Spark3.1.2 on TDH622
一、在linux搭建spark环境
1.下载spark
spark官方下载地址:http://spark.apache.org/downloads.html 。这里选择spark-3.1.2-bin-hadoop2.7版本。
2.上传spark,下载TDH客户端
- 上传 spark-3.1.2-bin-hadoop2.7.tgz 至linux的/opt目录下
- 在manager下载TDH客户端,上传至/opt目录下
- 解压spark。tar -zxvf spark-3.1.2-bin-hadoop2.7.tgz
- 解压客户端。tar -xvf tdh-client.tar
3.配置spark环境变量
- cd ${spark_home}/conf (注:${spark_home}即/opt/spark-3.1.2-bin-hadoop2.7目录)
- cp spark-env.sh.template spark-env.sh
- vim spark-env.sh
- 在末尾加上如下配置:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
export HADOOP_CONF_DIR=/opt/TDH-Client/conf/hdfs1
export YARN_CONF_DIR=/opt/TDH-Client/conf/yarn1
export HIVE_CONF_DIR=/opt/TDH-Client/conf/inceptor1
4.修改spark默认配置
- cd ${spark_home}/conf
- cp spark-defaults.conf.template spark-defaults.conf
- cp /etc/inceptor1/conf/inceptor.keytab ./
- klist -kt inceptor.keytab ,记录下Principal
- vim spark-defaults.conf
- 在末尾加上如下配置:(注:若集群未开安全,则不需要设置spark.kerberos.keytab和spark.kerberos.principal这两个参数)
spark.yarn.historyServer.address=tdh01:18080
spark.yarn.historyServer.allowTracking=true
spark.kerberos.keytab /opt/spark-3.1.2-bin-hadoop2.7/conf/inceptor.keytab
spark.kerberos.principal hive/tdh01@TDH
spark.executorEnv.JAVA_HOME /usr/java/jdk1.8.0_25
spark.yarn.appMasterEnv.JAVA_HOME /usr/java/jdk1.8.0_25
5.拷贝hive-site.xml文件
cp /opt/TDH-Client/conf/inceptor1/hive-site.xml ${spark_home}/conf/
6.配置log4j.properties
- cd ${spark_home}/conf
- cp log4j.properties.template log4j.properties
7.更换spark中的开源jar包
- 共需更换15个hadoop相关jar包,更换1个zookeeper相关jar包,新增一个guardian相关jar包
- 旧jar包:
hadoop-annotations-2.7.4.jar
hadoop-auth-2.7.4.jar
hadoop-client-2.7.4.jar
hadoop-common-2.7.4.jar
hadoop-hdfs-2.7.4.jar
hadoop-mapreduce-client-app-2.7.4.jar
hadoop-mapreduce-client-common-2.7.4.jar
hadoop-mapreduce-client-core-2.7.4.jar
hadoop-mapreduce-client-jobclient-2.7.4.jar
hadoop-mapreduce-client-shuffle-2.7.4.jar
hadoop-yarn-api-2.7.4.jar
hadoop-yarn-client-2.7.4.jar
hadoop-yarn-common-2.7.4.jar
hadoop-yarn-server-common-2.7.4.jar
hadoop-yarn-server-web-proxy-2.7.4.jar
zookeeper-3.4.14.jar
- 新jar包:
hadoop-annotations-2.7.2-transwarp-6.2.2.jar
hadoop-auth-2.7.2-transwarp-6.2.2.jar
hadoop-client-2.7.2-transwarp-6.2.2.jar
hadoop-common-2.7.2-transwarp-6.2.2.jar
hadoop-hdfs-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-app-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-common-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-core-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-jobclient-2.7.2-transwarp-6.2.2.jar
hadoop-mapreduce-client-shuffle-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-api-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-client-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-common-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-server-common-2.7.2-transwarp-6.2.2.jar
hadoop-yarn-server-web-proxy-2.7.2-transwarp-6.2.2.jar
zookeeper-3.4.5-transwarp-6.2.2.jar
federation-utils-guardian-3.1.3.jar
- jar包位置
/opt/TDH-Client/hyperbase/lib ---- 14个hadoop jar包
/opt/TDH-Client/hadoop/hadoop-yarn ---- 1个hadoop jar包
/opt/TDH-Client/hadoop/hadoop/lib ---- 1个zookeeper jar包
/opt/TDH-Client/inceptor/lib ---- 1个guardian jar包
二、idea开发spark程序
1.新建maven项目
2.加入如下maven依赖
spark版本要一致,即3.1.2

