ubunt18.04 搭建模型DeepLab v3+
目录
一、安装RTX2080TI驱动
二、安装CUDA
三、安装cudnn
四、安装anaconda3
五、使用anaconda安装tensorflow
五、DeepLab项目安装和测试
六、准备数据集
1、使用labelme进行图像标注
2、将所有数据的json文件转换成标签图片
3、mask灰度值的转换
4、将数据集分为训练集和测试集
5、制作指引文件TFRecord
七、训练与测试
1、修改训练脚本
2、网络训练
一、安装RTX2080TI驱动
1、英伟达官网选择合适的驱动
https://www.nvidia.com/Download/index.aspx?lang=en-us


驱动名称:NVIDIA-Linux-x86_64-450.66.run
2、禁用nouveau驱动
2.1 nouveau禁止命令写入文件
sudo gedit /etc/modprobe.d/blacklist.conf文件末尾添加以下语句:
blacklist nouveau
blacklist lbm‐nouveau
options nouveau modeset=0
alias nouveau off
alias lbm‐nouveau off2.2 调用指令禁止nouveau
echo options nouveau modeset=0 | sudo tee ‐a /etc/modprobe.d/nouveau‐kms.conf2.3 更新内核
sudo update‐initramfs ‐u2.3 重启系统
sudo reboot2.4 查看是否禁用成功
lsmod | grep nouveau无输出则代表禁用成功。
3、进入tty模式
ctrl + alt+ F14、关闭x server
sudo service lightdm stop
sudo init 35、卸载原有驱动
若安装过其它版本或其它方式安装过驱动,则执行此项。
sudo apt-get remove nvidia-*6、切换英伟达安装包指定目标,赋予权限并进行安装
cd ~/Downloads
chmod +x NVIDIA-Linux-x86_64-450.66.run
sudo sh NVIDIA-Linux-x86_64-450.66.run ‐‐no‐opengl‐files7、安装过程中出错


解决办法:
7.1 卸载原有驱动
sudo apt-get remove nvidia-*7.2 如果用.run安装包安装过,但失败了,一定要
sudo ./NVIDIA-Linux-x86_64-450.66.run -uninstall7.3 重启系统
不知道这一步有没有用,但是我做了。
sudo reboot7.4 关键一步
(参考链接:https://askubuntu.com/questions/798932/how-can-i-fix-unable-to-load-nvidia-installer-ncurses-v6-user-interface)
因为试了前三步之后,重新安装还是报错。
rm /usr/lib/nvidia/pre-install重新安装成功。
7.5 一点点说明
刚开始查找“The distribution-provided pre-install script failed”的原因,但是试了网上说的很多方法,都没有起作用。后来,查找安装日志nvidia-installer.log ,通过日志,开始查找“Unable to load:nvidia installer ncurses v6 user interface”的原因,最终在下面链接中找到解决办法。
https://askubuntu.com/questions/798932/how-can-i-fix-unable-to-load-nvidia-installer-ncurses-v6-user-interface
8、安装成功之后,在图形界面下可以通过命令,查看自己机器上详细的GPU信息。
nvidia-settings或者 打开终端执行:
nvidia-smi二、安装CUDA
1、下载CUDA
https://developer.nvidia.com/cuda-toolkit
如下图选择合适的版本:

cuda_11.0.3_450.51.06_linux.run
2、下载过程中遇到的问题
如下图所示,快下载结束的时候,提示“s段核心已转储”。
![]()
解决办法:
使用如下命令进行查看;
ulimit -a可以看到stack size 大小只有8192,太小了
使用如下命令,将stack size 改为100m,问题解决。
ulimit -s 102400参考链接:https://blog.csdn.net/seaflyren/article/details/104131269
3、安装
sudo sh cuda_xx.run(1)Abort与continue,选择continue
(2)图1中按回车键去掉Driver前面的X;选中options,进入图2界面,选中Driver Options,进入图3界面,前3项前面回车选X;图3界面选择Done,进入图2界面,选择Done,进入图1界面,选择Install,等待。

图1

图2

图3
https://blog.csdn.net/RealCoder/article/details/107722616
https://blog.csdn.net/RealCoder/article/details/107722616
5、查看cuda是否安装成功
使用下面命令查看
nvcc -V
但是在测试cuda的Samples时,出现问题。测试步骤如下:
cd /usr/local/cuda‐11.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery错误提示:

经查找,发现是英伟达驱动存在问题,使用
nvidia-smi错误提示:
![]()
解决办法:
参考链接:https://blog.csdn.net/hangzuxi8764/article/details/86572093

再次测试cuda的Samples时,成功

三、安装cudnn
安装方法一:
1、进入下载链接,选择对应的版本cudnn-11.0-linux-x64-v8.0.2.39
https://developer.nvidia.com/rdp/cudnn-download
2、安装步骤
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
3、验证是否安装成功
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2输出cudnn的版本即安装成功
安装方法二:
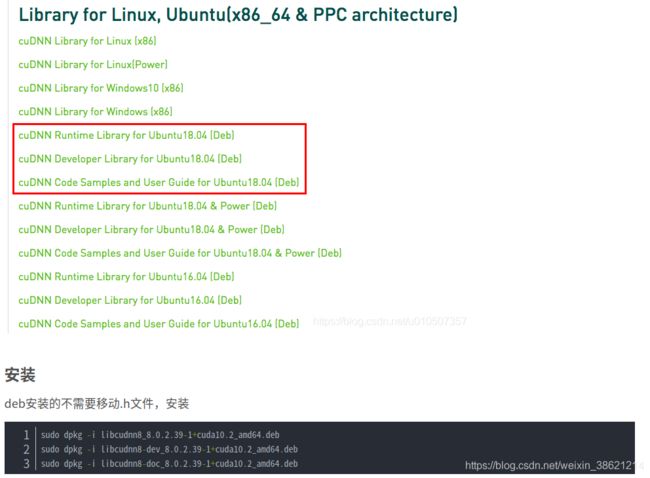
四、安装anaconda3
1、下载地址,下载对应的版本Anaconda3-2020.07-Linux-x86_64.sh
http、s://www.anaconda.com/download/#linux
2、安装
bash Anaconda3-2020.07-Linux-x86_64.sh3、更新环境变量
source ~/.bashrc或者手动添加环境变量
gedit ~/.bashrc在后面添加:
export PATH=/home/bai/anaconda2/bin:$PATH保存后执行
source ~/.bashrc4、测试是否安装成功
conda list如果有输出,则安装成功

5、anaconda国内环境配置
conda config ‐‐add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config ‐‐add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config ‐‐set show_channel_urls yes五、使用anaconda安装tensorflow
1、创建tensorflow环境,环境名称为tfgpu
conda create -n tfgpu python=3.72、激活tfgpu环境
source activate tfgpu3、在tfgpu环境下安装tensorflow1.14.0
conda install --channel https://conda.anaconda.org/anaconda tensorflow-gpu=1.14.04、在tfgpu环境下安装jupyter notebook
主要是为了验证tensorflow是否安装成功。
conda install ipython
conda install jupyter5、在环境下验证tensorflow是否安装成功
jupyter notebook打开一个新的Jupyter Notebook,输入以下命令,并运行。如果没有出现任何错误,则说明安装成功了。
import tensorflow as tf6、安装spyder
conda install spyder注意:这里安装的jupyter notebook和spyder是安装在tfgpu环境下,不是在Anaconda自带的jupyter notebook和spyder,这样它们才能使用tensorflow。每次使用时,需要先激活tfgpu环境
至此,环境配置基本完成,接下来Deeplab项目安装和测试。
五、DeepLab项目安装和测试
1、克隆deeplab项目
官方代码github地址:https://github.com/tensorflow/models/tree/master/research/deeplab
git clone https://github.com/tensorflow/models.git2、 添加项目依赖路径
sudo gedit ~/.bashrc添加如下语句:
export
PYTHONPATH=/home/xxxx/models/research/slim:/home/xxxx/models/research:$PYTHONPATHxxxx代码deeplab代码存放位置。
添加完成之后,执行,
source ~/.bashrc3、测试deeplab
cd /home/xxxx/models/research/deeplab执行:
python model_test.py最后输出ok。
4、遇到的问题
(1)问题:ModuleNotFoundError: No module named 'tf_slim'
解决办法:
pip install tf_slim(2)升级cmake
https://graspingtech.com/upgrade-cmake/
六、准备数据集
1、使用labelme进行图像标注
标注后生成json文件。
2、将所有数据的json文件转换成标签图片
建立文件夹/home/yons/Project/Deeplab/dataset/dataset_json/data_annotated
将所有数据集图像和labelme标注的json文件放置到data_annotated文件夹内
在/home/yons/Project/Deeplab/dataset路径下执行如下命令:
python labelme2voc.py dataset_json/data_annotated dataset_json/data_dataset_voc --labels labels.txt其中,labels.txt中是需要分割物体的类别,示例如下:

