MapReduce shuffle过程详解!
目录
-
- 一、MR的shuffle过程
- 二、Map shuffle
- 三、Reduce shuffle
- 四、MapReduce shuffle阶段配置详解
-
- (1)Combiner配置详解
-
- (1)Combiner概述
- (2)Combiner案例
- (2)MR的数据压缩
-
- (1)数据压缩概述
- (2)常见压缩算法比较
- (3)compress设定方式
- (3)如何设置reduce数量
- 四、MapReduce的调优
- 五、完善MR的编程模板
一、MR的shuffle过程
MR的shuffle过程:
input -> map -> shuffle -> reduce ->output
MR的原理图:

二、Map shuffle

1.map()的数据会写入到内存(环形缓冲区:默认大小:100mb),当数据达到缓冲区总容量的80%(阈值)时,会将我们的数据spill到本地磁盘
- 1)分区(partitioner):分区决定map输出的数据将会被哪个reduce任务进行处理
- 2)排序:会对我们分区中的数据进行排序
- 3)spill写磁盘:将内存中的数据写入到本地磁盘(hadoop.tmp.dir)
2.当Map阶段数据处理完成之后,我们会将spill到磁盘的数据进行一次合并
- 1)将各个分区的数据合并在一起
- 2)分区合并之后再次排序
eg:
file -1(分区1 + 分区2)
file -2(分区1 + 分区2)
file -3(分区1 + 分区2)
合并成一个文件:
allFile(合并分区1 + 合并分区2)
最后会形成一个文件,待reduce任务获取
map shuffle总结成自己话:当map以
三、Reduce shuffle
1.当map阶段数据处理完成之后,各个reduce 任务主动到已经完成的map 任务的本次磁盘中,去拉取属于自己要处理的数据,最后会形成一个文件
- 1)reduce对应partition的数据写入内存,根据reduce端数据内存的阈值,spill到reduce本地磁盘,形成一个个小文件
- 2)对文件进行合并
- 3)排序
- 4)分组(将相同key的value放在一起)
<hadoop,1>
<hadoop,1> -> <hadoop,List(1,1,1)>
<hadoop,1>
<spark,1>
<spark,1>
- 5)reduce()
reduce shuffle总结成自己话:当map阶段数据处理完成之后,各个reduce任务主动到已经完成的map 任务的本次磁盘中,去拉取属于自己要处理的数据,最后会形成一个文件,reduce 对应partition的数据写入内存,根据reduce端数据内存的阈值,spill到reduce本地磁盘,形成一个个小文件,然后对一个个小文件进行合并,排序,分组(将相同key的value放在一起),最后形成reduce输入端,传递给reduce()函数,得出结果。
四、MapReduce shuffle阶段配置详解
//1.分区
job.setPartitionerClass();
//2.排序
job.setSortComparatorClass();
//3.combiner -可选项
//combiner其实就是map端reduce
job.setCombinerClass(WordCountCombiner.class);
//4.compress -可配置
//5.分组
job.setGroupingComparatorClass();
(1)Combiner配置详解
(1)Combiner概述
·Mapreduce中的mapper阶段将输入的数据转换成一个个键值对的形式
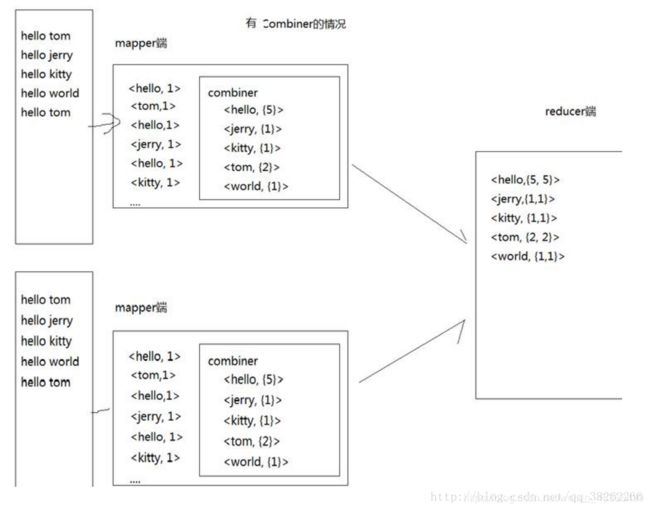
combiner本质就是map端reduce:我们可以把合并(combiner)看作是一个在每个单独节点上先做一次Reduce的操作,其输入及输出的参数和Reduce是一样的。
(2)Combiner案例
以wordcount为例,对比有和没有Combiner的差异:
若要引入Combiner,则只需要在wordcount程序的main方法中,增加下面的语句即可:
//combiner其实就是map端reduce
job.setCombinerClass(WordCountCombiner.class);
Combiner虽好,但并不是所有的案例都适合用combiner,只有操作满足结合律的才可设置combiner。比如求平均值的场景:

接下来看一个wordcount的combiner的案例:
1.输入文件内容:
java python hadoop
spark spark java hadoop
hive hbase hbase hive
spark java python hadoop
linux unix java python
spark spark storm flink
java flink hue kafka kafka
java python zookeeper zookeeper
spark hive hbase hive
2.先运行之前没有设置Combiner的Wordcount案例,观察控制台显示的信息:

在我们没有启用Combiner之前,关于Combiner的计数器都为0,查看这个时候的mapper阶段的计数器和reducer阶段的计数器为10和37。
3.需求分析
统计过程中对每一个MapTask的输出进行局部汇总,以减小网络传输量即采用Combiner功能。
4.实现过程
package com.kfk.hadoop.mr;
import com.google.common.collect.Lists;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.List;
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/10/9
* @time : 7:07 下午
*/
public class WordCountUpMRC extends Configured implements Tool {
/**
* map
*/
public static class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
// 创建k2,v2对象
private final Text mapOutputKey = new Text();
private final IntWritable mapOutputValue = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 输出,k1就是偏移量,v1就是一行行数据
System.out.println("Map in == KeyIn: "+key+" ValueIn: "+value);
// 每一行数据
String lineValue = value.toString();
// 将数据按照空格分开
String[] strs = lineValue.split(" ");
// 输出5.查看运行结果:
map输出:

combiner输出:
reduce输出:

再次查看控制台显示的信息:

在我们启用Combiner之后,关于Combiner的计数器为37和14,reduce的计数器为14,对这个结果分析一下,因为输入文件没有变化,所以mapper的计数器没有变化,因为输入文件小于128M,所以只会启用一个map task。
小结:
在实际的Hadoop集群操作中,我们是由多台主机一起进行MapReduce的,如果加入合并操作,每一台主机会在reduce之前进行一次对本机数据的合并,然后在通过集群进行reduce操作,这样就会大大节省reduce的时间,从而加快MapReduce的处理速度。
(2)MR的数据压缩
(1)数据压缩概述
数据压缩这是mapreduce的一种优化策略:通过压缩编码对mapper或者reducer的输出进行压缩,以减少磁盘IO,提高MR程序运行速度(但相应增加了cpu运算负担)
- Mapreduce支持将map输出的结果或者reduce输出的结果进行压缩,以减少网络IO或最终输出数据的体积
- 压缩特性运用得当能提高性能,但运用不当也可能降低性能
- 压缩使用基本原则:(1)运算密集型的job,少用压缩 (2)IO密集型的job,多用压缩
(2)常见压缩算法比较
1.gzip压缩:
优点:压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split。
2.lzo压缩:
优点:压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便。
缺点:压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)。
3.snappy压缩:
优点:压缩速度快;支持hadoop native库。
缺点:不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令。
4.bzip2压缩:
优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
(3)compress设定方式
MR数据 处理过程中,compress如何设定,有两种方式:
第一种:configuration
// compress -可配置
configuration.set("mapreduce.map.output.compress","true");
// 使用的SnappyCodec压缩算法
configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
第二种:mapred-site.xml
#支持压缩
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
#压缩方式
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
(3)如何设置reduce数量
在缺省情况下,一个mapreduce的job只有一个reducer;在大型集群中,需要使用许多reducer,中间数据都会放到一个reducer中处理,如果reducer数量不够,会成为计算瓶颈。
// 6.设置reduce的数量为2
job.setNumReduceTasks(2);
查看partition分区

