C++入门基础(上篇)
这里写目录标题
- 1.C++关键字
- 2.命名空间
-
- 2.1命名空间定义
- 2.2命名空间的使用方法
- 3.C++输入&输出
- 4.缺省参数
-
- 4.1缺省参数的概念
- 4.2缺省参数分类
- 5.函数重载
-
- 5.1函数重载的概念
- 5.2为什么C++支持函数重载,而C语言不支持函数重载呢?
- 5.3extern "C"
1.C++关键字
我们知道C语言总共有32个关键字,C++98又新增了31个关键字,所有C++总共有63个关键字,C++11标准又新增到了80多个,不需要立马把它们背下来,后面用到了再去了解。
2.命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突(在相同的作用域下声明相同名字的变量和函数,编译器会报错)。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
为什么我们会在同一个作用域中声明相同的变量或者函数呢?
因为如果一个工程项目很大,往往会拆解成许多部分,每个程序员负责的部分可能不相同,如果恰好两个程序员要实现一个相同的或者不同的函数的功能,他们可能会给这个函数起了一样的名字,最后项目整合的时候可能会导致函数重名。
2.1命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员
1.普通的命名空间
namespace lc // N1为命名空间的名称
{
// 命名空间中的内容,既可以定义变量,也可以定义函数
int a;
int Add(int left, int right)
{
return left + right;
}
}
2.嵌套的命名空间
namespace lc
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace a1
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
3. 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中
namespace lc
{
int a;
int Add(int left, int right)
{
return left + right;
}
}
namespace lc
{
int Mul(int left, int right)
{
return left * right;
}
}
一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
2.2命名空间的使用方法
C++为了防止命名冲突,把自己库里面的东西都定义在一个std的命名空间中
1.使用命名空间的名称+作用域限定符
namespace lc
{
int a = 10;
int b = 20;
}
int main()
{
printf("%d\n", lc::a);
return 0;
}
虽然麻烦,每个地方都要指定,但这是最规范的方式
2.使用using将命名空间中成员引入
namespace lc
{
int a = 10;
int b = 20;
}
//相当于把命名空间lc中的变量a展开到全局
using lc::a;
int main()
{
printf("%d\n", a);
return 0;
}
3.使用using namespace命名空间名称引入
namespace lc
{
int a = 10;
int b = 20;
}
//相当于把命名空间lc中的所有变量展开到全局
using namespace lc;
int main()
{
printf("%d\n", a);
return 0;
}
看起来很方便,但我们要防止自己定义的变量和这个命名空间中变量冲突
3.C++输入&输出
我们已经会使用C语言输入和输出内容了,那C++怎么输入输出内容呢?
#include<iostream>
using namespace std;
int main()
{
int a;
double b;
char c;
cin>>a>>b;
cout<<a<<" "<<b<<endl;
cout<<"Hello world!!!"<<endl;
return 0;
}
说明:
1.使用cout标准输出(控制台)和cin标准输入(键盘)时,必须包含< iostream >头文件以及std标准命名空间。
2.使用C++输入输出更方便,C语言输入输出会考虑数据类型,但是C++不会考虑数据类型
4.缺省参数
4.1缺省参数的概念
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函时,如果没有指定实参则采用该默认值,否则使用指定的实参.

4.2缺省参数分类
缺省参数又分为全缺省参数和半缺省参数
1.全缺省参数
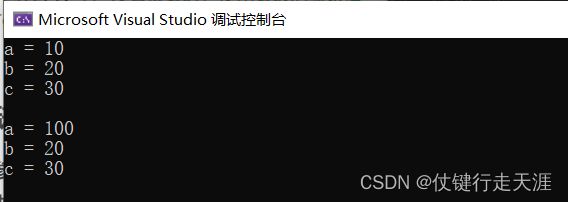
void Testc(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
cout << endl;
}
int main()
{
Testc();
Testc(100);
}
输出
2.半缺省参数
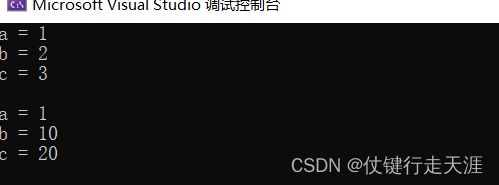
void Testc(int a, int b = 10, int c = 20)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
cout << endl;
}
int main()
{
Testc(1,2,3);
Testc(1);
}
输出
注意:
1.半缺省参数必须从右往左依次来给出,不能间隔着给,必须是连续的。
2. 缺省参数不能在函数声明和定义中同时出现。
3. 缺省值必须是常量或者全局变量。
4. C语言不支持缺省参数。
*第二点我再解释一下:声明给,定义不给是可以的,但是声明不给,定义给不可以,因为编译器编译的时候看函数声明,链接的时候才看定义。所以一般缺省参数实在声明的时候给出,定义的时候不给。
5.函数重载
5.1函数重载的概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,返回类型相不相同无所谓,常用来处理实现功能类似数据类型不同的问题。
下面这三个函数属于函数重载
int Add(int left, int right)
{
return left + right;
}
double Add(double left, double right)
{
return left + right;
}
long Add(int left, int right, int mid)
{
return left + right;
}
下面这两个函数不属于函数重载
short Add(short left, short right)
{
return left+right;
}
int Add(short left, short right)
{
return left+right;
}
这两个函数也不属于函数重载
void Func(int a = 10)
{}
void Func(int a)
{}
5.2为什么C++支持函数重载,而C语言不支持函数重载呢?
