Knowledge-Aware Graph-Enhanced GPT-2 for Dialogue State Tracking论文笔记
Knowledge-Aware Graph-Enhanced GPT-2 for Dialogue State Tracking
本文是英国英国剑桥大学工程系发表在EMNLP2021上面的论文
用于对话状态追踪的知识感知图形增强GPT-2
Abstract
对话状态追踪是对话系统的核心。
重点关注的问题是:
模型架构捕获的是序列生成对话状态时容易丢失的跨域下不同的域槽的关系和依赖。
目前生成DST中很好的基线GPT-2中存在一个问题,虽然GPT2可以做槽值预测的任务,但是由于其因果建模的情况,后面预测的槽值依赖于先前的槽值,但是当后面的槽值先被预测出来就不能推断出之前的槽值了,这样就会导致性能下降。
模型结构流程:使用Graph Attention NetWork得到的表示来增强GPT-2。允许模型对槽值进行因果顺序的判断
结果:报告了MUZ2.0中的性能,同时证明了图模型在DST 中确实能起到作用,
Introduction
本篇论文研究的是对话状态追踪的两个点:
(1)使用原自GAT编码的对话行为表示去增强GPT2,从而允许因果、顺序预测槽值,同时显示的建立 跨域的槽和值之间的关系
(2)使用GAT改进跨域槽共享值得预测。同时研究了弱监督的DST的训练方式。
提出一篇论文中提到的预定义域槽之间的存在三种类型的关系:
(1)共享相同候选槽值集的域槽


(2)域槽的候选槽值集是另一个域槽候选曹植集的子集。
(3)不同的域槽的槽值之间存在着相关性。
根据用户要定义的酒店的星级,可以确定价格的范围
以往的研究者们探索过使用GNN来捕获域槽和槽值之间的关系(但是没有深入的探索GNN如何利用他们之间的关系,即没有很好的分析GAT网络如何促进DST 的性能)
本文非常深入的分析了 GAT如何在GPT-2的非常优秀的基线上进行改进。
因为GPT2的因果建模,导致槽值生成时会产生先生成后面的槽值,这样会导致前面正确的槽值生成不出来,这就是GPT2在生成槽值上的限制,我们使用GAT使得GPT2提前获得域槽之间的关系,也就可以提前推理到生成槽值之间的因果顺序关系,生成时就不容易出错了。
模型如果可以提前捕获跨域槽值之间的关系,就不需要想MUZ数据集那样给每一回合的对话都详细的注释对话状态,只需要给一整轮对话注释对话状态,同时我们可以采用生成摘要对话状态的方式,这就使得我们训练数据的注释减少了很多,即弱监督训练。
此处论文也提到了,如果我们只使用一整轮的(会话级别)的注释来训练仍可以达到DST 的可接受的性能,那么创建DST 数据集将更加轻松,但是我们目前做的实验只是去利用数据集当中最后一回合的对话状态注释当做会话级别的注释来训练。
论文总体来说做出的贡献:
(1)提出一个混合架GAT结合GPT2,同时模型架构在弱监督的数据集中,模型的性能依旧稳健
(2)使用GAT解决GPT2中的因果推理的限制,解决DST的性能原因,论文中证明了GPT-2的因果推理生成槽值会影响DST的性能
(3)论文研究了模型如何捕捉域槽之间的关系 ,并分析了图改进互相依赖的曹植的域槽
模型虽然使用GPT优化了DST 的性能,同时还着重分析了模型是否改进了域槽值得预测
Graph Neural Networks
本文使用的是GAT网络
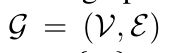
将每一轮对话的加权无向图公式如上
![]()
其中V是节点集,包含N个节点{vi},
![]()
表示的是边的集合,所有节点和节点之间连的边的集合。
![]()
表示的是N*N的二元对称邻接矩阵S

S中的每个位置的只有两个数1,或者0。1代表第i个节点和第j个节点之间有边,0表示的则相反。
![]()
每一个节点vi都有一个特征,F指的是特征长度。将这些所有节点的特征组成一个维度为N * F的矩阵大X

表示将每个图节点的特征传递给他的邻居节点


相当于与邻居进行K轮特征交换
对于GAT的每一层的输入是大X矩阵,维度是N * F。

上图是经过一GAT层之后的输出公式。


每一个GAT层使用的都是多头注意力机制,以上述这种方式使得每个节点有选择性的聚合邻居信息

论文中每个初试节点需要聚合邻居节点信息共L次,即一共有L层的GAT
Dialogue State Tracking with GPT-2 and Graph Neural Networks
论文中作者使用三个步骤,将GAT与GPY2融合在一起。
(1)使用GPT2编码对话历史和预定义实体当中所有的域槽和值
(2)将编码后的域槽和值的嵌入输入到GAT当中,让GAT经过几层的嵌入聚合
(3)将GAT更新后的嵌入输入到解码GPT2中

论文中的工作流程
①使用GPT2对对话历史和预定义实体中的所有域槽和域槽值进行编码,得到每个域槽和槽值的嵌入,NOTE:这里的域槽和槽值的嵌入包含了对话历史上下文的信息。
②得到域槽和槽值的嵌入之后传递到图注意力网络中,用于特征的聚合和信息交换,同时论文的实验中采用两种类型的图结构。
③将更新后的域槽特征被输入到相应的槽的因果生成中。红色标记是模型输入,带有蓝色的是生成的输出
Domain-Slot and Value Embedding
首先抽取预定义实体中所有的域槽和槽值的特征。
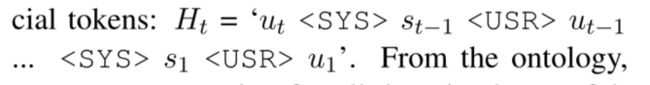
上述为对话历史的表示

上述为预定义实体当中的所有域槽槽值的连接表示,表示为F。F中包含了所有的域槽值,域槽和槽值的顺序确定,不随每个样本的变化而变化。
同时每个域槽钱都有一个简短的文本描述,作用为了GPT-2生成功能提供上下文。

在编码对话历史和域槽槽值时中间采用特殊token连接。输出域槽时,为了融入GAT输出的更新后的域槽嵌入,可以从输入时相应的位置处找到。
使用GPT2单独编码槽值,当槽值中包含多个词,将每个词的嵌入相加求平均。
![]()

编码所有的域槽之后的组成的矩阵
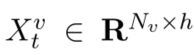
编码所有的槽值之后组成的矩阵
Nv和Ns分别指的是槽值的数量和域槽的数量
Inter-slot Information Exchange
域槽间信息交换
论文使用GAT捕捉域槽之间的信息,采用以下两种图结构:
![]()
每一个域槽作为图结构中的一个节点,每个节点之间都有连接(全连接)
![]()
域槽和槽值分别都作为图结构中的节点,将域槽和包含的槽值之间进行连接。
论文使用GAT 对图中的每个节点信息进行更新
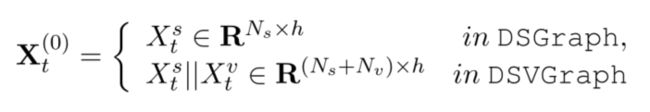
节点中的初始信息是由模型流程中的第一步抽取的嵌入。
经过GAT的操作过后,我们只使用域槽的嵌入如下:
![]()
Dialog State Prediction
在对话状态的生成中,我们先只输入对话历史和到GPT2中
之后GPT2再生成出对话状态的序列Yt如下:

训练模型生成每个域槽名和其相关的槽值,中间的是分割域槽值的特殊标签。
(这里生成的对话状态对所有的预定义实体中的域槽进行槽值填充,此时即有些域槽的槽值会为None)
在生成对话状态的时候,模型从来没有少预测一个域槽,可以证明GPT-2的结构化生成能力。
Decoding
在解码生成的过程中,我们要使用到GAT更新后的域槽嵌入
![]()
上述表示的是第i个域槽的GAT嵌入。
解码时按照输入时的顺序,一个一个给域槽填充曹植,比如当给第i个域槽填充曹植时,先输入第i个域槽的简单文本描述到GPT2中,得到嵌入,将其与第i个域槽再GAT中的嵌入信息拼接在一起。
当预测到与域槽无关的分界符号时连接的是全零的向量
Experiments
使用的是MUZ2.0数据集。使用的是Slot ACC、Joint Acc
Train Regimes
两种训练方式:

(1)密度监督训练任务,即每一轮对话话语都有对话状态的注释
(2)稀疏监督训练任务:只使用最后一轮的对话话语的对话状态作为当前一整轮的对话状态注释,训练模型,之前的对话话语当做对话历史
其中的GPT2和GAT联合训练,
测试评估时,使用的是test正常评估

L指的是GAT图网络跟心几层
P指的是GAT中的多头注意力机制,有几头
K指的是聚合节点信息时跨几层
Graph_Type指的是论文中提出的两个图结构
DST Performeance

可以看到本文提出的SOTA

此实验的目的是为了检测模型针对稀疏监督的训练方式的ACC,可以看到Acc最高。
在此实验中可以看到即使是在稀疏监督的情况下,GPT-2依然可以将模型维持在很好的性能之下。
可以看到当我们扩大GAT的层数(L)、GAT的多头数(P)、聚合信息的层数(K)可以更好的捕捉域槽和域槽值之间的关系。
可以看到当L、P不足时,我们可以使用DSV图结构和增加聚合信息层数,增加acc
有了足够多的 GAT 层,DSGraph 可以弥补显式值节点和匹配的不足,有时甚至优于 DSVGraph 的性能,但这是以增加建模复杂性为代价的
GATs captureinter-slotdependencies

此实验展示了多种模型在不同种域槽的精读展示。当引入不同的GAT 时曹准确率不同程度的上升
GATs improve the predictions at intermediate dialogue turns

展示了在使用最后一轮对话状态的注释数据训练的模型,当对话轮数的增多时,准确率在不断下降。