挖财的 Kubernetes 容器化之路

挖财内部对容器化项目的代号为 K2 (乔戈里峰),乔戈里峰是世界第二高峰,但攀登极富挑战,寓意就是面对挑战,勇攀高峰;)。项目从 2016 年 11 月到现在已经有三年的时间了,如今挖财内部测试环境早已全部 Docker 容器化,而线上环境也运行着重要的业务。经历从零到一的整个落地过程,回顾下来,这座高峰算是拿下了。再看 Kubernetes 技术本身现在也是遍地开花,早已赢得容器编排的战争,剩下来就是各个企业的落地实践。倒是 Docker 公司,这个创建 Docker 的企业沦落如此,多少有点令人唏嘘,唯有 Respect。
时间线

看了一下项目提交的 Git 记录,第一次提交时间是 2016-11-01 Tue。
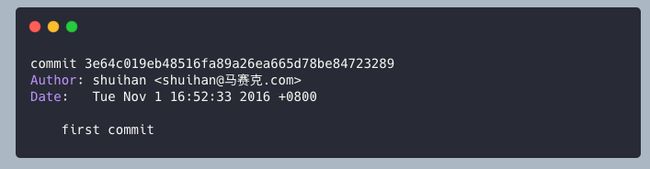
2016 年 11 月初开启
2017 年 1 月底 V1.0 上线
2017 年 6 月底测试环境全面推开
2017 年 7 月线上机器学习环境线上试点
2017 年 10 月线上业务试点
2018 年 7 月 V2.0 版本
2018 年 9 月挖财云版本(整合运维监控、告警、日志和容器系统)
2018 年 12 月支持多集群管理
2019 年 6 月私有化分支版本上线
现状
测试环境
当前测试环境有一个 Kubernetes 集群(Kubernetes 1.11.x),空间( namespace )总数有 500+,应用数( Deployment + StatefulSet ) 4400+,实例数( Pod ) 4000+(因为测试环境大部分应用都只有 1 个,有些是处于暂停状态,即 0 个副本,因此实例数少于应用数)。
题外话,话说 Kubernetes 升级的历程也相当血泪,早期的配置变更,向下的兼容性等等。
线上环境
线上环境有三个集群,一个机器学习集群(Kubernetes 1.7.x),一个私有云集群(Kubernetes 1.13.x),有个主体业务集群(Kubernetes 1.13.x),粗率统计了一下,空间数 50+,应用数 500+,实例数 1000+。
测试环境 + 线上环境总体运行有 5000+ 的 Pod 数,这个数量已经持续了很长一段时间。大概 2018 年底的时候就是这个数据,之后因为业务的调整等等原因,数量级没有一个大的增幅。
技术选型
原生方案 or 自研
对于是否使用原生方案,我们没有过多的犹豫,确定基于 Kubernetes API 上层封装抽象,其它底层最大化使用原生方案。首先 Kubernetes 肯定不会维护一个内部版本,对于一个快速迭代的项目,人力是一方面,后续的可维护性也是个大问题,而基于上层 API 的抽象和封装可以带来最大的灵活和便利性。针对客户端工具,内部有人建议开发命令行工具,摒弃 Dashboard。但是基于以往的经验,命令行工具的维护性以及用户上手成本相比 Dashboard 要更高。就拿 Docker 来说,虽然很火,但是实际能够熟练书写 Dockerfile 构建 Docker 镜像的开发、测试并不多,放到 2019 年来说这个比例依然不高。对于大部分用户 Dashboard 可以最大的简化上手难度,推广和维护性来说也更方便。
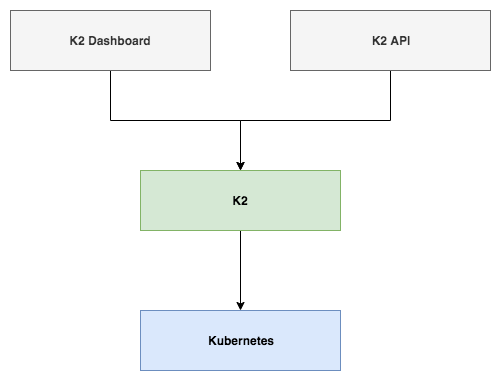
