Hadoop存储——HDFS
文章目录
-
- Hadoop存储——HDFS
- 1、HDFS架构
-
- (1)名称节点(NameNode)
- (2)数据节点(DataNode)
- (3)第二名称节点(Secondary NameNode)
- 2、HDFS文件上传
- 3、MapReduce过程可以解析为如下所示:
- 4. MapReduce组件分析与编程实践
-
- 4.1.Combiner分析
- 4.2.Partitioner分析
- 4.3.输入输出格式/键值类型
-
- 4.3.1 输入格式(InputFormat)
- 4.3.2输出格式(OutputFormat)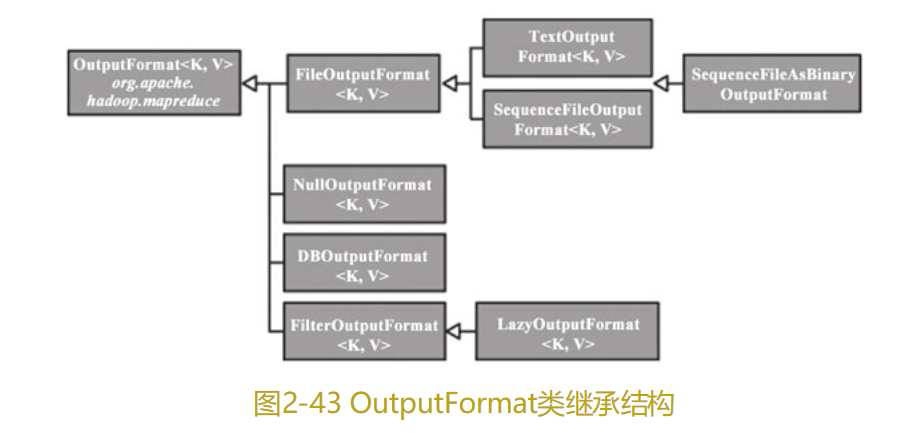
- 4.3.3 Hadoop中常用的键值对类型
-
- 4.3.3.1 值得注意
- 5、K-Means算法原理及Hadoop MapReduce实现
-
- 5.1 K-Means算法原理
Hadoop存储——HDFS
Hadoop的存储系统是HDFS(Hadoop Distributed File System)分布式文件系统,对外部客户端而言,HDFS就像一个传统的分级文件系统,可以进行创建、删除、移动或重命名文件或文件夹等操作,与Linux文件系统类似。
1、HDFS架构

关于各个组件的具体描述如下所示:
名称节点(NameNode,仅一个),它在HDFS内部提供元数据服务;第二名称节点(Secondary NameNode),名称节点的帮助节点,主要是为了整合元数据操作(注意不是名称节点的备份);数据节点(DataNode),它为HDFS提供存储块
(1)名称节点(NameNode)
它是一个通常在HDFS架构中单独机器上运行的组件,负责管理文件系统名称空间和控制外部客户机的访问。 NameNode决定是否将文件映射到DataNode上的复制块上。对于最常见的3个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。
(2)数据节点(DataNode)
数据节点也是一个通常在HDFS架构中的单独机器上运行的组件。Hadoop集群包含一个NameNode和大量DataNode。数据节点通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。数据节点响应来自HDFS客户机的读写请求。它们还响应来自NameNode的创建、删除和复制块的命令。名称节点依赖来自每个数据节点的定期心跳(heartbeat)消息。每条消息都包含一个块报告,名称节点可以根据这个报告验证块映射和其他文件系统元数据。如果数据节点不能发送心跳消息,名称节点将采取修复措施,重新复制在该节点上丢失的块。
(3)第二名称节点(Secondary NameNode)
第二名称节点的作用在于为HDFS中的名称节点提供一个Checkpoint,它只是名称节点的一个助手节点,这也是它在社区内被认为是Checkpoint Node的原因。
Secondary NameNode会定时到NameNode去获取名称节点的edits,并及时更新到自己fsimage上。这样,如果NameNode宕机,我们也可以使用SecondaryNamenode的信息来恢复NameNode。并且,如果SecondaryNameNode新的fsimage文件达到一定阈值,它就会将其拷贝回名称节点上,这样NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
下图是Secondary NameNode运行机制

