爬虫基本原理介绍、实现以及问题解决
文章目录
- 一、爬虫的意义
-
- 1.前言
- 2.爬虫能做什么
- 3.爬虫有什么意义
- 二、爬虫的实现
-
- 1.爬虫的基础原理
- 2.api的获取
- 3.爬虫实现
- 三、反爬解决方案
-
- 1.反爬的实现方式
- 2.反爬的解决方法
- 3.反爬的实现代码
- 4.IPIDEA还能做什么
- 四、总结

一、爬虫的意义
1.前言
最近拉开了毕业季的序幕,提前批开启了大厂抢人模式,所以很多人都开始在力扣刷题, 希望能够在大厂抢人的时期脱颖而出。为了能实现群内力扣刷题排名就需要对力扣网站进行数据爬取,最近就对爬虫的机制和爬虫的意义进行了了解。
2.爬虫能做什么
其实爬虫的主要目标就是通过大量自动化进行目标网站的访问,获取公开的数据,方便我们进行数据 统计或者数据整合。其中公开shuju一定要注意,就是一定是网页可以公开访问的数据进行访问,否则是违法的哦,容易面向监狱编程。另外就是一定要注意访问的频次,不能对原始网站造成危害(一般都会做限制了)。不然会变成一只有毒的爬虫。
3.爬虫有什么意义
其实爬虫主要做的事情就是数据的收集,接下来就可以做数据的处理,企业可以用这些数据来进行市场分析,把握商机,就行买股票一样,有大量的历史数据我们就可以尝试去预测市场走势,押中了就是一次机会。
另外现在人工智能这么火爆,但是人工智能的基础就是大数据,我们听说过训练集其实就是大数据,我们有时候拿不到现成的数据集的时候就需要进行爬虫拿到我们的数据基础。

二、爬虫的实现
1.爬虫的基础原理
爬虫其实就是自动访问相应的网站,拿到我们想要的数据。比如我们想要查快递,就会不断的访问一个网页,去看最新的进度,爬虫就是去模拟这个过程,同时为了提高效率可能会省略一些步骤。我们这次就以力扣的刷题总数做例子。
2.api的获取
我们打开力扣的主页的时候一定会进行数据的访问拿到一些信息,我们打开开发者模式,就可以看到每一条请求。例如下图:
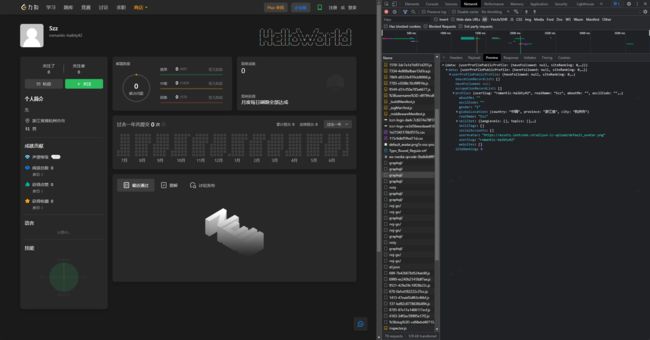
右侧就是我的主页其中的一条数据库请求内容,他用的语法是graphql,赶兴趣我们下次再讲,我们只要用就行了。
我们其实可以对请求头进行精简,得到下面的graphql语法:
payload = {"operation_name": "userPublicProfile", #查询数据库请求内容
"query": '''query userPublicProfile($userSlug: String!) {
userProfilePublicProfile(userSlug: $userSlug) {
username
submissionProgress {
acTotal
}
}
}
''',
"variables": '{"userSlug":"查询对象"}'
}
3.爬虫实现
我们直接对上面构造的访问方式进行访问,看看得到了什么:
import requests as rq
from urllib.parse import urlencode
headers={ #请求头信息
"Referer":"https://leetcode.cn",
}
payload = {"operation_name": "userPublicProfile", #查询数据库请求内容
"query": '''query userPublicProfile($userSlug: String!) {
userProfilePublicProfile(userSlug: $userSlug) {
username
submissionProgress {
acTotal
}
}
}
''',
"variables": '{"userSlug":"romantic-haibty42"}'
}
res = rq.post("https://leetcode.cn/graphql/"+"?"+ urlencode(payload),headers = headers)
print(res.text)

可以从上面的发现我们拿到了acTotal字段,也就是我们想要总的刷题数。但是我们尝试对大量数据进行访问的时候我们就会看到访问频次的限制。
三、反爬解决方案
1.反爬的实现方式
很多网站常用的一种反爬的方式是对单ip进行限制,如果一个ip在一定的时间内大量访问,那么就会不再返回信息,而是返回错误。主要是数据库的日志系统会对访问进行记录。
2.反爬的解决方法