底层 Kubernetes,中间层为 K2,对外暴露则是 Dashboard 和 K2 API。对于大部分用户使用 Dashboard 即可满足需求,如果有 API 的需求也提供相关渠道。K2 使用 Go 编写,针对 Namespace、Service、Deployment、StatefulSet、Ingress、Job、ConfigMap 有自身的封装抽象,屏蔽这些原生理念给用户带来的困惑,尽可能的降低用户理解难度。K2 Dashboard 则使用 Ant Design Pro 编写,好吧,不自觉的想到了之前 Ant Design 的圣诞彩蛋事件,当然这并不妨碍它的易用性。以下为平台的部分截图:

我们内部最开始使用的 Kubernetes 版本为 1.3.x,早期 Kubernetes 这块的用户和权限管理并不完善(后续的 RBAC 机制个人认为也很繁琐)。我们自行在 K2 上实现了一套用户和权限管理机制,权限只在空间层,应用层权限受限于空间角色(在某些场景空间层权限并不能满足需求,我们内部的另外一个版本是细化到应用层的)。测试环境和生产环境功能性是有细微差别的,比如测试环境所有的资源都是自助式的,而生产环境保持尽可能的自助化条件下,引入了一些资源申请机制(如生产环境空间需要走 审批流程 )。测试环境的空间还引入了 生命周期机制 ,在有效期内用户可以续期(续期有上限),如果过期则会自动销毁(提醒续期的同时会备份编排文件,即使销毁了也可以轻易的恢复)。空间生命周期一定程度上提升了资源利用率,而生产环境的空间则没有有效期一说。因为业务的特殊性,CPU 资源利用率是非常低的,因此我们测试环境节点和生产环境节点 CPU 都是超配的(Limits 和 Requests 控制)。为了稳定性生产环境内存是没有超配的,但测试环境内存则是 2 倍超配的。测试环境提供了 Web 终端工具,方便用户登录容器,而生产环境一是为了安全和审计并没有提供 Web 终端工具。我们在堡垒机上提供了 k2ctl 命令行工具方便用户登录线上容器, k2ctl 集成了 K2 的权限控制,原理也很简单,底层封装 kubectl。等等,以上只是列举了一部分测试环境和生产环境功能区别,简单来说在实际场景下,测试环境的自由度要更高,功能性也更多,而生产环境则是安全和稳定性排在首位,其它的细节这里就不过多介绍了。
镜像构建
早在 2015 年中的时候公司内部就推行微服务化了,后端统一使用 Spring Boot + Dubbo 的技术栈,前端则是 React + Node.js 的技术栈。因为技术栈比较统一的原因,所以比较好做标准化。结合内部的打包平台(内部代号 Obelisk )构建通用 Dockerfile 模板,在实际构建的过程中动态修改 Dockerfile 并生成镜像,然后 Push 到镜像中心 Harbor。
镜像构建使用的技术中还提到了 Kubernetes Plugin,在没有使用 Docker 之前,Jenkins Slave 都是使用的虚拟机运行构建软件包的。之后在内部构建了 Kubernetes 集群,然后相应的 Jenkins Slave 则通过 Kubernetes Plugin(因内部需求,内部修改 Kubernetes Plugin 源码以支持 HostNetwork 网络)动态生成,如此可以尽可能的保证打包环境的纯净性。其中 Jenkins Slave 镜像是使用 docker-jnlp-slave 定制的,集成了构建相关的环境,如 Java、Maven、npm 等工具。