执行后生成文件夹data_dataset_voc,文件夹内容如下:
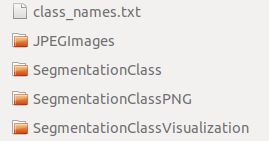
3、mask灰度值的转换
生成的mask必须为单通道(灰度图),为png格式。
注意,在制作mask时,对所有object的灰度像素值有要求。
对于所有objects包括background在内,在mask中要将灰度值标注为0, 1,...n。虽然产生的图片肉眼很难看出区别,但是这对训练是有效的。注意,不要把object的灰度值标注成10,20,100...。
因为自己的数据集中没有ignore_label,所以没有点设置为255(自己的数据集和CamVid都没有。如果存在ingore_label,在视觉上是白色的)。
关于图像的mask,设置如下:
将background的灰度值设置为0 ,object1,2,3,4,5的灰度值设置为1,2,3,4,5.
使用models/research/deeplab/datasets/remove_gt_colormap.py
deeplab/datasets 中自带的 remove_gt_colormap.py 脚本仅适用于带有 colormap 的单通道png图像。
如果是这种类型的png图像,则可以使用自带的 remove_gt_colormap.py 脚本进行转换。
执行如下命令去除mask的colormap:
python /home/yons/Project/Deeplab/models/research/deeplab/datasets/remove_gt_colormap.py --original_gt_folder dataset_json/data_dataset_voc/SegmentationClassPNG --output_dir dataset_json/data_dataset_voc/SegmentationClassPNG-raw4、将数据集分为训练集和测试集
创建data文件夹,文件夹的结构为:

