SQL牛客网刷题(三)——5、6、21、22、23题解析
【SQL5. 查找所有员工的last_name和first_name以及对应部门编号dept_no】
题目描述:
查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括暂时没有分配具体部门的员工(请注意输出描述里各个列的前后顺序)
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
代码:
select last_name, first_name, dept_no
from employees as e left join dept_emp as d
on e.emp_no=d.emp_no
order by e.emp_no;思路:
这道题难度为“中等”,思路和昨天SQL19的思路一样,只不过两表关联更简单,用left join语句直接得到答案,详情请看以下链接SQL19题:
【SQL6. 查找所有员工入职时候的薪水情况】
问题描述:
查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序(请注意,一个员工可能有多次涨薪的情况)
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
代码:
select e.emp_no, salary
from employees as e left join salaries as s
on e.emp_no = s.emp_no
group by e.emp_no
having hire_date = from_date
order by e.emp_no desc;思路:
这道题难度也是“中等”,但是私认为应该算中等难度中较难的了,思路就是一个left join的两表关联再加一个筛选,最后根据题目要求对emp_no字段倒序排序,使用desc就可以实现。这里解释一下where语句和having语句,两者后面都是筛选条件,不同的是where语句实在分组(group by)前进行筛选,而having是在分组之后筛选,对于这道题而言,where和having都能得到一样的结果,如果使用where的话,代码如下:
select e.emp_no, salary
from employees as e left join salaries as s
on e.emp_no = s.emp_no
where hire_date = from_date
order by e.emp_no desc;【SQL21. 查找所有员工自入职以来的薪水涨幅情况】
问题描述:
查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序
(注:可能有employees表和salaries表里存在记录的员工,有对应的员工编号和涨薪记录,但是已经离职了,离职的员工salaries表的最新的to_date!='9999-01-01',这样的数据不显示在查找结果里面)
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL, -- '入职时间'
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL, -- '一条薪水记录开始时间'
`to_date` date NOT NULL, -- '一条薪水记录结束时间'
PRIMARY KEY (`emp_no`,`from_date`));
代码:
select e.emp_no, (a.salary - b.salary) as growth
from employees as e join salaries as a
on e.emp_no = a.emp_no and a.to_date = '9999-01-01'
join salaries as b
on e.emp_no=b.emp_no and hire_date= b.from_date
order by a.salary - b.salary;这道题难度为“较难”,一开始我审题错误,看成了离职员工salaries表的最新的to_date='9999-01-01',代码整的挺复杂,还一直报错。
重新审题之后这道题反而简单了不少,所有员工最新一条薪资记录的to_date都是'9999-01-01',所以最新的薪资就是该日期对应的薪资,而起始薪资就是from_date与hire_date相等的记录,因此将employees表与salaries表关联两次,分别查询出最后的薪资和最初薪资,做差求出growth,最后别忘了排序。
【SQL22. 统计各个部门的工资记录数】
题目描述:
统计各个部门的工资记录数,给出部门编码dept_no、部门名称dept_name以及部门在salaries表里面有多少条记录sum
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
代码:
select de.dept_no, dept_name, count(salary) as sum
from dept_emp as de join departments as d
on de.dept_no = d.dept_no
join salaries s
on de.emp_no = s.emp_no
group by de.dept_no;思路:
这道题也是“较难”难度,但是题目本身并不算难,只是三个表的连接。
【SQL23. 对所有员工的当前薪水按照salary进行按照1-N的排名】
题目描述:
对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
这道题也是“较难”难度,说实话这道题有点恶心到我了,按照我的常规理解,所谓涉及并列排名的结果应该是这样的:
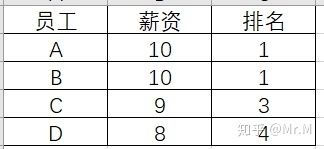
但是这道题的结果是这样的:
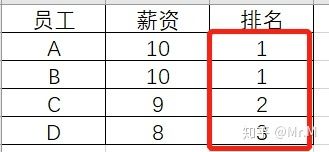
其实体现在代码上就是一个distinct的差,我分别按照我的理解(我觉得我的理解是对的,虽然我实际得按照题目要求去做)和题目要求的情况去讲一下。
1、我的理解:
首先先放代码:
select s1.emp_no , s1.salary , (count(s2.salary)+1) as rank
from salaries as s1, salaries as s2
where s1.salary这个思路有点像python里的for循环遍历,思路就是把emp_no员工的薪资去和包括自己的所有人的薪资作比较,我们以以下的数据举例:
比员工A薪资高的人有0个,这个0就是用count(s2.salary)这个函数计算出来的,所以员工A的rank就是0+1=1,员工B和员工A薪资一样,所以同理,得到rank为2,比员工C高的是员工AB,也就是2人,所以员工C的rank就是2+1也就是3,同理推出员工D为4。
2、按题目要求:
首先放代码:
select s1.emp_no , s1.salary , count(distinct s2.salary) as rank
from salaries as s1, salaries as s2
where s1.salary<=s2.salary and s1.to_date='9999-01-01' and s2.to_date='9999-01-01'
group by s1.emp_no
order by rank;我们使用以下数据举例子:

大体的思路和上面类似,也是按员工编号去把每个人薪资去和包括自己的所有人的薪资作比较。薪资大于等于员工A薪资的有员工AB两人,两人都是10元,但是显然是想让两人并列第一,所以我们用count(distinct s2.salary)去重,10出现了两次,去重后得到1,所以AB的rank都是1,接下来看CD,大于等于CD薪资的共有四人ABCD,对应薪资分别是10,10,9,9,10和9各重复一次,去重计数,得到CDrank都是2。E的话同理,就不赘述了。
以上,欢迎指正。