详解:Hive的存储格式与对比
Hive的存储格式与对比
官网:https://cwiki.apache.org/confluence/display/Hive/FileFormats
对于很多的东西,还是你要多多观看官网,更加权威,
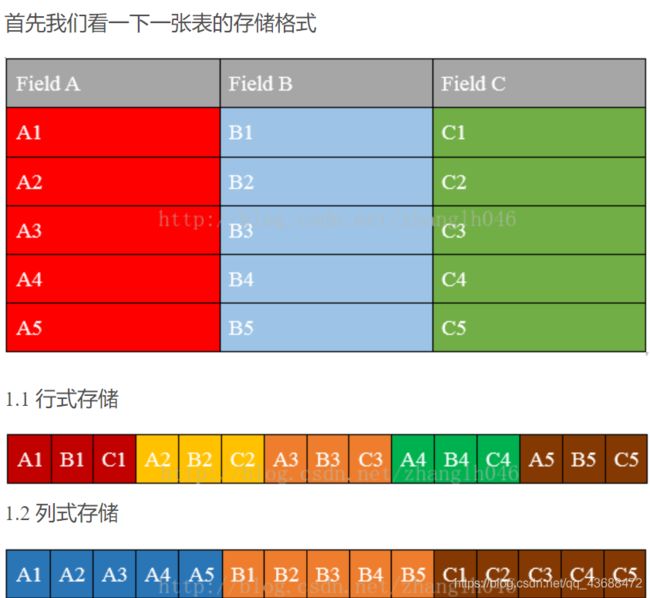
一:行式存储和列式存储
在这之前先补充一个概念:
二:TestFile
这个就是普通的文本格式 ,
TextFile文件不支持块压缩,默认格式,数据不做压缩,磁盘开销大,数据解析开销大
文本格式里面都是字符串类型 对于文本来说是一个全量的 行式存储
比如:我们只需要3列的话,他是要全部加载的,而相对于列式存储来说不是这样的,列式存储是可以直接查看3列的
这样就会有一个很大的 区别:磁盘和 io的使用情况不是一个级别的,现在工作很少使用,空间的节省性能很差啊
三:SequenceFile

SequenceFile 其实是key value的方式存储 数据的存储体积要比text file的大一些
(读起来方便 ,用的也很少的)在使用 压缩的时候是对value压缩
操作的时候 :
如果你想把文本格式text file 转换为sequence file 导入数据的时候
格式不对,没有办法读取的 需要做中间的一步转换 的
load data local inpath '/home/hadoop/data/page' overwrite into table page_seq;
insert into table page_seq select * from page;
要做insert操作的
这两种形式性能太低了 在工作中很少使用的,所以官网也没有做过多的介绍
注意:
并不代表查询的 时候 列式存储就比行式存储快
例如:select * 时的查询时,还是行式存储要快的,很简单,行式存储在一起,列式存储把它分割开的额 但是在大数据的情况下,是几乎不会使用select * 的
生产上在etl之后,几乎都是列式存储 列式存储占据了百分之90的份额
当然还有一个重要的原因:
因为文本里面的数据是各种各样的不同数据 ,如果使用列式存储的话,可以对不多的数据格式,采取不同的压缩格式,更好的做到优化,
重要的一点就是:存储格式与压缩是紧密结合的
四:RCFile
官网:https://cwiki.apache.org/confluence/display/Hive/RCFile
