淘宝iOS扫一扫架构升级 - 设计模式的应用
本文在“扫一扫功能的不断迭代,基于设计模式的基本原则,逐步采用设计模式思想进行代码和架构优化”的背景下,对设计模式在扫一扫中新的应用进行了总结。
背景
扫一扫是淘宝镜头页中的一个重要组成,功能运行久远,其历史代码中较少采用面向对象编程思想,而较多采用面向过程的程序设计。
随着扫一扫功能的不断迭代,我们基于设计模式的基本原则,逐步采用设计模式思想进行代码和架构优化。本文就是在这个背景下,对设计模式在扫一扫中新的应用进行了总结。
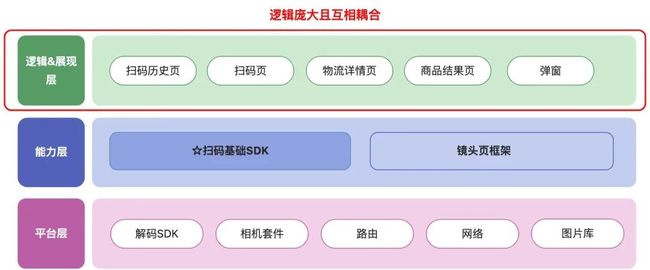
扫一扫原架构
扫一扫的原架构如图所示。其中逻辑&展现层的功能逻辑很多,并没有良好的设计和拆分,举几个例子:
所有码的处理逻辑都写在同一个方法体里,一个方法就接近 2000 多行。
庞大的码处理逻辑写在 viewController 中,与 UI 逻辑耦合。
按照现有的代码设计,若要对某种码逻辑进行修改,都必须将所有逻辑全量编译。如果继续沿用此代码,扫一扫的可维护性会越来越低。
因此我们需要对代码和架构进行优化,在这里优化遵循的思路是:
了解业务能力
了解原有代码逻辑,不确定的地方通过埋点等方式线上验证
对原有代码功能进行重写/重构
编写单元测试,提供测试用例
测试&上线
扫码能力综述
扫一扫的解码能力决定了扫一扫能够处理的码类型,这里称为一级分类。基于一级分类,扫一扫会根据码的内容和类型,再进行二级分类。之后的逻辑,就是针对不同的二级类型,做相应的处理,如下图为技术链路流程。

设计模式
▐ 责任链模式

上述技术链路流程中,码处理流程对应的就是原有的 viewController 里面的巨无霸逻辑。通过梳理我们看到,码处理其实是一条链式的处理,且有前后依赖关系。优化方案有两个,方案一是拆解成多个方法顺序调用;方案二是参考苹果的 NSOperation 独立计算单元的思路,拆解成多个码处理单元。方案一本质还是没解决开闭原则(对扩展开放,对修改封闭)问的题。方案二是一个比较好的实践方式。那么怎么设计一个简单的结构来实现此逻辑呢?
码处理链路的特点是,链式处理,可控制处理的顺序,每个码处理单元都是单一职责,因此这里引出改造第一步:责任链模式。
责任链模式是一种行为设计模式, 它将请求沿着处理者链进行发送。收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。
本文设计的责任链模式,包含三部分:
创建数据的 Creator
管理处理单元的 Manager
处理单元 Pipeline
三者结构如图所示

