Spark3.1.2 Standalone高可用HA分布式部署(含pyspark)
目录
- 1. 节点规划
- 2. 下载解压
- 3. 修改配置
-
- 3.1 修改conf/spark-env.sh
- 3.2 修改conf/workers
- 4. 配置环境变量
- 5. 分发spark文件
- 6. 启动
- 7. 查看Web界面
- 8. standby master切换
- 9. spark-shell使用
- 10.PySparkShell使用
1. 节点规划
| 服务 | hostname | 备注 |
|---|---|---|
| master | bigdata001、bigdata002、bigdata003 | |
| slave | bigdata001、bigdata002、bigdata003 | |
| zookeeper | bigdata001、bigdata002、bigdata003 | 安装请参考基于Centos7分布式安装Zookeeper3.6.3 |
| python3.9.6 | bigdata001、bigdata002、bigdata003 | 安装请参考centos7同时安装Python2和Python3 |
以下操作除非特殊说明,否则都是在bigdata001上操作
2. 下载解压
[root@bigdata001 opt]#
[root@bigdata001 opt]# wget --no-check-certificate https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
[root@bigdata001 opt]#
[root@bigdata001 opt]# tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
[root@bigdata001 opt]#
[root@bigdata001 opt]# cd spark-3.1.2-bin-hadoop3.2/
[root@bigdata001 spark-3.1.2-bin-hadoop3.2]#
3. 修改配置
3.1 修改conf/spark-env.sh
[root@bigdata001 conf]#
[root@bigdata001 conf]# cp spark-env.sh.template spark-env.sh
[root@bigdata001 conf]#
添加内容如下:
export JAVA_HOME=/opt/jdk1.8.0_201
SPARK_MASTER_HOST=`hostname`
SPARK_MASTER_WEBUI_PORT=8060
SPARK_LOCAL_DIRS=/opt/spark-3.1.2-bin-hadoop3.2/local
SPARK_WORKER_CORES=3
SPARK_WORKER_MEMORY=6g
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata001:2181,bigdata002:2181,bigdata003:2181 -Dspark.deploy.zookeeper.dir=/spark/standalone_ha"
3.2 修改conf/workers
[root@bigdata001 conf]#
[root@bigdata001 conf]# cp workers.template workers
[root@bigdata001 conf]#
内容如下:
[root@bigdata001 conf]#
[root@bigdata001 conf]# cat workers
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
bigdata001
bigdata002
bigdata003
[root@bigdata001 conf]#
4. 配置环境变量
在/root/.bashrc添加如下内容:
export SPARK_HOME=/opt/spark-3.1.2-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
执行source /root/.bashrc使环境变量生效
5. 分发spark文件
[root@bigdata001 opt]#
[root@bigdata001 opt]# scp -r spark-3.1.2-bin-hadoop3.2/ root@bigdata002:/opt
[root@bigdata001 opt]#
[root@bigdata001 opt]# scp -r spark-3.1.2-bin-hadoop3.2/ root@bigdata003:/opt
[root@bigdata001 opt]#
6. 启动
- 启动bigdata001上的master和所有的slave
[root@bigdata001 opt]#
[root@bigdata001 opt]# sh $SPARK_HOME/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-3.1.2-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.master.Master-1-bigdata001.out
bigdata001: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-3.1.2-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bigdata001.out
bigdata003: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-3.1.2-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bigdata003.out