3.编写代码
4.打包
- Project Structure – Artifacts

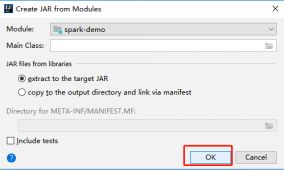
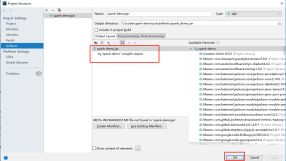
- Build – Build Artifacts – Build
- 在out目录下可以看到打包好的jar
5.将打包好的jar上传到{spark_home}下
三、在TDH集群上运行spark任务
1.local模式
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master local[3] --class io.transwarp.demo.MySpark /opt/spark-3.1.2-bin-hadoop2.7/spark-demo.jar
2.yarn-client模式
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode client --class io.transwarp.demo.MySpark /opt/spark-3.1.2-bin-hadoop2.7/spark-demo.jar
3.yarn-cluster模式
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode cluster --class io.transwarp.demo.MySpark /opt/spark-3.1.2-bin-hadoop2.7/spark-demo.jar
四、pycharm搭建pyspark开发环境
1.下载spark并解压
官网下载spark相应版本,解压缩到某个目录。例:C:\spark\spark-3.1.2-bin-hadoop2.7
2.新建python工程
新建python工程,选择python版本。我选择的是python3.7版本
3.pycharm上下载相关的依赖,比如numpy等

4.新建demo.py
5.打开Run-Edit Configurations.如图点击:

6.配置环境变量


7.add content root
在Settings-perferences中的project structure中点击右边的“add content root”,添加py4j-some-version.zip和pyspark.zip。(这两个文件都在C:\spark\spark-3.1.2-bin-hadoop2.7\python\lib下)。

8.开发程序,本地run测试
五、搭建pyspark运行环境
1.参考第一章节
2.需补充jar包
拷贝TDH-Client/hadoop/hadoop/lib/jsch-0.1.54.jar 到{spark_home}/jars目录
六、linux创建python虚拟环境
1.下载安装anaconda
- a.官方下载地址:https://www.anaconda.com/download/#linux
- b.上传到linux服务器的目录下
- c.sh Anaconda3-2021.05-Linux-x86_64.sh
- d.一路回车和yes
2.给anaconda配置环境变量
在/etc/profile增加如下内容并source:
export PATH=$PATH:/root/anaconda3/bin
3.增加清华的conda源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
4.创建虚拟环境
这里选择python3.7和1.16.4版本的numpy
conda create --name py3env --quiet --copy --yes python=3.7 numpy=1.16.4
5.查看新创建的虚拟环境
/root/anaconda3/envs目录下,可以看到建好的py3env文件夹,即python虚拟环境。将依赖程序mymath.py拷贝到/root/anaconda3/envs/py3env/lib/python3.7目录下。
6.压缩虚拟环境,拷贝到{spark_home}目录下
zip py3env.zip py3env/
cp py3env.zip /opt/spark-3.1.2-bin-hadoop2.7/
七、在TDH集群上运行pyspark任务
1.local模式
export PYSPARK_DRIVER_PYTHON=/root/anaconda3/envs/py3env/bin/python
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master local[2] /opt/spark-3.1.2-bin-hadoop2.7/demo.py
2.yarn-client模式
export PYSPARK_DRIVER_PYTHON=/root/anaconda3/envs/py3env/bin/python
export PYSPARK_PYTHON=py3env/py3env/bin/python
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode client --archives /opt/spark-3.1.2-bin-hadoop2.7/py3env.zip#py3env /opt/spark-3.1.2-bin-hadoop2.7/demo.py
3.yarn-cluster模式
export PYSPARK_DRIVER_PYTHON=py3env/py3env/bin/python
export PYSPARK_PYTHON=py3env/py3env/bin/python
/opt/spark-3.1.2-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode cluster --archives /opt/spark-3.1.2-bin-hadoop2.7/py3env.zip#py3env /opt/spark-3.1.2-bin-hadoop2.7/demo.py