0.1
return x_train, x_dev, y_train, y_dev
5.模型架构
5.1模型初始化
- 我们的模型继承了一个预训练模型
BertPreTrainedModel - 主要属性:
- 一个
bert模型(Transformer的堆叠,bert作为Encoding来使用,对输入数据进行编码) Bert简介_长命百岁️的博客-CSDN博客 dropout层- 一个两层的
bilstm(双向lstm):输出 - 一个线性分类器
- 一个
crf模型 bilstm-CRF模型结构如下所示,代码下面有各层的作用
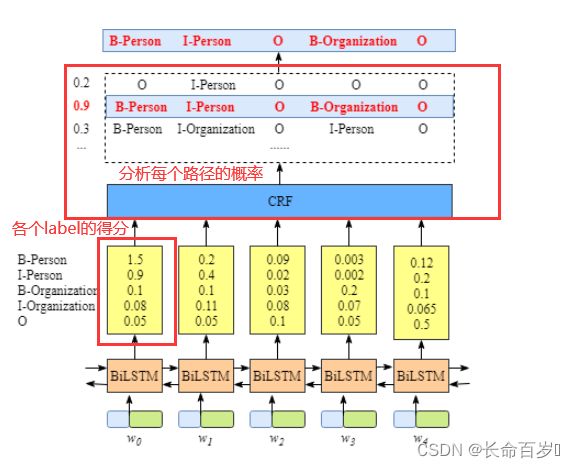
- 一个
class BertNER(BertPreTrainedModel):
def __init__(self, config):
super(BertNER, self).__init__(config)
self.num_labels = config.num_labels # label 的数目
self.bert = BertModel(config) # 定义 bert 模型
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.bilstm = nn.LSTM(
input_size=config.lstm_embedding_size, # 1024
hidden_size=config.hidden_size // 2, # 1024
batch_first=True,
num_layers=2,
dropout=config.lstm_dropout_prob, # 0.5
bidirectional=True
)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.crf = CRF(config.num_labels, batch_first=True)
self.init_weights()

5.2前向传播过程
-
先利用
bert处理输入数据。bert简介可参考- 输入是每个
token对应的表征 - 输出是对输入
token的编码
input_ids, input_token_starts = input_data # 训练数据, 已经扩充到最大维度的 outputs = self.bert(input_ids, # 用 bert 处理 attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds) sequence_output = outputs[0] - 输入是每个
-
将原来有
label的位置对应的输出提取出来# 去除[CLS]标签等位置,获得与label对齐的pre_label表示 origin_sequence_output = [layer[starts.nonzero().squeeze(1)] for layer, starts in zip(sequence_output, input_token_starts)] -
将
origin_sequence_output填充到最大长度# 将sequence_output的pred_label维度padding到最大长度 padded_sequence_output = pad_sequence(origin_sequence_output, batch_first=True) -
将
padded_sequence_output输入bilstm# dropout pred_label的一部分feature padded_sequence_output = self.dropout(padded_sequence_output) # 遮住一部分 lstm_output, _ = self.bilstm(padded_sequence_output) -
进行结果的判别,返回结果
logits是每个位置对有label的打分(对bilstm的输出进行维度变换)大小是(batch_size, max_len, num_labels)
要注意,只有label不是None时,才算loss,否则就会只返回得分。这一点在train.py中,估计不传label参数,从而只计算得分# 得到判别值 logits = self.classifier(lstm_output) outputs = (logits,) if labels is not None: loss_mask = labels.gt(-1) # 我们在对labels长度填充的时候,初始化值为 -1,这里是遮住填充的位置 loss = self.crf(logits, labels, loss_mask) * (-1) outputs = (loss,) + outputs # contain: (loss), scores return outputs对
(loss,) + outputs的解释。可以见到这里是把loss添加到前面,作为元组的第一项a = (1, ) for i in range(10): a = (2, ) + a print(a) >>(2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1)
6.模型训练
6.1训练一个epoch
-
首先开启训练模式,本次实验中其实就是开启
dropout。关于这样做的理由,请参考 Pytorch model.train()_长命百岁️的博客-CSDN博客# set model to training mode model.train() # 开启训练模式, 为了避开测试模式的影响 -
利用