当然除了 Spring Boot 和 Node.js 应用,公司还是有一些使用其它技术栈的项目,如 Python、Go 以及 Tomcat War 包等项目。对于这类比较少的项目,构建方式是在相关项目代码库中加入 Dockerfile,构建的时候通过指定的 Dockerfile 构建镜像,以满足业务需求。
当前内部 Harbor 使用的版本是 1.5.x ,针对 Harbor 镜像的清理这里需要提一下,我们定制了清理脚本,通过自定义保留版本数定期清理过期镜像 Tag,然后选择合适的时间进行镜像 GC 操作。
网络
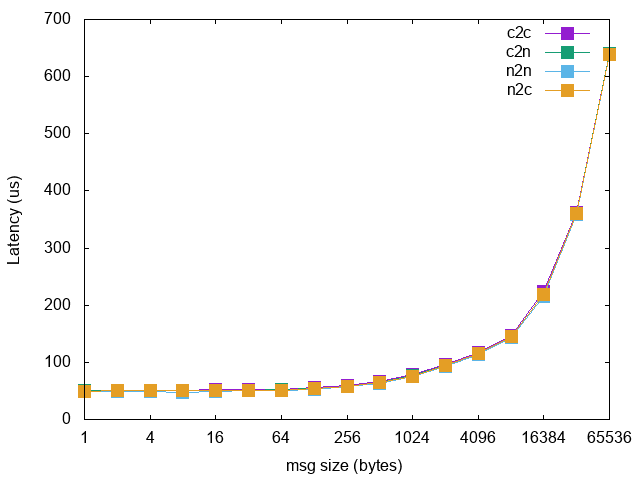
在内部平台最早构建的时候,使用的网络方案为 Flannel VXLAN 模式,但是测试过程中发现很多的不便利性。基于 Overlay 的性能问题是一方面,对于测试环境,很多时候都有直连 Pod Debug 的需求。还有早期的时候虚拟机和容器环境是并存的,基于 Dubbo 的服务注册发现的网络访问也是一个问题。再者数据库这些应用都是部署在集群外部的,Overlay 网络访问外部数据库都走 NAT,在数据库端追踪源 IP 的时候不便于定位实际服务。最后,决定采用 Calico BGP 大三层网络方案,通过内部交换机打通容器和实际网络,如此以上说的问题自然就解决了。Calico 网络性能接近裸机网络,下图是早期的一个测试结果:
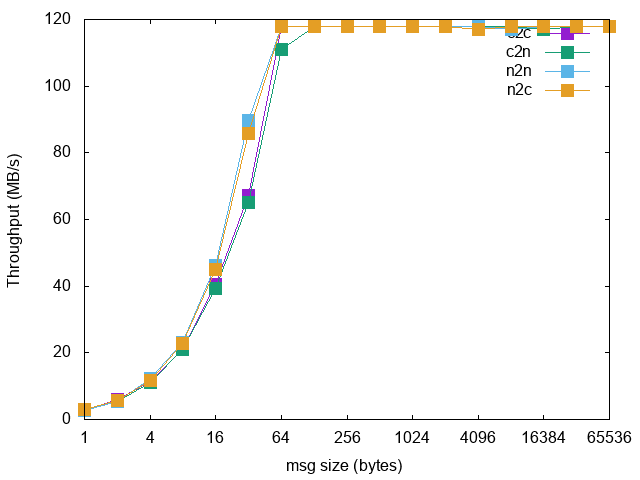
当然,实际使用什么网络方案还要看你自己的应用场景,我们机器学习平台(当前主要运行分布式 Jupyter)使用的网络方案则是基于 Flannel VXLAN 来做的,原因是没有测试环境描述的这些需求,Flannel 方案本身够简单。
日志
日志方案使用业界比较成熟的 EFK(Elasticsearch + Filebeat + Kibana)方案,关于 EFK 本身这里不过多解释。这里主要介绍的是如何通过 EFK 收集到容器的业务日志,我们的服务主要是 Java 相关的,大部分日志都是输出到本地文件的,除了业务日志还有一些应用访问日志、中间件组件日志以及监控日志等。如果统一都输出到标准输出的话,虽然可以通过配置实现,但是可读性却不是很好。最后采用的方案是,兼容现有的方案,自动挂载本地日志卷到容器,虚拟机中存储在什么地方就存储在什么地方。
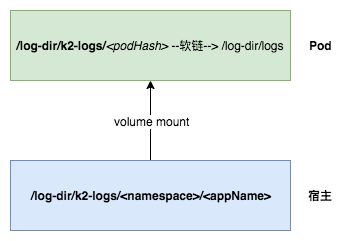
如图所示,定义宿主目录 /log-dir/k2-logs/
以上是针对日志文件落盘的解决方案,对于一些开源的服务或者日志只输出到标准输出的服务则需要另外考虑。实际上我们内部对于服务日志落盘到文件的同时,服务日志也会打一份到标准输出,主要辅助用户排查问题,提供基本的 tail -f 的功能。如果我们针对标准输出和落盘日志文件统一都收集的话肯定会导致重复收集,因此我们对标准输出又提供了额外的方式收集。

针对标准输出收集我们的方案如上图所示,利用 Filebeat 配置动态加载的功能,生成和分发 Filebeat 配置,达到标准输出日志收集的目的。默认标准输出日志收集是关闭的,用户可以在应用界面自主开启收集。
监控告警
