语义分割--DeepLab系列V3+(待完善)
写在前面
本文主要讨论 deeplab系列中的deeplabv3+, 后续将贴上模型在pytorch架构下的结果。
关于deeplabv2的相关知识参考我的另一篇博客:
https://blog.csdn.net/l_z_z_z/article/details/119600501
Deeplab v3+
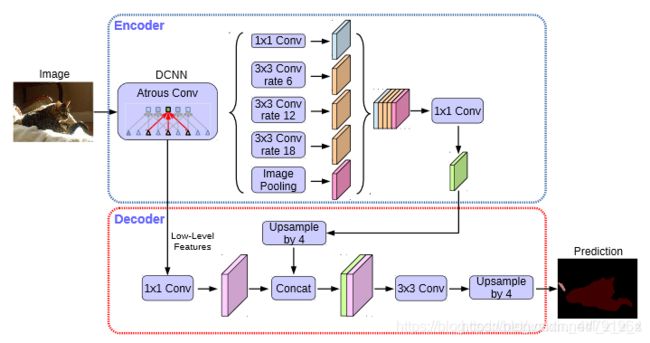
deeplabv3+ 主要在模型的架构上作文章,引入了可任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。
其在Encoder部分引入了大量的空洞卷积,所谓空洞,就是特征点提取的时候会跨像素,在不损失信息的情况下,加大了感受野,让每一个卷积输出都包含较大范围的信息。(空洞卷积示意图见下方图2)

实现思路
一、预测部分
1、主干网络介绍
在论文中,Deeplabv3+采用的是Xception系列作为主干特征提取网络。对应图片中的DCNN,通过这个DCNN,输入进来的图片,会变成2个有效特征层,这两个有效特征层,一个进行并行的空洞卷积,一个传入DECODER。
但是,本博客采用的是mobilenet v2网络(由于算力的限制)。
MobileNet模型是google针对手机等嵌入式设备提出的一种轻量级的深层神经网络。而MobileNetV2是其升级版,其中一个重要特点是其使用了 Inverted resblock,整个mobilenet v2都有 Inverted resblock组成。
关于Inverted resblock(如图)介绍如下:

其分成两个部分:左边是主干部分,首先使用1x1卷积进行升维,然后利用3x3深度可分离卷积进行特征提取,然后再利用1x1卷积降维; 右边是残差部分,输入和输出直接相接。
再经过MobileNetV2的特征提取后,可以获得两个有效特征层。一个有效特征层是输入图片的 高和宽 压缩两次的结果; 一个有效特征层是 输入图片 高和宽压缩四次的结果。
(下面贴出在Keras框架下的代码)
from keras import layers
from keras.activations import relu
from keras.layers import (Activation, Add, BatchNormalization, Concatenate,
Conv2D, DepthwiseConv2D, Dropout,
GlobalAveragePooling2D, Input, Lambda, ZeroPadding2D)
from keras.models import Model
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
def relu6(x):
return relu(x, max_value=6)
def _inverted_res_block(inputs, expansion, stride, alpha, filters, block_id, skip_connection, rate=1):
in_channels = inputs.shape[-1].value # inputs._keras_shape[-1]
pointwise_conv_filters = int(filters * alpha)
pointwise_filters = _make_divisible(pointwise_conv_filters, 8)
x = inputs
prefix = 'expanded_conv_{}_'.format(block_id)
if block_id:
# Expand
x = Conv2D(expansion * in_channels, kernel_size=1, padding='same',
use_bias=False, activation=None,
name=prefix + 'expand')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999,
name=prefix + 'expand_BN')(x)
x = Activation(relu6, name=prefix + 'expand_relu')(x)
else:
prefix = 'expanded_conv_'
# Depthwise
x = DepthwiseConv2D(kernel_size=3, strides=stride, activation=None,
use_bias=False, padding='same', dilation_rate=(rate, rate),
name=prefix + 'depthwise')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999,
name=prefix + 'depthwise_BN')(x)
x = Activation(relu6, name=prefix + 'depthwise_relu')(x)
# Project
x = Conv2D(pointwise_filters,
kernel_size=1, padding='same', use_bias=False, activation=None,
name=prefix + 'project')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999,
name=prefix + 'project_BN')(x)
if skip_connection:
return Add(name=prefix + 'add')([inputs, x])
# if in_channels == pointwise_filters and stride == 1:
# return Add(name='res_connect_' + str(block_id))([inputs, x])
return x
def mobilenetV2(inputs, alpha=1, downsample_factor=8):
if downsample_factor == 8:
block4_dilation = 2
block5_dilation = 4
block4_stride = 1
atrous_rates = (12, 24, 36)
elif downsample_factor == 16:
block4_dilation = 1
block5_dilation = 2
block4_stride = 2
atrous_rates = (6, 12, 18)
else:
raise ValueError('Unsupported factor - `{}`, Use 8 or 16.'.format(downsample_factor))