将所有图片放到image下,对应的mask图(步骤3中在SegmentationClassPNG-raw下的图片)放到mask下。
python get_train_val.py将训练集和测试集的图片名称存入index下的train.txt trainval.txt val.txt中
python getnames.pytrain.txt:所有训练集的文件名称
trainval.txt:所有验证集的文件名称
val.txt:所有测试集的文件名称
5、制作指引文件TFRecord
运行以下命令:
python build_voc2012_data.py \
--image_folder="/home/yons/Project/Deeplab/dataset/data/image" \
--semantic_segmentation_folder="/home/yons/Project/Deeplab/dataset/data/mask" \
--list_folder="/home/yons/Project/Deeplab/dataset/data/index" \
--image_format="jpg" \
--output_dir="/home/yons/Project/Deeplab/dataset/data/tfrecord"image_folder :数据集中原输入数据的文件目录地址
semantic_segmentation_folder:数据集中标签的文件目录地址
list_folder : 将数据集分类成训练集、验证集等的指示目录文件目录
image_format : 输入图片数据的格式
output_dir:制作的TFRecord存放的目录地址(自己创建)
/
get_train_val.py
#!/usr/bin/env python
import numpy as np
import os, sys
import os.path
from PIL import Image
###############################
#处理原图
url = '/home/yons/Project/Deeplab/dataset/data/'#图片存储的文件夹名称
src_url = url + 'image/'
mask_url = url + 'mask/'
pathlist=os.listdir(src_url)
n=len(pathlist)#图片的数量
array = np.arange(n)#产生长度为n的序列
np.random.shuffle(array)#将arrray序列随机排列
#把path文件夹下以及其子文件下的所有.jpg图片移动到new_path文件夹下
def moveImg(path,new_path):
img=Image.open(path)
img.save(os.path.join(new_path,os.path.basename(path)))
#30%的数据生成验证集
src_new_path = url + 'val/'
mask_new_path = url + 'valannot/'
i=0
while(i <= (int(n*0.3))):
src_str = pathlist[array[i]]
DatasetPath = src_url + src_str
print('path: ',DatasetPath)
moveImg(DatasetPath,src_new_path)
mask_str = src_str.replace("jpg","png")
DatasetPath = mask_url + mask_str
print('path: ',DatasetPath)
moveImg(DatasetPath,mask_new_path)
i=i+1
#70%的数据生成训练集
src_new_path = url + 'train/'
mask_new_path = url + 'trainannot/'
while(i <= (n-1)):
src_str = pathlist[array[i]]
DatasetPath = src_url + src_str
print('path: ',DatasetPath)
moveImg(DatasetPath,src_new_path)
mask_str = src_str.replace("jpg","png")
DatasetPath = mask_url + mask_str
print('path: ',DatasetPath)
moveImg(DatasetPath,mask_new_path)
i=i+1
getnames.py
import os,shutil
from PIL import Image
train_path = '/home/yons/Project/Deeplab/dataset/data/train/'
filelist_train = sorted(os.listdir(train_path))
val_path = '/home/yons/Project/Deeplab/dataset/data/val/'
filelist_val = sorted(os.listdir(val_path))
test_path = '/home/yons/Project/Deeplab/dataset/data/test/'
filelist_test = sorted(os.listdir(test_path))
index_path = '/home/yons/Project/Deeplab/dataset/data/index/'
VOC_file_dir = index_path
VOC_train_file = open(os.path.join(VOC_file_dir, "train.txt"), 'w')
VOC_val_file = open(os.path.join(VOC_file_dir, "val.txt"), 'w')
VOC_test_file = open(os.path.join(VOC_file_dir, "trainval.txt"), 'w')
VOC_train_file.close()
VOC_val_file.close()
VOC_test_file.close()
VOC_train_file = open(os.path.join(VOC_file_dir, "train.txt"), 'a')
VOC_val_file = open(os.path.join(VOC_file_dir, "val.txt"), 'a')
VOC_test_file = open(os.path.join(VOC_file_dir, "trainval.txt"), 'a')
for eachfile in filelist_train:
(temp_name,temp_extention) = os.path.splitext(eachfile)
img_name = temp_name
VOC_train_file.write(img_name + '\n')
for eachfile in filelist_val:
(temp_name, temp_extention) = os.path.splitext(eachfile)
img_name = temp_name
VOC_val_file.write(img_name + '\n')
for eachfile in filelist_test:
(temp_name, temp_extention) = os.path.splitext(eachfile)
img_name = temp_name
VOC_test_file.write(img_name + '\n')
VOC_train_file.close()
VOC_val_file.close()
VOC_test_file.close()
七、训练与测试
1、修改训练脚本
1.1 添加数据集描述
在models/research/deeplab/datasets/data_generator.py文件中,添加自己的数据集描述:
num_classes定义:目标类别数目+背景;如果存在ignore_label,则为目标类别数目+背景+ignore_label
ignore_label为图像中不需要被检测的部分,被标记为255,一般不参与训练计算的部分。
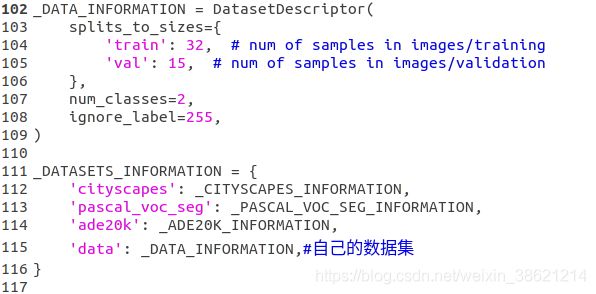
1.2 修改train_utils.py
在models/research/deeplab/utils/train_utils.py中,修改exclude_list的设置,作用是在使用预训练权重时,不加载该logit层。

1.3 修改train.py
如果想在DeepLab的基础上fine-tune其他数据集, 可在deeplab/train.py中修改输入参数。
一些选项:
使用预训练的所有权重,设置initialize_last_layer=True
只使用网络的backbone,设置initialize_last_layer=False和last_layers_contain_logits_only=False
使用所有的预训练权重,除了logits。因为如果是自己的数据集,对应的classes不同(这个我们前面已经设置不加载logits),可设置initialize_last_layer=False和last_layers_contain_logits_only=True