在C/C++中,一个程序要运行起来,需要经过一下几个阶段:预处理、编译、汇编、链接


1.实际我们的项目通常是由多个源文件构成,假设有两个名为a.cpp和b.cpp文件,其中a.cpp中调用了b.cpp中定义的Add函数,编译后链接前,a.cpp文件变成了a.o的目标文件中,a.o的目标文件中没有Add的函数地址,因为Add是在b.cpp中定义的,Add的地址在b.o中,怎么办?
2.链接器看到a.o调用Add,但是没有Add的地址,就会到b.o的符号表中找Add的地址,然后链接到一起。
3.那么链接时,面对Add函数,链接器会使用哪个名字去找呢?每个编译器都有自己的函数名修饰规则。
4.由于Windows下vs的修饰规则过于复杂,而Linux下gcc的修饰规则简单易懂,下面我使用了gcc演示了这个修饰后的名字。
采用C语言编译器编译后结果
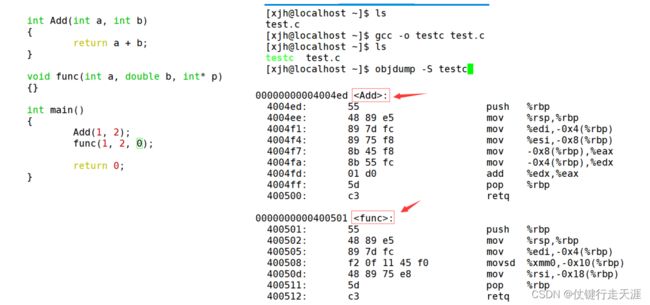
采用C++编译器编译后结果
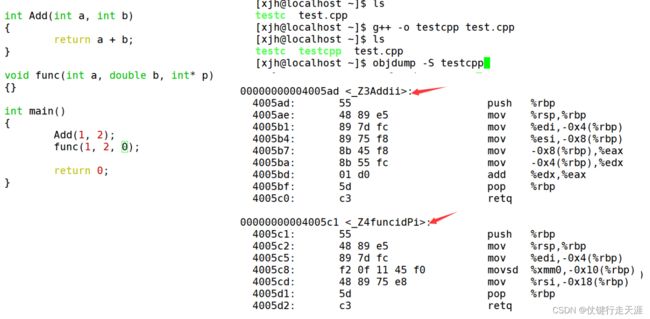
通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度+函数名+类型首字母,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。所以函数重载必须要求参数不同,和返回值没有关系,缺省参数的函数之间也不构成重载函数。
所以C语言没办法支持重载,因为同名函数没办法区分,而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。
5.3extern “C”
有时候在C++工程中可能需要将某些函数按照C的风格来编译,在函数前加extern “C”,意思是告诉编译器,将该函数按照C语言规则来编译。比如:tcmalloc是google用C++实现的一个项目,他提供tcmallc()和tcfree两个接口来使用,但如果是C项目就没办法使用,那么他就使用extern “C”来解决。
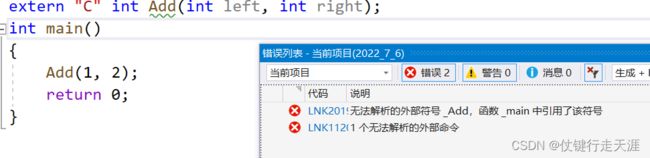
加上extern “C"会告诉编译器这个函数将按照C的风格来编译,add在转化到符号表中后为_Add 而非 _Z3Addii,C++程序不能调用这个函数。