创建数据的 Creator
包含的功能和特点:
因为数据是基于业务的,所以它只被声明为一个 Protocol ,由上层实现。
Creator 对数据做对象化,对象生成后
self.generateDataBlock(obj, Id)即开始执行
API 代码示例如下
/// 数据产生协议
@protocol TBPipelineDataCreatorDelegate
@property (nonatomic, copy) void(^generateDataBlock)(id data, NSInteger dataId);
@end 上层业务代码示例如下
@implementation TBDataCreator
@synthesize generateDataBlock;
- (void)receiveEventWithScanResult:(TBScanResult *)scanResult
eventDelegate:(id )delegate {
//对数据做对象化
TBCodeData *data = [TBCodeData new];
data.scanResult = scanResult;
data.delegate = delegate;
NSInteger dataId = 100;
//开始执行递归
self.generateDataBlock(data, dataId);
}
@end 管理处理单元的 Manager
包含的功能和特点:
管理创建数据的 Creator
管理处理单元的 Pipeline
采用支持链式的点语法,方便书写
API 代码示例如下
@interface TBPipelineManager : NSObject
/// 添加创建数据 Creator
- (TBPipelineManager *(^)(id dataCreator))addDataCreator;
/// 添加处理单元 Pipeline
- (TBPipelineManager *(^)(id pipeline))addPipeline;
/// 抛出经过一系列 Pipeline 的数据。当 Creator 开始调用 generateDataBlock 后,Pipeline 就开始执行
@property (nonatomic, strong) void(^throwDataBlock)(id data);
@end 实现代码示例如下
@implementation TBPipelineManager
- (TBPipelineManager *(^)(id dataCreator))addDataCreator {
@weakify
return ^(id dataCreator) {
@strongify
if (dataCreator) {
[self.dataGenArr addObject:dataCreator];
}
return self;
};
}
- (TBPipelineManager *(^)(id pipeline))addPipeline {
@weakify
return ^(id pipeline) {
@strongify
if (pipeline) {
[self.pipelineArr addObject:pipeline];
//每一次add的同时,我们做链式标记(通过runtime给每个处理加Next)
if (self.pCurPipeline) {
NSObject *cur = (NSObject *)self.pCurPipeline;
cur.tb_nextPipeline = pipeline;
}
self.pCurPipeline = pipeline;
}
return self;
};
}
- (void)setThrowDataBlock:(void (^)(id _Nonnull))throwDataBlock {
_throwDataBlock = throwDataBlock;
@weakify
//Creator的数组,依次对 Block 回调进行赋值,当业务方调用此 Block 时,就是开始处理数据的时候
[self.dataGenArr enumerateObjectsUsingBlock:^(id _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
obj.generateDataBlock = ^(id data, NSInteger dataId) {
@strongify
data.dataId = dataId;
//开始递归处理数据
[self handleData:data];
};
}];
}
- (void)handleData:(id)data {
[self recurPipeline:self.pipelineArr.firstObject data:data];
}
- (void)recurPipeline:(id)pipeline data:(id)data {
if (!pipeline) {
return;
}
//递归让pipeline处理数据
@weakify
[pipeline receiveData:data throwDataBlock:^(id _Nonnull throwData) {
@strongify
NSObject *cur = (NSObject *)pipeline;
if (cur.tb_nextPipeline) {
[self recurPipeline:cur.tb_nextPipeline data:throwData];
} else {
!self.throwDataBlock?:self.throwDataBlock(throwData);
}
}];
}
@end 处理单元 Pipeline
包含的功能和特点:
因为数据是基于业务的,所以它只被声明为一个 Protocol ,由上层实现。
API 代码示例如下
@protocol TBPipelineDelegate
//如果有错误,直接抛出
- (void)receiveData:(id)data throwDataBlock:(void(^)(id data))block;
@end 上层业务代码示例如下
//以A类型码码处理单元为例
@implementation TBGen3Pipeline
- (void)receiveData:(id )data throwDataBlock:(void (^)(id data))block {
TBScanResult *result = data.scanResult;
NSString *scanType = result.resultType;
NSString *scanData = result.data;
if ([scanType isEqualToString:TBScanResultTypeA]) {
//跳转逻辑
...
//可以处理,终止递归
BlockInPipeline();
} else {
//不满足处理条件,继续递归:由下一个 Pipeline 继续处理
PassNextPipeline(data);
}
}
@end 业务层调用
有了上述的框架和上层实现,生成一个码处理管理就很容易且能达到解耦的目的,代码示例如下
- (void)setupPipeline {
//创建 manager 和 creator
self.manager = TBPipelineManager.new;
self.dataCreator = TBDataCreator.new;
//创建 pipeline
TBCodeTypeAPipelie *codeTypeAPipeline = TBCodeTypeAPipelie.new;
TBCodeTypeBPipelie *codeTypeBPipeline = TBCodeTypeBPipelie.new;
//...
TBCodeTypeFPipelie *codeTypeFPipeline = TBCodeTypeFPipelie.new;
//往 manager 中链式添加 creator 和 pipeline
@weakify
self.manager
.addDataCreator(self.dataCreator)
.addPipeline(codeTypeAPipeline)
.addPipeline(codeTypeBPipeline)
.addPipeline(codeTypeFPipeline)
.throwDataBlock = ^(id data) {
@strongify
if ([self.proxyImpl respondsToSelector:@selector(scanResultDidFailedProcess:)]) {
[self.proxyImpl scanResultDidFailedProcess:data];
}
};
}状态模式