监控数据展示使用 Grafana,Kubernetes 数据收集使用 kube-state-metrics,存储则使用 Prometheus。告警这块因为内部有自研的服务,因此直接对接内部服务。系统级别的告警利用 Prometheus 的数据,应用状态相关则是自研的 Kubernetes eventer 对接自研告警服务。Kubernetes eventer 主要借鉴了 heapster 的 eventer 组件,功能除了监听 Kubernetes 事件,还会上报一些事件如容器 OOM 事件到 Kubernetes,还做了一些筛选和收敛工作,以达到减少误报的目的。早期我们针对 Kubernetes 的事件还会暴露给 Prometheus,后来我们有自己的事件中心平台,相关的事件直接 push 到内部事件中心,便于后续展示和分析。
用户行为分析和统计
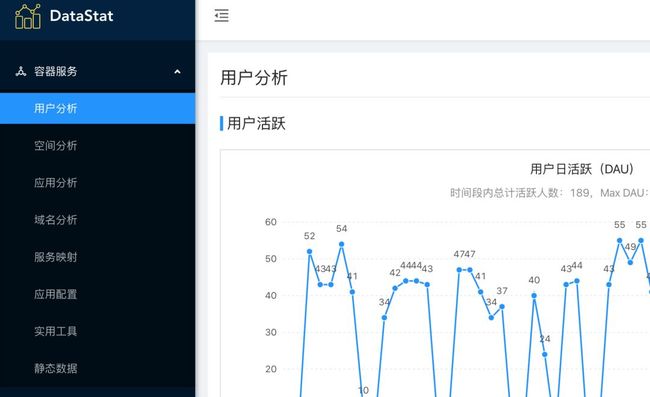
针对用户在平台的操作,我们后端服务对相关的接口操作做了一些埋点,统一上报内部的 DataStat 平台,根据这些数据一方面是统计相关的数据,另外一方面则是分析用户的操作然后再改善平台(如根据访问频次确定核心用户,咨询他们采纳一些合理的意见等等)。
其它
针对完整的组件和架构方案,可以具体看下图:

为了安全性,Kubernetes 集群启用了 TLS 和 RBAC 部署,使用 Nginx 和 Keepalived 作为 kube-apiserver 的 HA 组件,ingress-nginx controller 也是使用类似的方案做了高可用。关于 Kubernetes 集群部署业界也提供了诸如 kubeadm 和 kubespray 的部署方案,我们内部则是定制了一套 Kubernetes Ansible Playbook,集群组件使用的是二进制安装,Systemd 管理,最大化保持可控。
这里还要提一下容器底层存储驱动,我们先用的 Device Mapper,再用的 Overlay,之后又变更成 Overlay2。最早调研选型是准备用 Device Mapper 的,结合之前的使用经验 Device Mapper 运维成本较其它高而且本身也存在很多问题。最后实际选用的是当时来说较为激进的 Overlay 驱动,Overlay 本身有一些缺陷,比如 inode 问题和不能限制容器使用的存储空间大小的问题。之后又出了 Overlay2,Overlay2 解决了之前 Overlay 的很多问题,当然也可以指定存储空间限制了,而且已经是 Production Ready 了,所以我们又把存储切到了 Overlay2。
趟过的坑
2018 遇到的问题集锦:https://github.com/opskumu/issues/issues/19
2019 遇到的问题集锦:https://github.com/opskumu/issues/issues/23
以上是这两年遇到的一些关于 Kubernetes 问题的碎片化记录,大部分的问题都记录了,感兴趣的可以看点击查看。这里说一些使用 Kubernetes 构建容器平台遇到的一些典型的问题:
Kubernetes DNS 解析偶尔丢包 5s 延迟问题
从 2017 年平台上线之后,偶尔业务出现 DNS 请求超过 5s 的问题困扰了我很久。这个问题在社区 Issue DNS intermittent delays of 5s[1] 也讨论了很长一段时间,跨度为两年之久,直到现在虽然 Issue 已经关闭,但是底下时常还有一些讨论。Issue 中很清楚的描述了问题产生的原因,是内核 conntrack 模块本身的 bug。那如何解决呢,Issue 中也提到了很多方法,试过其中的大多数方式,有些并没有解决。其中除了升级内核,个人最建议的方式还是使用 Nodelocal DNS Cache[2] 去解决这个问题,但是它也有一个问题,就是每次升级组件的时候,所在主机的 DNS 就会中断。
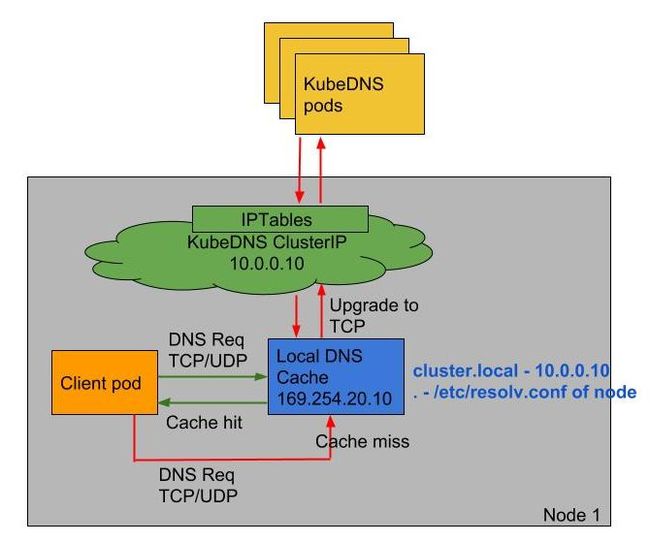
关于 Nodelocal DNS Cache Graduate NodeLocal DNSCache to beta[3] 更好的解决方案,在现有的基础上无需改动即可生效,而且可以规避 DNS Cache 组件更新所在节点 DNS 请求中断的问题,不过到目前还没有实现。
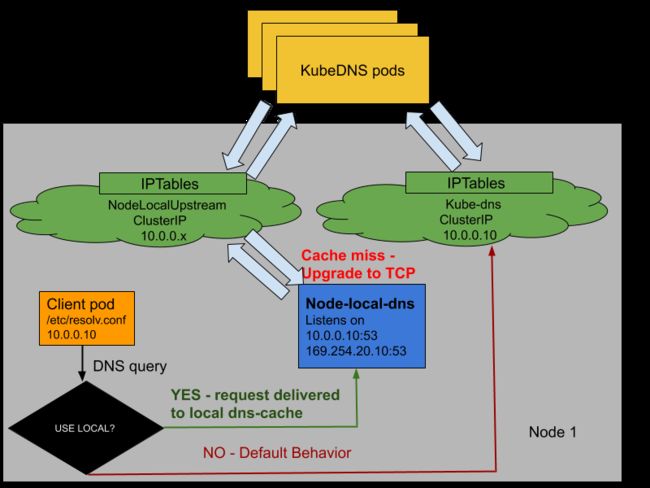
关于这个问题,腾讯云容器团队也详细地说明了 Kubernetes 集群中夺命的 5 秒 DNS 延迟[4]的问题,大家也可以参考。
Java 程序在 Docker 中运行的资源问题
这个严格来说不是 Java 本身的问题,只是早期 Java 对容器支持不好导致的。就拿容器中的 top、free 指令,新人在容器中使用这些指令的时候,通常对输出都会感到疑惑。比较彻底的一个解决方式就是借助 LXCFS,这样无论是 Java 程序的运行也好,还是 top、free 这些指令,它们从 /proc 下读取资源信息都是实际容器配置的资源限制。不过我更倾向于其它方式解决而不是 LXCFS ,因为之前调研的时候 LXCFS 本身也存在一些问题,另外也不想增加一层维护成本,针对 Java 程序遇到的问题从 Java 层面上解决。
我们内部使用的 Java 版本都是基于 8 的,因此主要关注的是 Java 8 相关的支持。最早 Java 从 8u131 (17 年 4 月发布)开始通过选项支持对容器内存和 CPU 的限制,具体见 Java SE support for Docker CPU and memory limits[5],主要是 CPU 层面支持 GC 线程数和 JIT 编译线程数以及内存层面 Heap 大小限制。8u191 的时候有了更好的支持,8u131 并没有解决 Runtime.getRuntime().availableProcessors() 这类的问题,8u191 还可以通过 -XX:ActiveProcessorCount=count 自定义 CPU 数量,并且新版本还支持对 Java Heap 设置百分比,具体见 JDK 8u191 Update Release Notes[6]。可以这么说从 8u191 才真正解决了之前 Java 服务运行在容器中的问题,建议通过升级 Java 版本解决。篇幅有限,更详细的推荐阅读这篇文章 JVM Memory Settings in a Container Environment[7],解释的相当清楚。
除了 Java 版本升级之外,我们容器的 Java 程序启动脚本还集成了 Fabric8 Java Base Image OpenJDK 8(JDK)中提供的脚本。在最早 Java 版本本身不支持对 Heap 限制以及百分比设置的时候,我们通过这个脚本根据实际分配给容器的内存大小动态伸缩 Heap Size。另外,还支持通过环境变量注入 Java 选项,支持通过环境变量开启 Debug 项等等,推荐 Java 程序容器化集成这个脚本,非常灵活。
容器中的僵尸进程
正常情况下,如果一个容器运行一个进程,那么不太可能出现僵尸进程的问题。对于内部的 Java 程序是没有这个问题的,我们一个容器就跑一个程序,但是有些应用很多都是跑的多进程的(比如 Jenkins slave 构建容器),这类情况下就可能会出现僵尸进程。众所周知,容器不像操作系统,正常情况下它是没有 init 进程的,PID 为 1 的一般是应用本身,而普通进程一般是不会捕获僵尸进程的,这就导致了有些多进程容器中出现 N 多的僵尸进程。
Docker 1.13.x 之后支持 --init 选项(集成 tini),但是 Kubernetes 本身是不支持 --init 项的,不过我们可以在镜像中加入 tini 或 dumb-init 实现,范例如下(详细建议阅读官方 guied):
# Add Tini
ENV TINI_VERSION v0.18.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
ENTRYPOINT ["/tini", "--"]
# Run your program under Tini
CMD ["/your/program", "-and", "-its", "arguments"]
# or docker run your-image /your/program ...
# Runs "/usr/bin/dumb-init -- /my/script --with --args"
ENTRYPOINT ["/usr/bin/dumb-init", "--"]
# or if you use --rewrite or other cli flags
# ENTRYPOINT ["dumb-init", "--rewrite", "2:3", "--"]
CMD ["/my/script", "--with", "--args"]
不过比起直接集成 init 工具,更建议的是在 Kubernetes 层解决这个问题。我们都知道,每个 Kubernetes Pod 有一个 pause 容器组件,一般我们说起它的功能就是 Pod 内容器共享网络。其实除了共享网络还有睡觉之外,它还会捕获僵尸进程。默认 Kubernetes Pod 内的 PID namespace 是不共享的,早期我们可以通过 kubelet --docker-disable-shared-pid=false 选项开启 Pod 内 PID namespace 共享,如此对应节点的 Pod 中 PID 为 1 的进程就是 pause 了,它便可以捕获处理僵尸进程了。kubelet 选项有一个坏处,就是调度到节点的 Pod 都会共享 PID namespace,社区就觉得应该移除这个选项,在 Pod 层实现,社区讨论见 Remove –docker-disable-shared-pid from kubelet[8]。在 Kubernetes 1.10 就开始支持 Pod Spec 添加 ShareProcessNamespace 字段,支持在 Pod 层开启 PID namespace 共享。
容器内存监控数据的问题
其实容器内存这个问题困扰了我很久,查了很多资料之后,最初使用的监控数据是 container_memory_working_set_bytes,比如这篇文章 A Deep Dive into Kubernetes Metrics — Part 3 Container Resource Metrics[9] 也是推荐这个值的。
The better metric is container_memory_working_set_bytes as this is what the OOM killer is watching for.