first_block_filters = _make_divisible(32 * alpha, 8)
# 512,512,3 -> 256,256,32
x = Conv2D(first_block_filters,
kernel_size=3,
strides=(2, 2), padding='same',
use_bias=False, name='Conv')(inputs)
x = BatchNormalization(
epsilon=1e-3, momentum=0.999, name='Conv_BN')(x)
x = Activation(relu6, name='Conv_Relu6')(x)
x = _inverted_res_block(x, filters=16, alpha=alpha, stride=1,
expansion=1, block_id=0, skip_connection=False)
#---------------------------------------------------------------#
# 256,256,16 -> 128,128,24
x = _inverted_res_block(x, filters=24, alpha=alpha, stride=2,
expansion=6, block_id=1, skip_connection=False)
x = _inverted_res_block(x, filters=24, alpha=alpha, stride=1,
expansion=6, block_id=2, skip_connection=True)
skip1 = x
#---------------------------------------------------------------#
# 128,128,24 -> 64,64.32
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=2,
expansion=6, block_id=3, skip_connection=False)
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=1,
expansion=6, block_id=4, skip_connection=True)
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=1,
expansion=6, block_id=5, skip_connection=True)
#---------------------------------------------------------------#
# 64,64,32 -> 32,32.64
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=block4_stride,
expansion=6, block_id=6, skip_connection=False)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=7, skip_connection=True)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=8, skip_connection=True)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=9, skip_connection=True)
# 32,32.64 -> 32,32.96
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=10, skip_connection=False)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=11, skip_connection=True)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=12, skip_connection=True)
#---------------------------------------------------------------#
# 32,32.96 -> 32,32,160 -> 32,32,320
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block4_dilation, # 1!
expansion=6, block_id=13, skip_connection=False)
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=14, skip_connection=True)
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=15, skip_connection=True)
x = _inverted_res_block(x, filters=320, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=16, skip_connection=False)
return x,atrous_rates,skip1
2、加强特征提取结构
在Deeplabv3+,加强特征提取网络可以分成两个部分: 在Encoder中,会对压缩四次的初步有效特征层 利用 并行的 Atrous Convolution, 分别用不同的rate的 Atrous Convolution进行特征提取,再提取合并,在进行1x1卷积 压缩特征。在Decoder中,会对压缩两次的初步特征有效层利用 1x1卷积 调整通道数, 再和空洞卷积后 的 有效特征层上采样(Upsample by 4)的结果进行堆叠,在完成堆叠后,进行两次深度可分离卷积块。
此时,就获得最终的有效特征层,是整张图片的特征浓缩。
3、利用特征获得预测结果
在经过1、2步之后,已经得到输入进来的图片的特征,此时需要利用特征获得最终的预测结果。
这个具体的过程分成2步:
- 利用一个1x1卷积进行通道调整,调整成Num_Classes.
- 利用resize进行上采样使得最终的输出层,宽、高与输入图片一致。
二、训练部分
运行过程
本博客使用的是voc2012数据集,shell命令如下所示:
python train.py --dataset pascal --backbone mobilenet --lr 0.007 --workers 1 --epochs 5 --batch-size 8 --gpu-ids 0 --checkname deeplab-mobilenet运行结果:



