写在前面
想要做到JavaScript的代码优化,首先需要做的是准确的测试JavaScript的代码执行时间。其实需要做的就是采集大量的执行样本进行数学统计和分析,这里我们使用的是benchmark.js来检测代码的执行情况。
首先我们需要在项目中安装依赖,代码如下:
yarn add benchmark --save # 或者 npm i benchmark --save
然后我们写一个测试代码,如下所示:
const Benchmark = require('benchmark')
const suite = new Benchmark.Suite()
// 添加测试
suite
/**
* add() 方法接受两个参数,其中第一个表示测试的名称,第二个表示测试的内容,他是一个函数*
/
.add('join1000', () => {
new Array(1000).join(' ')
})
.add('join10000', () => {
new Array(10000).join(' ')
})
// 添加时间监听
.on('cycle', event => {
// 打印执行时间
console.log(String(event.target))
})
// 完成后执行触发的事件
.on('complete', () => {
console.log('最快的是:' + suite.filter('fastest').map('name'))
})
// 执行测试
.run({ async: true })
复制代码
代码执行结果如下:
// join1000 x 146,854 ops/sec ±1.86% (88 runs sampled)
// join10000 x 16,083 ops/sec ±1.06% (92 runs sampled)
// 最快的是:join1000
在结果中,ops/sec表示的是每秒执行的次数,当然是越大越好,紧接着是每秒执行次数上下相差的百分比,最后括号中的内容表示共取样多少次。
或者也可以使用JSBench.me工具进行替换,网站测试截图如下:
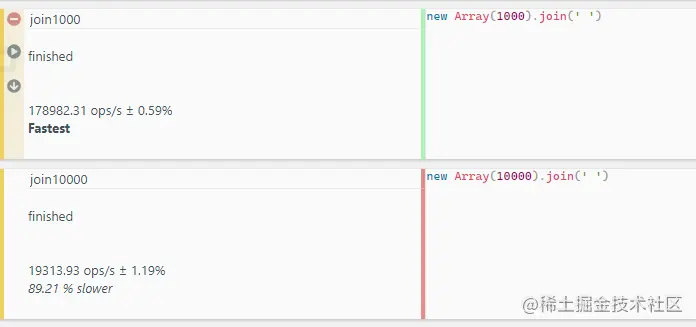
我们可以看到,都是join1000的性能更好一些(我感觉我在说废话)。
慎用全局变量
这里所说的慎用全局变量,为什么要慎用呢?主要有以下几点:
- 全局变量定义在全局执行上下文,是所有作用域链的顶端。每次查找的时候都从局部找到最顶端,在时间上会有所消耗。
- 全局执行上下文一直存在于上下文的执行栈,直到程序退出,才会被销毁,内存空间浪费 。
- 如果某个局部作用域出现了同名的变量则会遮盖或者说污染全局变量 。
下面我们就来写一段代码,看一下全局变量与布局变量在执行效率方面的差异,代码如下:
...
suite
.add('全局变量', () => {
// 该函数内模拟全局作用域
let i,
str = ''
for (i = 0; i < 1000; i++) {
str += i
}
})
.add('局部变量', () => {
for (let i = 0, str = ''; i < 1000; i++) {
str += i
}
})
...
代码运行结果如下:
全局变量 x 158,697 ops/sec ±1.05% (87 runs sampled)
局部变量 x 160,697 ops/sec ±1.03% (90 runs sampled)
最快的是:局部变量
虽然说差异不大,但是我们可以感知全局变量比局部的性能更差一些。
通过原型新增方法
为构造函数增加实例对象需要的方法时,尽量使用原型的方式添加,而不是构造函数内部进行添加,我们可以看如下测试代码:
...
suite
.add('构造函数内部添加', () => {
function Person() {
this.sayMe = function () {
return '一碗周'
}
}
let p = new Person()
})
.add('原型方式内部添加', () => {
function Person() {}
Person.prototype.sayMe = function () {
return '一碗周'
}
let p = new Person()
})
...
代码运行结果如下:
构造函数内部添加 x 573,786 ops/sec ±1.97% (89 runs sampled)
原型方式内部添加 x 581,693 ops/sec ±3.46% (80 runs sampled)
最快的是:构造函数内部添加
避免闭包中的内存泄露
由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,严重可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除 (即将局部变量重新赋值为null)。
避免使用属性访问方法
在JavaScript中的对象中,避免使用一些属性访问方法,这是因为JavaScript中的所有属性都是外部可见的。
示例代码如下:
...
suite
.add('使用属性访问方法', () => {
function Person() {
this.name = '一碗周'
this.getName = function () {
return '一碗周'
}
}
let p = new Person()
let n = p.getName()
})
.add('不使用属性访问方法', () => {
function Person() {
this.name = '一碗周'
}
let p = new Person()
let n = p.name
})
...