2、网络训练
2.1 下载预训练模型
下载地址:https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/model_zoo.md
下载的预训练权重为xception_cityscapes_trainfine
解压目录:
models/research/deeplab/deeplabv3_cityscapes_train
2.2 类别不平衡修正
如果background占了很大比例,设置的权重比例为1,10,15,等等
在train_utils.py文件中add_softmax_cross_entropy_loss_for_each_scale函数中第一句加上你设置的权重,例如 loss_weights=[1.0, 10.0, 15.0, 10.0, 10.0, 10.0] 其中1.0是背景权重,后面是几个类别物体的权重。权重比例参考图像中目标像素数与背景像素数之比。(我在训练过程中,loss一直降不下去。把权重比设大就可以了,可能因为目标太小,背景占比例大;训练过程中,需要将目标的权重设大。)

旧版deeplab代码中修改权重:
###changes
ignore_weight = 0
label0_weight = 1
label1_weight = 1500
not_ignore_mask = tf.to_float(tf.equal(scaled_labels,0))*label0_weight+tf.to_float(tf.equal(scaled_labels,1))*label1_weight+tf.to_float(tf.equal(scaled_labels,ignore_label))*ignore_weight
###
one_hot_labels = tf.one_hot(scaled_labels, num_classes, on_value=1.0, off_value=0.0)
tf.losses.softmax_cross_entropy(
one_hot_labels,
tf.reshape(logits, shape=[-1, num_classes]),
weights=not_ignore_mask,
scope=loss_scope)2.3 训练指令
注意如下几个参数:
tf_initial_checkpoint:预训练的权重
train_logdir: 训练产生的文件存放位置
dataset_dir: 数据集的TFRecord文件
dataset:设置为在data_generator.py文件设置的数据集名称
与文件夹models在同一路径下执行如下的训练指令:
#!/bin/bash
#update PYTHONPATH
export PYTHONPATH=$PYTHONPAATH:`pwd`/models/research:`pwd`/models/research/slim
#set up the working environment
CURRENT_DIR=$(pwd)
WORK_DIR="${CURRENT_DIR}/models/research/deeplab"
python "${WORK_DIR}"/train.py \
--logtostderr \
--training_number_of_steps=10000 \
--train_split="train" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--train_crop_size=321,321 \
--train_batch_size=2 \
--dataset="data" \
--tf_initial_checkpoint='/home/yons/Project/Deeplab/models/research/deeplab/deeplabv3_cityscapes_train/model.ckpt' \
--train_logdir='/home/yons/Project/Deeplab/result/data_train/train' \
--dataset_dir='/home/yons/Project/Deeplab/dataset/data/tfrecord' 2.4 测试结果可视化
与文件夹models在同一路径下执行如下的可视化指令:
#!/bin/bash
#update PYTHONPATH
export PYTHONPATH=$PYTHONPAATH:`pwd`/models/research:`pwd`/models/research/slim
#set up the working environment
CURRENT_DIR=$(pwd)
WORK_DIR="${CURRENT_DIR}/models/research/deeplab"
python "${WORK_DIR}"/vis.py \
--logtostderr \
--vis_split="train" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--vis_crop_size=100,1500 \
--dataset="data" \
--colormap_type="pascal" \
--checkpoint_dir='/home/yons/Project/Deeplab/result/data_train/train'\
--vis_logdir='/home/yons/Project/Deeplab/result_img' \
--dataset_dir='/home/yons/Project/Deeplab/dataset/data/tfrecord'vis_split:设置为测试集
vis_crop_size:设置100,1500为图片的大小
dataset:设置为我们在data_generator.py文件设置的数据集名称
dataset_dir:设置为创建的TFRecord
colormap_type:可视化标注的颜色
可到文件夹result_img下查看可视化结果
2.5 性能评估
#!/bin/bash
#update PYTHONPATH
export PYTHONPATH=$PYTHONPAATH:`pwd`/models/research:`pwd`/models/research/slim
#set up the working environment
CURRENT_DIR=$(pwd)
WORK_DIR="${CURRENT_DIR}/models/research/deeplab"
python "${WORK_DIR}"/eval.py \
--logtostderr \
--eval_split="val" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--eval_crop_size=100,1500 \
--dataset="data" \
--checkpoint_dir='/home/yons/Project/Deeplab/result/data_train/train'\
--eval_logdir='/home/yons/Project/Deeplab/result_img/eval' \
--dataset_dir='/home/yons/Project/Deeplab/dataset/data/tfrecord' \
--max_number_of_evaluations=1在eval_logdir下查看mIoU的值。
在data_train/train下查看过程loss。
至此,实践完。