利用neon技术对矩阵旋转进行加速
一般的矩阵旋转操作都是对矩阵中的元素逐个操作,假设矩阵大小为m*n,那么时间复杂度就是o(mn)。如果使用了arm公司提供的neon加速技术,则可以并行的读取多个元素,对多个元素进行操作,虽然时间复杂度还是o(mn),但是常数因子会变小,并且在寄存器里的操作比在普通内存中还要快一些,所以会带来一定的性能提升。
在实际应用中,我需要对一个矩阵进行顺时针旋转90度,网上这方面的资料很少,于是自己研究了一下,利用neon给出的一些加速指令,设计了一个简单的neon矩阵旋转算法。
1.目标:将输入矩阵顺时针旋转90度,如下图所示:
输入矩阵 输出矩阵


2.一般做法:
一般的做法是,将输入矩阵中的每个元素,根据旋转的角度,计算出其在旋转后矩阵中的位置,并填充该值。
3.利用NEON的做法:
考虑将一个矩阵划分成若干子矩阵,例如:一个128×256大小的矩阵可以划分为16×32个8×8大小的矩阵。分别对每个8x8的子矩阵进行旋转,再将其复制到输出矩阵中正确的坐标上即可。可以总结为2步:
循环执行以下步骤,直到所有子矩阵均被处理过
1.旋转当前子矩阵
2.将旋转后的子矩阵复制到输出矩阵中
其中最关键的就是第一步,详细讲一下利用neon技术如何做到:
以byte数组为例(因为android中获取的yuv数据就是byte型,将一个矩形按行连成了一个大一维数组),假设图像的长宽都可以被8整除。首先利用2个uint8x8x4_t型数组,将8×8大小的子矩阵读入
mat1.val[0]=vld1_u8(srcImg+i*width+j); mat1.val[1]=vld1_u8(srcImg+(i+1)*width+j); mat1.val[2]=vld1_u8(srcImg+(i+2)*width+j); mat1.val[3]=vld1_u8(srcImg+(i+3)*width+j); mat2.val[0]=vld1_u8(srcImg+(i+4)*width+j); mat2.val[1]=vld1_u8(srcImg+(i+5)*width+j); mat2.val[2]=vld1_u8(srcImg+(i+6)*width+j); mat2.val[3]=vld1_u8(srcImg+(i+7)*width+j);
接着,对两两相邻的寄存器做基于uint8_t类型的专置操作,即:mat1和mat2中的0和1,2和3寄存器分别做转置,得到4个uint8x8x2_t类型数组
vtrn操作示意图如下:
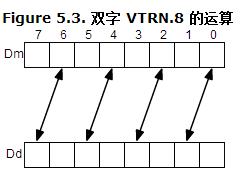
temp1=vtrn_u8(mat1.val[1],mat1.val[0]); temp2=vtrn_u8(mat1.val[3],mat1.val[2]); temp3=vtrn_u8(mat2.val[1],mat2.val[0]); temp4=vtrn_u8(mat2.val[3],mat2.val[2]);
注意,vtrn_8里面两个寄存器的顺序不能颠倒
然后,对这四个数组的类型进行转换,将uint8x8_t转换成uint16x4_t
temp5.val[0]= vreinterpret_u16_u8(temp1.val[0]); temp5.val[1]= vreinterpret_u16_u8(temp1.val[1]); temp6.val[0]= vreinterpret_u16_u8(temp2.val[0]); temp6.val[1]= vreinterpret_u16_u8(temp2.val[1]); temp7.val[0]= vreinterpret_u16_u8(temp3.val[0]); temp7.val[1]= vreinterpret_u16_u8(temp3.val[1]); temp8.val[0]= vreinterpret_u16_u8(temp4.val[0]); temp8.val[1]= vreinterpret_u16_u8(temp4.val[1]);
接下来的做法和上面的这一套很像,继续对这些uint16x4_t数据进行转置,这次的顺序和上次有所不同,相邻的奇偶序号寄存器之间进行专置即:0和2,1和3,4和6,5和7
temp9=vtrn_u16(temp6.val[0],temp5.val[0]); temp10=vtrn_u16(temp6.val[1],temp5.val[1]); temp11=vtrn_u16(temp8.val[0],temp7.val[0]); temp12=vtrn_u16(temp8.val[1],temp7.val[1]);
然后,继续对这四个数组的类型进行转换,将uint16x4_t转换成uint32x2_t
temp13.val[0]= vreinterpret_u32_u16(temp9.val[0]); temp13.val[1]= vreinterpret_u32_u16(temp9.val[1]); temp14.val[0]= vreinterpret_u32_u16(temp10.val[0]); temp14.val[1]= vreinterpret_u32_u16(temp10.val[1]); temp15.val[0]= vreinterpret_u32_u16(temp11.val[0]); temp15.val[1]= vreinterpret_u32_u16(temp11.val[1]); temp16.val[0]= vreinterpret_u32_u16(temp12.val[0]); temp16.val[1]= vreinterpret_u32_u16(temp12.val[1]);
最后,再做一次基于uint32x2_t的转置
temp17=vtrn_u32(temp15.val[0],temp13.val[0]); temp18=vtrn_u32(temp15.val[1],temp13.val[1]); temp19=vtrn_u32(temp16.val[0],temp14.val[0]); temp20=vtrn_u32(temp16.val[1],temp14.val[1]);
最后的最后,还需要对各个寄存器中存储的值重新排列一遍,并转换回最初的uint8x8_t
temp1.val[0]= vreinterpret_u8_u32(temp17.val[0]); temp1.val[1]= vreinterpret_u8_u32(temp19.val[0]); temp2.val[0]= vreinterpret_u8_u32(temp18.val[0]); temp2.val[1]= vreinterpret_u8_u32(temp20.val[0]); temp3.val[0]= vreinterpret_u8_u32(temp17.val[1]); temp3.val[1]= vreinterpret_u8_u32(temp19.val[1]); temp4.val[0]= vreinterpret_u8_u32(temp18.val[1]); temp4.val[1]= vreinterpret_u8_u32(temp20.val[1]);
大功告成!此时的子矩阵已经被顺时针旋转了90度,接下来,只要将其复制到输出矩阵的正确位置即可。
几点说明
1.为什么这么做可以旋转矩阵:
NEON提供的专置函数相当于对2×2的小矩阵进行专置,因此利用这个特性,可以对更大的矩阵进行旋转。其实自己按照我说的步骤,画个矩阵,自己做一下,就明白了。也不一定用8×8的,4×4的就能说明问题,当然4×4比8×8的要简单。
2.怎样得到正确位置:
这个还是自己思考一下吧,不难,假设某元素在输入矩阵的位置是(i,j),那么在输出的旋转90度的矩阵中的位置和i,j是相关的。