2、HDFS文件上传

文件在客户端时会被分块,这里可以看到文件被分为5个块,分别是:A、B、C、D、E。同时为了负载均衡,所以每个节点有3个块。下面来看看具体步骤:
1)客户端将要上传的文件按128MB的大小分块。
2)客户端向名称节点发送写数据请求。
3)名称节点记录各个DataNode信息,并返回可用的DataNode列表。
4)客户端直接向DataNode发送分割后的文件块,发送过程以流式写入。
5)写入完成后,DataNode向NameNode发送消息,更新元数据。
3、MapReduce过程可以解析为如下所示:
1)文件在HDFS上被分块存储,DataNode存储实际的块。
2)在Map阶段,针对每个文件块建立一个map任务,map任务直接运行在DataNode上,即移动计算,而非数据,如图2-30所示。

图2-30 数据块和map对应关系
3)每个map任务处理自己的文件块,然后输出新的键值对,如图2-31所示。

图2-31 键值对经过map处理后输出
4)Map输出的键值对经过shuffle/sort阶段后,相同key的记录会被输送到同一个reducer中,同时键是排序的,值被放入一个列表中,如图2-32所示。

图2-32 shuffle/sort和reduce阶段
5)每个reducer处理从map输送过来的键值对,然后输出新的键值对,一般输出到HDFS上。
4. MapReduce组件分析与编程实践
4.1.Combiner分析
对于多个输入数据块,每个数据块产生一个InputSplit,每个InputSplit对应一个map任务,每个map任务会对应0个到多个Combiner,最后再汇总到Reducer。在单词计数的例子中,使用Combiner的情形如图2-41所示。

需要注意的是,自定义Combiner也是需要集成Reducer的,同样也需要在reduce函数中写入处理逻辑。但是要注意,Combiner的输入键值对格式与输出键值对格式必须保持一致,也正是因为这个要求,很多情况下,采用自定义Combiner的方式在业务或算法处理上行不通。还有,在单词计数程序中,Combiner和Reducer使用的是同一个类代码,这是可能的,但是大多数情况下不能这样做,因为Reducer和Combiner的逻辑在很多情况下是不一样的。
4.2.Partitioner分析
Redure个数在初始化Job实例的时候进行设置,例如设置代码为job.setNumReduceTasks(3),这样就可以设置3个Reducer了。
Hadoop系统默认的Partitioner是HashPartitioner。
4.3.输入输出格式/键值类型
一般来说,HDFS一个文件对应多个文件块,每个文件块对应一个InputSplit,而一个InputSplit就对应一个Mapper任务,每个Mapper任务在一个节点上运行,其仅处理当前文件块的数据。
在InputFormat中定义了如何分割以及如何进行数据读取从而得到键值对的实现方式,它有一个子类FileInputFormat,如果要自定义输入格式,一般都会集成它的子类FileInputFormat,它里面帮我们实现了很多基本的操作,比如记录跨文件块的处理等。
4.3.1 输入格式(InputFormat)


4.3.2输出格式(OutputFormat)

4.3.3 Hadoop中常用的键值对类型

4.3.3.1 值得注意
1)值类型都需实现Writale接口;
2)键需要实现WritableComparable接口。
5、K-Means算法原理及Hadoop MapReduce实现
5.1 K-Means算法原理
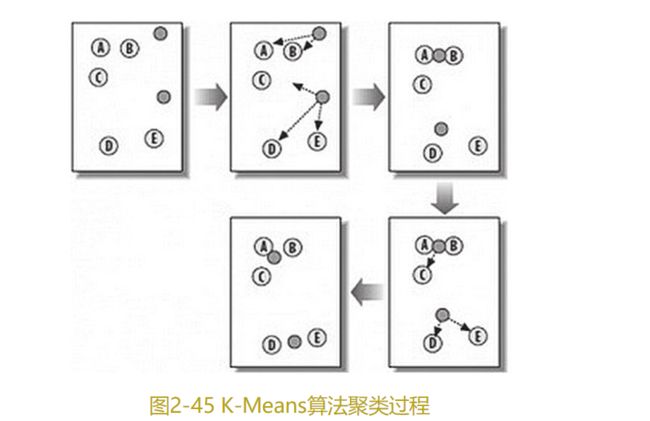
K-Means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表。它是将数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则(如图2-45所示)。K-Means算法以欧氏距离作为相似度测度,求对应某一初始聚类中心向量V最优分类,使得评价指标最小。算法采用误差平方和准则函数作为聚类准则函数。