pandas追加写入excel_Python利用pandas读取excel数据批量写入mysql
最近在编写业务系统时,要增加每种类型上百台设备,在前端web页面进行设备的增加很浪费时间,也不是很现实,只能先将设备信息在EXCEL里编辑好实现批量上传到mysql数据库中;笔者脑海中及时就想到了用pandas里的read_excel,用xlrd/openpyxl实现起来相对麻烦一些,为快速完成任务,用read_excel节省了很大一部分时间。
首先要安装相关的库都比较简单,直接pip install 安装就行:
Pip install numpy pandas pymysql tornado
Tornado 和现在的主流 Web 服务器框架(包括大多数Python的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快。得利于其非阻塞的方式和对epoll的运用,Tornado每秒可以处理数以千计的连接,因此 Tornado 是实时 Web 服务的一个理想框架。
英文原文:
Tornado is a Python web framework and asynchronous networking library, originally developed at FriendFeed. By using non-blocking network I/O, Tornado can scale to tens of thousands of open connections, making it ideal for long polling, WebSockets, and other applications that require a long-lived connection to each user.
话不多说,直接开始:
1.在数据库中创建一张表用来存储数据:CREATE TABLE `test`.`t_area` ( `AreaID` VARCHAR(6) NULL COMMENT '区域id', `AreaCode` VARCHAR(6) NULL DEFAULT '' COMMENT '区域编号', `City` VARCHAR(45) NULL DEFAULT '', `PostCode` VARCHAR(10) NULL DEFAULT '', `Province` VARCHAR(45) NULL DEFAULT '')ENGINE=InnoDB DEFAULT CHARSET=utf8;2.编写一个函数用于插入数据库(生产环境中是单独封装一个操作数据库的基础类库对数据库进行操作):
def insert_many_to_mysql(sql, args): '''批量插入数据到mysql,一个format数据sql,一个数据参数''' # 连接配置信息 config = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'password': '********',#你的数据库密码 'db': 'test', 'charset': 'utf8mb4', 'cursorclass': pymysql.cursors.DictCursor,# 按字典方式返回数据 } try: conn = pymysql.connect(**config) # 连接到数据库 except pymysql.err.OperationalError as o: print(o) try: with conn.cursor() as cursor: # 打开数据库 result_row = cursor.executemany(sql, args) # 执行sql语句 conn.commit() # 提交 return result_row except Exception as e: conn.rollback() # 有异常回滚 print(e) return None finally: conn.close()3.时间戳字符串,用于重命名Excel文档
def generat_file_path(old_filename): """ 将原文件名称转换成新文件名,附带用户名,好查找 :param old_filename: 旧文件名称 :return:处理理后的新文件名称 """ date_str = time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime(time.time())) file_extension = old_filename.split('.') new_filename = date_str + '.' + file_extension[len(file_extension)-1]return new_filenamedef write_file_to_dir(file_dir, file_metas): """ 将文件写入路径下保存 :param file_dir:文件保存的路径 :param file_metas:二进制文件流 :return:返回文件路径下的文件路径和文件名 """ import os if not os.path.exists(file_dir): os.makedirs(file_dir) upload_path = os.path.join(os.path.dirname(file_dir), '') # 文件的暂存路径 # print(file_dir) # print(upload_path) for meta in file_metas: file_name = meta['filename'] new_filename = generat_file_path( file_name) # read_path = upload_path + new_filename file_path = os.path.join(upload_path, new_filename) with open(file_path, 'wb') as up: up.write(meta['body']) return upload_path, new_filenameclass