Dataloader类的实例train_loader进行分批训练(一次训练一个batch),train_epoch代码如下:for idx, batch_samples in enumerate(tqdm(train_loader)): # tqdm 是加了一个进度条 batch_data, batch_token_starts, batch_labels = batch_samples batch_masks = batch_data.gt(0) # token 是用 0 初始化的, # 前向传播,计算结果并产生 loss loss = model((batch_data, batch_token_starts), token_type_ids=None, attention_mask=batch_masks, labels=batch_labels)[0] # 第一项是 loss,在上面一点点提到 train_losses += loss.item() # 梯度归0, 反向传播 model.zero_grad() loss.backward() # 梯度裁剪,梯度爆炸的裁剪掉 nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=config.clip_grad) # 更新 optimizer.step() scheduler.step()- 这里的
mask是因为我们对一句话进行了padding,self-attention会关注所有位置,但是我们不想关注padding的位置。因此我们就提取出来这些位置(为0),然后进行mask。
- 这里的
-
返回结果
train_loss = float(train_losses) / len(train_loader) logging.info("Epoch: {}, train loss: {}".format(epoch, train_loss))
6.2训练所有epoch
-
遍历
epoch,调用train_epoch进行参数更新和loss计算for epoch in range(1, config.epoch_num + 1): # 遍历 epoch train_epoch(train_loader, model, optimizer, scheduler, epoch) val_metrics = evaluate(dev_loader, model, mode='dev') # evaluate是自定义函数 val_f1 = val_metrics['f1'] -
根据
f1_score的变化考虑是否保存当前模型,并设置停止训练的条件,若满足条件,则停止训练。
6.3evaluate函数
在这里,mode = 'dev'。利用当前 epoch 的模型对验证集进行预测,计算出metrics['loss'] = float(dev_losses) / len(dev_loader)。并利用预测 label 与真实 label 计算出f1_score = metrics['f1'] 。
- 要注意的是,我们调用
model函数前向传播时,有的输入了label,然后接收output[0],是loss - 有的没输入
label,返回的结果是每个位置对所有label的得分
7.整体训练过程
-
数据预处理
# set the logger utils.set_logger(config.log_dir) logging.info("device: {}".format(config.device)) # 处理数据,分离文本和标签 processor = Processor(config) processor.process() logging.info("--------Process Done!--------") -
划分训练集和验证集,并使用上面构建的
Dataset类,构建数据集(可用于Dataloader)# 分离出验证集 word_train, word_dev, label_train, label_dev = load_dev('train') # build dataset train_dataset = NERDataset(word_train, label_train, config) # 训练数据 dev_dataset = NERDataset(word_dev, label_dev, config) # 验证数据 logging.info("--------Dataset Build!--------") # get dataset size train_size = len(train_dataset) -
将
Dataset类放入DataLoader中,以进行后续的分batch训练# build data_loader train_loader = DataLoader(train_dataset, batch_size=config.batch_size, # 训练集的 DataLoader shuffle=True, collate_fn=train_dataset.collate_fn) dev_loader = DataLoader(dev_dataset, batch_size=config.batch_size, # 验证集的 DataLoader shuffle=True, collate_fn=dev_dataset.collate_fn) logging.info("--------Get Dataloader!--------") -
准备模型
device = config.device # 选择设备,这里选的 GPU model = BertNER.from_pretrained(config.bert_model, num_labels=len(config.label2id)) # 读取预训练模型 model.to(device) # 将模型移动到 GPU 上 -
下面就是模型的参数选择,优化器的选择,调优策略的配置
-
模型训练,保存最优模型
-
模型测试
-
上面三个内容可以参见 用BERT做NER?教你用PyTorch轻松入门Roberta! - 知乎 (zhihu.com)。本文只对代码内容进行讲解,不研究训练的参数选择。
-
因为只是讲解代码,代码并非本人编写,这里附上原作者代码地址 hemingkx/CLUENER2020: A PyTorch implementation of a BiLSTM\BERT\Roberta(+CRF) model for Named Entity Recognition. (github.com)