bigdata002: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-3.1.2-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bigdata002.out
[root@bigdata001 opt]#
- 分别在bigdata002、bigdata003上启动standby master
[root@bigdata002 ~]#
[root@bigdata002 ~]# /opt/spark-3.1.2-bin-hadoop3.2/sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-3.1.2-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.master.Master-1-bigdata002.out
[root@bigdata002 ~]#
[root@bigdata003 ~]#
[root@bigdata003 ~]# /opt/spark-3.1.2-bin-hadoop3.2/sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-3.1.2-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.master.Master-1-bigdata003.out
[root@bigdata003 ~]#
7. 查看Web界面
查看bigdata001:8060、bigdata002:8060、bigdata003:8060界面分别如下:
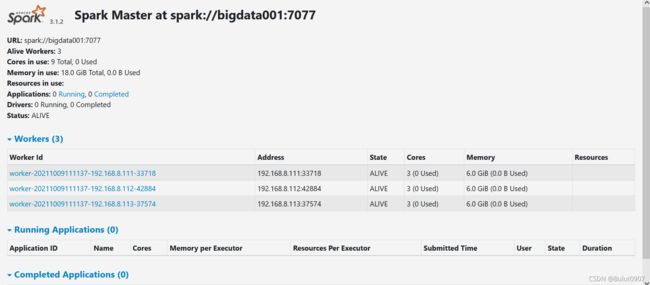
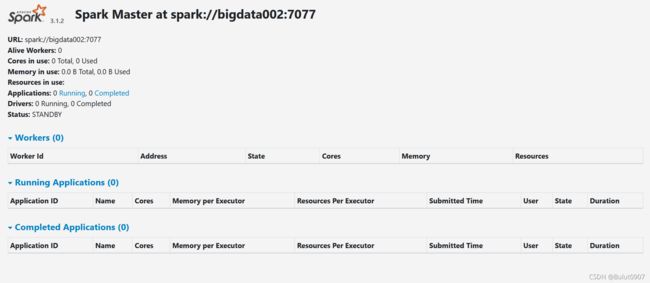
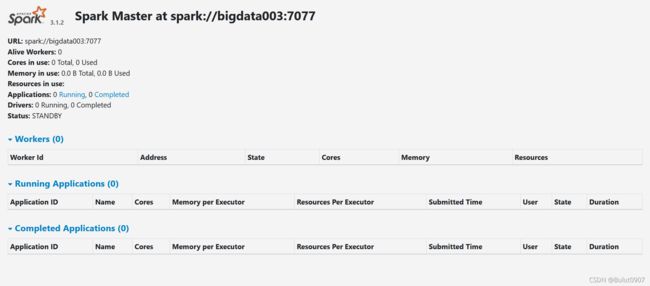
8. standby master切换
现在kill掉bigdata001上的master
[root@bigdata001 opt]#
[root@bigdata001 opt]# jps
......省略部分......
3821 Master
......省略部分......
[root@bigdata001 opt]#
[root@bigdata001 opt]# kill -9 3821
[root@bigdata001 opt]#
再次查看bigdata002:8060,结果如下:
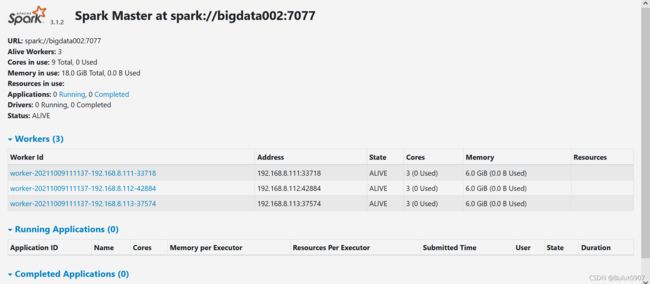
9. spark-shell使用
[root@bigdata001 opt]#
[root@bigdata001 opt]# $SPARK_HOME/bin/spark-shell --master spark://bigdata001:7077,bigdata002:7077,bigdata003:7077
2021-10-09 11:40:35,975 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://bigdata001:4040
Spark context available as 'sc' (master = spark://bigdata001:7077,bigdata002:7077,bigdata003:7077, app id = app-20211009114042-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.parallelize(Seq(1, 2, 3, 4, 5, 6)).toDF("number").show()
+------+
|number|
+------+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
+------+
scala>
10.PySparkShell使用
[root@bigdata001 opt]#
[root@bigdata001 opt]# $SPARK_HOME/bin/pyspark --master spark://bigdata001:7077,bigdata002:7077,bigdata003:7077
Python 3.9.6 (default, Oct 9 2021, 14:08:00)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
2021-10-09 14:46:58,145 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.6 (default, Oct 9 2021 14:08:00)
Spark context Web UI available at http://bigdata001:4040
Spark context available as 'sc' (master = spark://bigdata001:7077,bigdata002:7077,bigdata003:7077, app id = app-20211009144700-0002).
SparkSession available as 'spark'.
>>> sc.parallelize([(1,), (2,), (3,), (4,), (5,), (6,)]).toDF(['number']).show()
+------+
|number|
+------+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
+------+
>>>