DataBatchImportHandler(tornado.web.RequestHandler): """批量上传的api""" # 重写父类方法并调用父类方法解决跨域问题 def write(self, chunk): self.set_header("Access-Control-Allow-Origin", "*") self.set_header("Access-Control-Allow-Headers", "x-requested-with, content-type, x-file-name") self.set_header('Access-Control-Allow-Methods', 'POST,GET,OPTIONS,PUT') self.set_header('Content-Type', 'application/json') super(DataBatchImportHandler, self).write(chunk) # 重写父类方法 def options(self, *args, **kwargs): self.set_header('Access-Control-Allow-Origin', "*") self.set_header('Access-Control-Allow-Headers', "x-requested-with, content-type, x-file-name") self.set_header('Access-Control-Allow-Methods', "POST,GET,OPTIONS,PUT,DELETE") self.set_header('Access-Control-Max-Age', 10) def post(self): # 提取表单中'name'为'file'的文件元数据,就是excel表格 file_metas = self.request.files.get('file') if not file_metas: dic = {"retCode": 100, "retMsg": "上传文件不能为空"} self.write(json.dumps(dic, ensure_ascii=False)) return file_dir = r'e:\\' # 文件写入服务器文件用于Pandas读取 upload_path, new_filename = write_file_to_dir(file_dir, file_metas) read_path = upload_path + new_filename '''读取excel''' try: # 读取文件不要第一行标题 data_list = pd.read_excel(read_path, header=0) print(data_list) except Exception as e: print(e) # 返回前端读取失败 dic = {"retCode": 101, "retMsg": "excel文件读取失败"} self.write(json.dumps(dic, ensure_ascii=False)) return # 首先使用np.array()函数把DataFrame转化为np.ndarray(),再利用tolist()函数把np.ndarray()转为list try: train_data = np.array(data_list) train_data_list = train_data.tolist() print(train_data_list) except Exception as e: self.log_error(e) dic = {"retCode": 102, "retMsg": "excel文件内容有误请重新编辑"} self.write(json.dumps(dic, ensure_ascii=False)) return # 开始写数据库,excel表的顺序必须和sql语句插入顺序一样,不然处理起来很麻烦 insert_sql = 'insert into t_area(AreaCode,AreaID,City,PostCode,Province) values(%s,%s,%s,%s,%s)' result = insert_many_to_mysql(insert_sql, train_data_list) if result: dic = {"retCode": 0, "retMsg": "导入数据库成功"} self.write(json.dumps(dic, ensure_ascii=False)) else: dic = {"retCode": 103, "retMsg": "导入数据库失败"} self.write(json.dumps(dic, ensure_ascii=False))# 静态资源cookie等配置settings = { 'template_path': 'views', 'static_path': 'static', 'static_url_prefix': '/static/', 'cookie_secret': 'a92bfb48-9cd9-11e7-880e-fa163eb9e314', 'login_url': '/'}# 定义一个应用程序app = tornado.web.Application([ (r'/batch/import', DataBatchImportHandler), ],**settings)if __name__ == "__main__": app.listen(1111) # 启动端口 tornado.ioloop.IOLoop.instance().start() #启动webserver下面是操作的一些截图

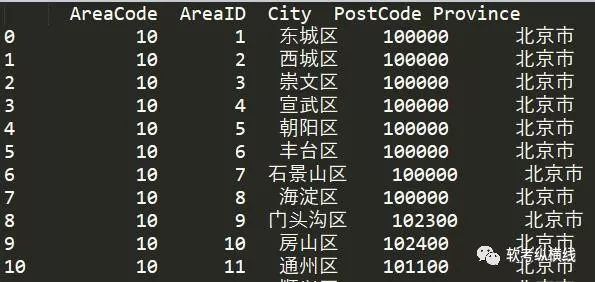
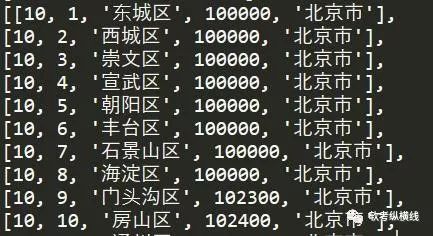
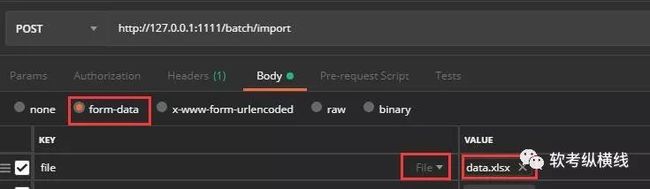


结束语通过以上8步实现了数据的上传并保存到MYSQL数据库中,在生产环境中第五步还包括数据清洗,数据抽取等处理工作,在postman中测试成功,希望借止达到抛砖引玉的专用。 回复exceltomysql获取源码及数据