代码运行结果如下:
使用属性访问方法 x 406,682 ops/sec ±2.33% (82 runs sampled)
不使用属性访问方法 x 554,169 ops/sec ±2.03% (85 runs sampled)
最快的是:不使用属性访问方法
for循环优化
我们在使用for循环时,可以将有些必要的数据进行缓存,就比如arr.length这种属性,不需要每次判断都获取一下,从而优化我们的代码。
示例代码如下:
...
suite
.add('正序', () => {
let arr = new Array(100)
let str = ''
for (let i = 0; i < arr.length; i++) {
str += i
}
})
.add('缓存', () => {
let arr = new Array(100)
let str = ''
for (let i = arr.length; i; i--) {
str += i
}
})
.add('缓存的另一种写法', () => {
let arr = new Array(100)
let str = ''
for (let i = 0, l = arr.length; i < l; i++) {
str += i
}
})
...
代码运行结果如下:
正序 x 1,322,889 ops/sec ±1.36% (86 runs sampled)
缓存 x 1,356,696 ops/sec ±0.70% (92 runs sampled)
缓存的另一种写法 x 1,383,091 ops/sec ±0.70% (93 runs sampled)
最快的是:缓存的另一种写法
选择最优的循环方式
我们现在常用的循环有forEach、for和for...in循环,这几种那个是性能最优的呢,测试代码如下:
...
suite
.add('forEach', () => {
let arr = new Array(100)
let str = ''
arr.forEach(i => {
str += i
})
})
.add('for...in', () => {
let arr = new Array(100)
let str = ''
for (i in arr) {
str += i
}
})
.add('for', () => {
let arr = new Array(100)
let str = ''
for (let i = 0, l = arr.length; i < l; i++) {
str += i
}
})
...
代码运行结果如下:
forEach x 4,248,577 ops/sec ±0.89% (86 runs sampled)
for...in x 4,583,375 ops/sec ±1.15% (91 runs sampled)
for x 1,343,871 ops/sec ±1.91% (88 runs sampled)
最快的是:for...in
由运行结果可以看出我们可以尽量使用for...in或者forEach循环,减少使用for循环。
减少判断层级
减少判断层级就是减少一些if语句的嵌套,如果是一些必要的条件我们可以通过单层if结合return直接跳出函数的执行,关于优化前与优化后的代码执行比对如下所示:
...
/***
接收两类文件,zip 和 rar*
压缩包的大小限制为 10 兆*
/
suite
.add('嵌套写法', () => {
function uploadFile(suffix, size) {
// 允许上传的后缀名
const suffixList = ['.zip', '.rar']
const M = 1024* 1024
if (suffixList.includes(suffix)) {
if (size <= 10* M) {
return '下载成功'
}
}
}
uploadFile('.zip', 1* 1024* 1024)
})
.add('减少判断写法', () => {
function uploadFile(suffix, size) {
// 允许上传的后缀名
const suffixList = ['.zip', '.rar']
const M = 1024* 1024
if (!suffixList.includes(suffix)) return
if (size > 10* M) return
return '下载成功'
}
uploadFile('.zip', 1* 1024* 1024)
})
...
代码运行结果如下:
嵌套写法 x 888,445,014 ops/sec ±2.48% (88 runs sampled)
减少判断写法 x 905,763,884 ops/sec ±1.35% (92 runs sampled)
最快的是:减少判断写法,嵌套写法
虽然说差距并不是很大,但是不适用嵌套的代码比普通代码更优一些。
减少作用域链查找层级
减少代码中作用域链的查找也是代码优化的一种方法,如下代码展示了两者的区别:
...
suite
.add('before', () => {
var name = '一碗粥'
function sayMe() {
name = '一碗周'
function print() {
var age = 18
return name + age
}
print()
}
sayMe()
})
.add('after', () => {
var name = '一碗粥'
function sayMe() {
var name = '一碗周' // 形成局部作用域
function print() {
var age = 18
return name + age
}
print()
}
sayMe()
})
...
代码运行结果如下:
before x 15,509,793 ops/sec ±7.78% (76 runs sampled)
after x 17,930,066 ops/sec ±2.89% (83 runs sampled)
最快的是:after
上面代码只是为了展示区别,并没有实际意义。
减少数据读取次数
如果对象中的某个数据在一个代码块中使用两遍以上,这样的话将其进行缓存从而减少数据的读取次数来达到更优的一个性能,
测试代码如下:
...
var userList = {
one: {
name: '一碗周',
age: 18,
},
two: {
name: '一碗粥',
age: 18,
},
}
suite
.add('before', () => {
function returnOneInfo() {
userList.one.info = userList.one.name + userList.one.age
}
returnOneInfo()
})
.add('after', () => {
function returnOneInfo() {
let one = userList.one
one.info = one.name + one.age
}
returnOneInfo()
})
...
代码运行结果如下:
before x 222,553,199 ops/sec ±16.63% (26 runs sampled)
after x 177,894,903 ops/sec ±1.85% (88 runs sampled)
最快的是:before
字面量与构造式
凡是可以使用字面量方式声明的内容,绝对是不可以使用构造函数的方式声明的,两者在性能方面相差甚远,代码如下:
...
suite
.add('before', () => {
var str = new String('string')
})
.add('after', () => {
var str = 'string'
})
...
代码运行结果如下:
before x 38,601,223 ops/sec ±1.16% (89 runs sampled)
after x 897,491,903 ops/sec ±0.92% (92 runs sampled)
最快的是:after
到此这篇关于总结分享10个JavaScript代码优化小tips的文章就介绍到这了,更多相关JavaScript优化tips内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!