简而言之,OOM Killer 评判的值就是 container_memory_working_set_bytes,可是实际对比发现,有些 Java 容器实际的内存占用和 container_memory_working_set_bytes 相差甚远,很多该值是 90%+ 的,实际使用 ps 工具查看确只占用 50% 或更低。最后我们是通过 container_memory_usage_bytes - container_memory_cache 计算容器内存占用,相比 working_set 要准确多了。至于最后为什么使用这个计算,时间跨度有点长了,当时也没有记录,记得除了查资料之外还看了 docker stats 这块的源码。
Calico CNI 网络 IP 没有正常回收的问题
这个之前知乎相关的分享好像也提到过,也是一个比较恼人的问题,后来内部就专门写了个脚本,定时做一些清理释放的工作。
Pod 通过 Service IP 访问不了自己的问题
当 Pod 通过自身 Service IP 访问的时候,如果 kube-proxy 刚好调度的实例是 Pod 自身的话,这个时候就出现无法访问的问题。一开始排查以为是 --hairpin-mode 配置的问题,实际测试下来并不是。具体详细的排查流程已经更新到前文提到的 Issue 里面了 Pod 无法通过 Service IP 访问自身[10]。
容器内自定义时间的问题
测试需求偶尔会有自定义服务器时间的问题,但是在容器内这个问题基本还处于无解状态。
还有很多其它的一些问题,包括 Kubernetes 本身的 Bug,相关组件如 KubeDNS/CoreDNS 的 Bug 等等,这里不一一列举了,有些问题后续如果想到了也会再补充。
其它
技术之外,产品本身
容器化相关,技术的比重是非常高的,如果容器底层不稳定,就没有上层一说了,但是又不能局限于技术。K2 这个项目可以在内部不断迭代的原因就是产品本身,2018 年初加入的小伙伴给 K2 注入了很多产品化的实质性东西。从最初 K2 只是一个单一的容器平台,慢慢的和内部平台融合成为了现在的挖财云。各平台的聚合,本身就是技术的融合,也是入口的融合。融合的同时还解决了内部跨各个平台协作的效率问题,这些带来的效益是显而易见的。对比 1.0 时候的 K2,无论从用户体验,还是上手成本都有非常大的提升。
基于容器的云原生应用设计原则
关于应用在容器中运行要注意的一些原则,国外有人已经总结的相当好了,并且还出版了一本书 《Kubernetes Patterns: Reusable Elements for Designing Cloud-Native Applications》(文末附有下载方式)。以下直接翻译摘录一部分内容:
Cloud Native Container Design Principles:
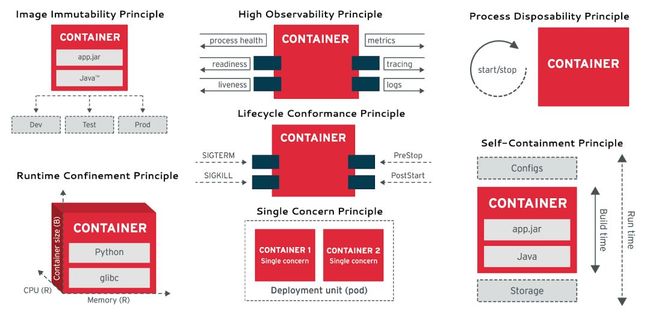
构建时(Build time)
-
Image Immutability Principle 镜像不变原则,同一个应用镜像可以分别部署在 Dev、Test、Pro 环境
Single Concern Principle 单一职责原则,每个容器都解决一个问题并做得很好,换句话说一个容器运行一个进程
Self-Containment Principle 自遏制原则,容器只依赖 Linux 内核,构建时添加其它库
运行时(Runtime)
-
High Observability Principle 高可预测性原则,每个容器都必须实现所有必要的 API,以帮助平台以最佳方式观察和管理应用程序
Lifecycle Conformance Principle 生命周期一致性原则,容器必须能够捕捉来自平台的事件,并对这些事件做出应对
Process Disposability Principle 进程可处理原则,容器随时可被替代
Runtime Confinement Principle 运行时限制原则,每个容器必须声明其资源限制(CPU、Memory 等)
与其说是设计原则,我更倾向于说是最佳实践,每一条原则都有对应 Kubernetes 的实践。强烈建议可以把前面提到的书好好阅读一遍,然后结合实际的业务调整实践。
相关链接:
https://github.com/kubernetes/kubernetes/issues/56903
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns/nodelocaldns
https://github.com/kubernetes/enhancements/blob/master/keps/sig-network/20190424-NodeLocalDNS-beta-proposal.md
https://tencentcloudcontainerteam.github.io/2018/10/26/DNS-5-seconds-delay/
https://blogs.oracle.com/java-platform-group/java-se-support-for-docker-cpu-and-memory-limits
https://www.oracle.com/technetwork/java/javase/8u191-relnotes-5032181.html#JDK-8146115
https://medium.com/adorsys/jvm-memory-settings-in-a-container-environment-64b0840e1d9e
https://github.com/kubernetes/kubernetes/issues/41938
https://blog.freshtracks.io/a-deep-dive-into-kubernetes-metrics-part-3-container-resource-metrics-361c5ee46e66
https://github.com/opskumu/issues/issues/23#issuecomment-547280434
原文链接:https://blog.opskumu.com/wacai-docker.html
扫描下方二维码关注公众号分布式实验室,回复『design』获取下载方式。