一个分区对应一个reducer。
四、MapReduce的调优
1.Reduce Task Number(设定reduce的数量)
- 根据业务需求
- 测试
2.Map task 输出压缩
3.shuffle数据处理过程中的参数
- mapreduce.task.io.sort.mb:配置环形缓冲区大小(默认100MB)
- mapreduce.map.sort.spill.percent:配置达到的百分比(默认是80%开始spill磁盘)
- mapreduce.task.io.sort.factor:配置分区合并文件的数量(默认是10)
- mapreduce.map.cpu.vcores:配置CPU核数(默认是1)
- mapreduce.reduce.cpu.vcores:配置CPU核数(默认是1)
- mapreduce.map.memory.mb:配置内存大小(默认是1024MB)
- mapreduce.reduce.memory.mb:配置内存大小(默认是1024MB)
五、完善MR的编程模板
根据wordcount编程,我们可以整理出一套MR的编程模板,根据需求套用模版即可:
package com.kfk.hadoop.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/10/9
* @time : 7:07 下午
*/
public class MRTemplate extends Configured implements Tool {
/**
* map
* TODO
*/
public static class TemplateMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
@Override
public void setup(Context context) throws IOException, InterruptedException {
// TODO
}
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// TODO
}
@Override
public void cleanup(Context context) throws IOException, InterruptedException {
// TODO
}
}
/**
* reduce
* TODO
*/
public static class TemplateReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
public void setup(Context context) throws IOException, InterruptedException {
// TODO
}
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// TODO
}
@Override
public void cleanup(Context context) throws IOException, InterruptedException {
// TODO
}
}
/**
* run
* @param args
* @return
* @throws IOException
* @throws ClassNotFoundException
* @throws InterruptedException
*/
public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1) get conf
Configuration configuration = this.getConf();
// 2) create job
Job job = Job.getInstance(configuration,this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
// 3.1) input,指定job的输入
Path path = new Path(args[0]);
FileInputFormat.addInputPath(job,path);
// 3.2) map,指定job的mapper和输出的类型
job.setMapperClass(TemplateMapper.class);
//TODO
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 1.分区
// job.setPartitionerClass();
// 2.排序
// job.setSortComparatorClass();
// 3.combiner -可选项
// job.setCombinerClass(WordCountCombiner.class);
// 4.compress -可配置
// configuration.set("mapreduce.map.output.compress","true");
// 使用的SnappyCodec压缩算法
// configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
// 5.分组
// job.setGroupingComparatorClass();
// 6.设置reduce的数量
job.setNumReduceTasks(2);
// 3.3) reduce,指定job的reducer和输出类型
job.setReducerClass(TemplateReducer.class);
//TODO
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 3.4) output,指定job的输出
Path outpath = new Path(args[1]);
FileOutputFormat.setOutputPath(job,outpath);
// 4) commit,执行job
boolean isSuccess = job.waitForCompletion(true);
// 如果正常执行返回0,否则返回1
return (isSuccess) ? 0 : 1;
}
public static void main(String[] args) {
// 添加输入,输入参数
args = new String[]{
"hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/wordcount.txt",
"hdfs://bigdata-pro-m01:9000/user/caizhengjie/mr/output"
};
// WordCountUpMR wordCountUpMR = new WordCountUpMR();
Configuration configuration = new Configuration();
try {
// 判断输出的文件存不存在,如果存在就将它删除
Path fileOutPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(fileOutPath)){
fileSystem.delete(fileOutPath,true);
}
// 调用run方法
int status = ToolRunner.run(configuration,new MRTemplate(),args);
// 退出程序
System.exit(status);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
}
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!