RCFile其实就是 行列混合存储的,性能也不怎么样,现在也很用(比如百度 ) ,测试的效果不好
RCFile结合了行存储和列存储的优点,以满足快速数据加载和查询处理的需求,存储空间的有效利用以及对高度动态工作负载模式的适应性。
作为行存储,RCFile保证同一行中的数据位于同一节点中。
作为列存储,RCFile可以利用逐列数据压缩并跳过不必要的列读取。
五:ORC Files
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
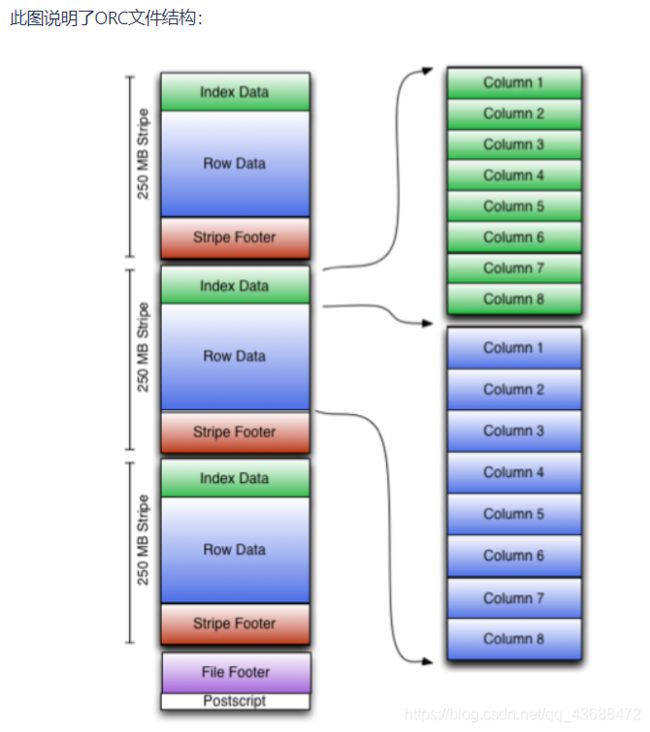
存储方式:数据按行分块 每块按照列存储 ,压缩快 快速列存取,效率比rcfile高,是rcfile的改良版本,相比RC能够更好的压缩,能够更快的查询,但还是不支持模式演进。
他底层有默认的压缩格式
orc.compress default ZLIB
high level compression (one of NONE, ZLIB, SNAPPY)
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="SNAPPY");
六:Parquet
官网:https://cwiki.apache.org/confluence/display/Hive/Parquet
Hive 0.13 and later
CREATE TABLE parquet_test (
id int,
str string,
mp MAP,
lst ARRAY,
strct STRUCT)
PARTITIONED BY (part string)
STORED AS PARQUET;
其实他不是hive里面的,是其他的一个项目 现在是主流框架 存储的角度和计算的角度
支持的版本很多 ,0.13之后直接写一个parquet就可以了
Parquet是不跟任何数据处理技术绑定在一起的,可以用于多种数据处理框架。
查询引擎:Hive,Imapla,Presto等
计算框架:Map-Reduce,Spark等
数据模型:Avro,Thrift,PB
七:性能的对比
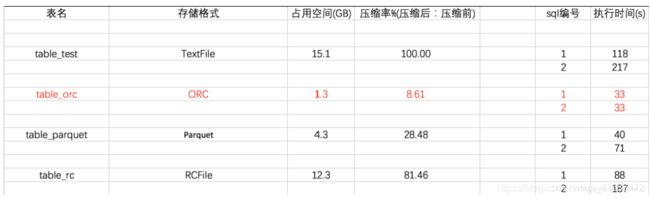
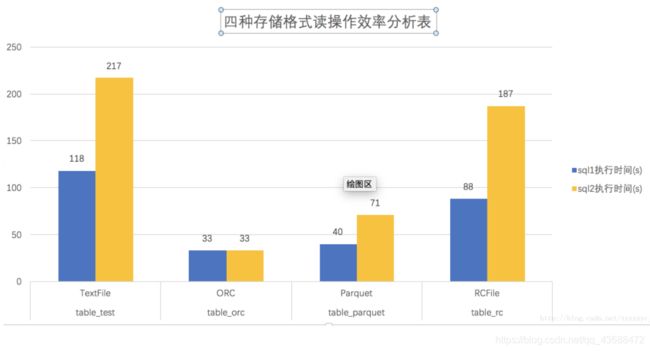
结论:
1.ORC Files存储文件读效率最好
2.耗时比较:ORC
4.占用空间 :ORC