回头来看下码展示的逻辑,这是我们用户体验优化的重要一项内容。码展示的意思是对于当前帧/图片,识别到的码位置,我们进行锚点的高亮并跳转。这里包含三种情况:
未识别到码的时候,无锚点展示
识别到单码的时候,展示锚点并在指定时间后跳转
识别到多码额时候,展示锚点并等待用户点击
可以看到,这里涉及到简单的展示状态切换,这里就引出改造的第二步:状态模式

状态模式是一种行为设计模式, 能在一个对象的内部状态变化时改变其行为, 使其看上去就像改变了自身所属的类一样。
本文设计的状态模式,包含两部分:
状态的信息 StateInfo
状态的基类 BaseState
两者结构如图所示

▐ 状态的信息 StateInfo
包含的功能和特点:
当前上下文仅有一种状态信息流转
业务方可以保存多个状态键值对,状态根据需要执行相应的代码逻辑。
状态信息的声明和实现代码示例如下
@interface TBBaseStateInfo : NSObject {
@private
TBBaseState *_currentState; //记录当前的 State
}
//使用当前的 State 执行
- (void)performAction;
//更新当前的 State
- (void)setState:(TBBaseState *)state;
//获取当前的 State
- (TBBaseState *)getState;
@end
@implementation TBBaseStateInfo
- (void)performAction {
//当前状态开始执行
[_currentState perfromAction:self];
}
- (void)setState:(TBBaseState *)state {
_currentState = state;
}
- (TBBaseState *)getState {
return _currentState;
}
@end 上层业务代码示例如下
typedef NS_ENUM(NSInteger, TBStateType) {
TBStateTypeNormal, //空状态
TBStateTypeSingleCode, //单码展示态
TBStateTypeMultiCode, //多码展示态
};
@interface TBStateInfo : TBBaseStateInfo
//以 key-value 的方式存储业务 type 和对应的状态 state
- (void)setState:(TBBaseState *)state forType:(TBStateType)type;
//更新 type,并执行 state
- (void)setType:(TBStateType)type;
@end
@implementation TBStateInfo
- (void)setState:(TBBaseState *)state forType:(TBStateType)type {
[self.stateDict tb_setObject:state forKey:@(type)];
}
- (void)setType:(TBStateType)type {
id oldState = [self getState];
//找到当前能响应的状态
id newState = [self.stateDict objectForKey:@(type)];
//如果状态未发生变更则忽略
if (oldState == newState)
return;
if ([newState respondsToSelector:@selector(perfromAction:)]) {
[self setState:newState];
//转态基于当前的状态信息开始执行
[newState perfromAction:self];
}
}
@end ▐ 状态的基类 BaseState
包含的功能和特点:
定义了状态的基类
声明了状态的基类需要遵循的 Protocol
Protocol 如下,基类为空实现,子类继承后,实现对 StateInfo 的处理。
@protocol TBBaseStateDelegate
- (void)perfromAction:(TBBaseStateInfo *)stateInfo;
@end 上层(以单码 State 为例)代码示例如下
@interface TBSingleCodeState : TBBaseState
@end
@implementation TBSingleCodeState
//实现 Protocol
- (void)perfromAction:(TBStateInfo *)stateAction {
//业务逻辑处理 Start
...
//业务逻辑处理 End
}
@end▐ 业务层调用
以下代码生成一系列状态,在合适时候进行状态的切换。
//状态初始化
- (void)setupState {
TBSingleCodeState *singleCodeState = TBSingleCodeState.new; //单码状态
TBNormalState *normalState = TBNormalState.new; //正常状态
TBMultiCodeState *multiCodeState = [self getMultiCodeState]; //多码状态
[self.stateInfo setState:normalState forType:TBStateTypeNormal];
[self.stateInfo setState:singleCodeState forType:TBStateTypeSingleCode];
[self.stateInfo setState:multiCodeState forType:TBStateTypeMultiCode];
}
//切换常规状态
- (void)processorA {
//...
[self.stateInfo setType:TBStateTypeNormal];
//...
}
//切换多码状态
- (void)processorB {
//...
[self.stateInfo setType:TBStateTypeMultiCode];
//...
}
//切换单码状态
- (void)processorC {
//...
[self.stateInfo setType:TBStateTypeSingleCode];
//...
}最好根据状态机图编写状态切换代码,以保证每种状态都有对应的流转。
次态→ |
状态A |
状态B |
状态C |
状态A |
条件A |
... |
... |
状态B |
... |
... |
... |
状态C |
... |
... |
... |
代理模式