Ipidea是一个IP代理平台,为全球用户提供优质大数据代理服务,目前拥有千万级真实住宅IP资源,包含超过220个国家和地区,日更新超过4000万,汇聚成代理服务池并提供API接入,支持http、https、socks5等多种协议类型,并且拥有API形式和账号密码多种使用方式,非常易于上手。官网地址
3.反爬的实现代码
其实我们有了上面的代码之后再加入到ipidea就会很简单,只要我们去官网下示例代码,然后插入我们的代码就行了:
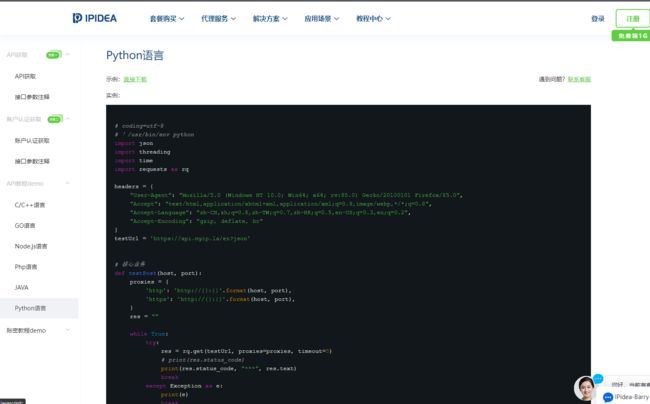
只要我们将代码中的tiqu换成我们的提取链接,然后将我们的代码放到核心业务的try里面就可以实现了。
不过我为了使用socks5代理方式进行了修改,完整版代码如下:
# coding=utf-8
# !/usr/bin/env python
import json
import threading
import time
import requests as rq
from urllib.parse import urlencode
headers={
"Referer":"https://leetcode.cn",
}
payload = {"operation_name": "userPublicProfile",
"query": '''query userPublicProfile($userSlug: String!) {
userProfilePublicProfile(userSlug: $userSlug) {
username
submissionProgress {
acTotal
}
}
}
''',
"variables": '{"userSlug":"kingley"}'
}
username = "romantic-haibty42"
def int_csrf(proxies,header):
sess= rq.session()
sess.proxies = proxies
sess.head("https://leetcode.cn/graphql/")
header['x-csrftoken'] = sess.cookies["csrftoken"]
testUrl = 'https://api.myip.la/en?json'
# 核心业务
def testPost(host, port):
proxies = {
'http': 'socks5://{}:{}'.format(host, port),
'https': 'socks5://{}:{}'.format(host, port),
}
res = ""
while True:
try:
header = headers
# print(res.status_code)
chaxun = payload
chaxun['variables'] = json.dumps({"userSlug" : f"{username}"})
res = rq.post("https://leetcode.cn/graphql/"+"?"+ urlencode(chaxun),headers = header,proxies=proxies)
print(host,res.text)
except Exception as e:
print(e)
break
class ThreadFactory(threading.Thread):
def __init__(self, host, port):
threading.Thread.__init__(self)
self.host = host
self.port = port
def run(self):
testPost(self.host, self.port)
# 提取代理的链接 json类型的返回值 socks5方式
tiqu = ''
while 1 == 1:
# 每次提取10个,放入线程中
resp = rq.get(url=tiqu, timeout=5)
try:
if resp.status_code == 200:
dataBean = json.loads(resp.text)
else:
print("获取失败")
time.sleep(1)
continue
except ValueError:
print("获取失败")
time.sleep(1)
continue
else:
# 解析json数组
print("code=", dataBean)
code = dataBean["code"]
if code == 0:
threads = []
for proxy in dataBean["data"]:
threads.append(ThreadFactory(proxy["ip"], proxy["port"]))
for t in threads: # 开启线程
t.start()
time.sleep(0.01)
for t in threads: # 阻塞线程
t.join()
# break
break
实现结果如下:

短时间大量访问也不会进行限制啦。
4.IPIDEA还能做什么

全局动态住宅代理
动态代理覆盖全球240+国家地区,且均为真实的家庭住宅ip,这意味着请求的成功率更好,且数据的真实性更高。
多种调用方式
支持api接口调用、账号密码调用以及插件代理,使我们的应用成本大大降低。
定制使用时效
出口IP时效可以自己设置,或者每次进行更换,可以让我们使用更加灵活。
高匿隧道
隧道中转,支持高并发,不同端口的出口为不同的ip,自动切换,让我们的信息更加安全。
完善文档支持
对于不同语言都有对应的实例文档,方便我们快速上手。

四、总结
今天我们讲了爬虫的基础知识,还能拿到力扣的刷题数据,甚至我们还利用IPIDEA逃脱了力扣的访问限制。大家快动动手指尝试一下吧。相信大家都能掌握爬虫的基本实现方式,不过要注意要注意文明的爬虫哦。
另外,相信有着安全保护等等多种功能的IPIDEA一定会对企业有很大的意义,如果你企业有这方面的烦恼,不妨试试这款神器,限制注册就送1G流量哦。官网地址
赠送书籍:《架构基础》
赠送数量:5
赠送规则:本文三连并分享
进抽奖群:加臻哥福利小助手进群( szzdzhp002 ) 回复暗号:19
本书不涉及任何具体的编程语言,采用大量的架构图、流程图、状态图、时序图等来图解企业级架构,更加清晰直观。每个章节都以场景化案例进行剖析,从需求、问题、解决方案、原理、设计方法、落地方案等多个角度,给出架构设计方法。可以根据本书目录查找对应的场景设计,参考应用在企业系统建设中。以阿里云 / 腾讯云消息系统、支付宝 / 微信支付系统、鹰眼业务监控系统、监管批量信息报送系统作为实战案例,详细讲解架构设计过程,对核心功能、设计、数据结构加以分析,巩固读者的架构思维和设计能力