在开发过程中,我们会在越来越多的地方使用到上图能力,比如「淘宝拍照」的相册中、「扫一扫」的相册中,用到解码、码展示、码处理的能力。
因此,我们需要把这些能力封装并做成插件化,以便在任何地方都能够使用。这里就引出了我们改造的第三步:代理模式。
代理模式是一种结构型设计模式,能够提供对象的替代品或其占位符。代理控制着对于原对象的访问, 并允许在将请求提交给对象前后进行一些处理。
本文设计的状态模式,包含两部分:
代理单例 GlobalProxy
代理的管理 ProxyHandler
两者结构如图所示

▐ 代理单例 GlobalProxy
单例的目的主要是减少代理重复初始化,可以在合适的时机初始化以及清空保存的内容。单例模式对于 iOSer 再熟悉不过了,这里不再赘述。
▐ 代理的管理 Handler
维护一个对象,提供了对代理增删改查的能力,实现对代理的操作。
这里实现 Key - Value 的 Key 为 Protocol ,Value 为具体的代理。
代码示例如下
+ (void)registerProxy:(id)proxy withProtocol:(Protocol *)protocol {
if (![proxy conformsToProtocol:protocol]) {
NSLog(@"#TBGlobalProxy, error");
return;
}
if (proxy) {
[[TBGlobalProxy sharedInstance].proxyDict setObject:proxy forKey:NSStringFromProtocol(protocol)];
}
}
+ (id)proxyForProtocol:(Protocol *)protocol {
if (!protocol) {
return nil;
}
id proxy = [[TBGlobalProxy sharedInstance].proxyDict objectForKey:NSStringFromProtocol(protocol)];
return proxy;
}
+ (NSDictionary *)proxyConfigs {
return [TBGlobalProxy sharedInstance].proxyDict;
}
+ (void)removeAll {
[TBGlobalProxy sharedInstance].proxyDict = [[NSMutableDictionary alloc] init];
}▐ 业务层的调用
所以不管是什么业务方,只要是需要用到对应能力的地方,只需要从单例中读取 Proxy, 实现该 Proxy 对应的 Protocol, 如一些回调、获取当前上下文等内容,就能够获取该 Proxy 的能力。
//读取 Proxy 的示例
- (id )scanProxy {
if (!_scanProxy) {
_scanProxy = [TBGlobalProxy proxyForProtocol:@protocol(TBScanProtocol)];
}
_scanProxy.proxyImpl = self;
return _scanProxy;
}
//写入 Proxy 的示例(解耦调用)
- (void)registerGlobalProxy {
//码处理能力
[TBGlobalProxy registerProxy:[[NSClassFromString(@"TBScanProxy") alloc] init]
withProtocol:@protocol(TBScanProtocol)];
//解码能力
[TBGlobalProxy registerProxy:[[NSClassFromString(@"TBDecodeProxy") alloc] init]
withProtocol:@protocol(TBDecodeProtocol)];
} 扫一扫新架构
基于上述的改造优化,我们将原扫一扫架构进行了优化:将逻辑&展现层进行代码分拆,分为展现层、逻辑层,接口层。以达到层次分明、职责清晰、解耦的目的。

总结
上述沉淀的三个设计模式作为扫拍业务的 Foundation 的 Public 能力,应用在镜头页的业务逻辑中。
通过此次重构,提高了扫码能力的复用性,结构和逻辑的清晰带来的是维护成本的降低,不用再大海捞针从代码“巨无霸”中寻找问题,降低了开发人日。
团队介绍
我们是大淘宝技术搜索推荐移动端团队,负责集团核心电商搜索推荐,图像视频搜索业务研发、技术平台建设、新业务和前沿技术探索等工作,我们负责的业务拥有亿级流量,能为您提供巨大的机遇和成长空间,期待您的加入。
感兴趣的同学可将简历发送到 [email protected]
✿ 拓展阅读


作者|曾超然(朝然)
编辑|橙子君