教育平台的线上课程智能推荐策略-Python
1 背景
近年来,随着互联网与通信技术的高速发展,学习资源共享与建设呈现出新的发展趋势,多样化的线上教育平台如雨后春笋般争相涌入大众视野。尤其是自2020年初,受新冠肺炎疫情的冲击,学生返校进行线下 授课受到严重阻碍,由此,网络线上平台由此成为“互联网+教育”成果的重要发展领地,如何根据教育 平台把握用户信息,掌握用户课程偏好并提供精准的远程课程推荐服务成为了线上教育的热点话题。因此, 利用数据分析技术对教育平台的线上信息和用户学习信息进行研究具有重大意义。
2 挖掘目标
1. 分析平台用户的活跃情况,计算用户的流失率,为平台管理决策提供建议。
2. 分析线上课程的受欢迎程度,构建课程智能推荐模型,为教育平台的线上推荐服务提供策略。
3 数据说明
本案例使用3个数据集,包含users.csv(用户信息表)、study_information.csv(学习详情表)和 login.csv(登录详情表)3个数据表。
users.csv数据说明:
| 特征名称 | 特征说明 | |
|---|---|---|
| users | user_id | 用户id |
| register_time | 注册时间 | |
| recently_logged | 最近访问时间 | |
| number_of_classes_join | 加入班级数 | |
| number_of_classes_out | 退出班级数 | |
| learn_time | 学习时长(分) | |
| school | 用户所属学校 | |
| study_information | user_id | 用户id |
| course_id | 课程id | |
| course_join_time | 加入课程的时间 | |
| learn_process | 学习进度 | |
| price | 课程单价 | |
| login | user_id | 用户id |
| login_time | 登录时间 | |
| login_place | 登录地址 |
流程:

4 数据分析
4.1 导入第三方库
本文所用的库的版本分别为:
numpy的版本: 1.21.2 pandas的版本: 1.3.3 chinese_calendar的版本为: 1.5.0 pyecharts的版本: 1.9.0 scipy的版本: 1.3.1
import numpy as np
import pandas as pd
from chinese_calendar import is_workday # 用于判断是否为工作日
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.charts import Geo
import matplotlib.pyplot as plt
import scipy.spatial.distance as dist #距离计算库
import re
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
4.2 数据加载
因为数据中包含中文,因此encoding使用gbk格式。
# 用户信息表
users = pd.read_csv('./users.csv',encoding='gbk')
users.head()
# 学习详情表
study_info = pd.read_csv('./study_information.csv',encoding='gbk')
study_info.head()
# 登录详情表
login = pd.read_csv('./login.csv',encoding='gbk')
login.head()代码运行结果分别为:
用户详情表
学习详情表

登录详情表
数据大小:
users.shape
# (43983,7)
study_info.shape
# (194974,5)
login.shape
# (387144,3)用户信息表有43983行7列,学习详情表有194974行,5列,登录详情表有387144行3列。
4.3 数据探索与预处理
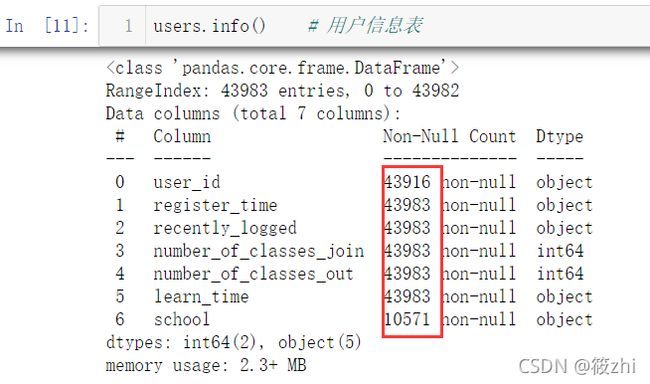
查看数据的简要摘要:
users.info()
study_info.info()
login.info()用户信息表:
学习详情表:
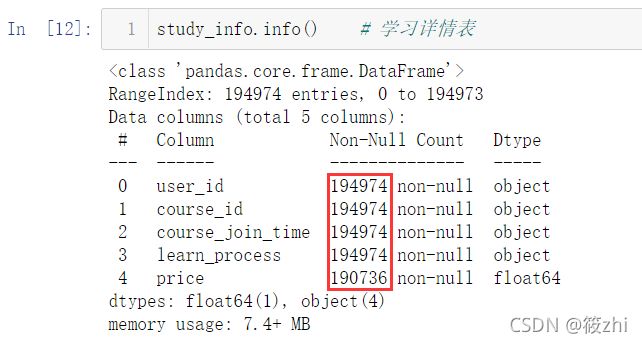
登录详情表:
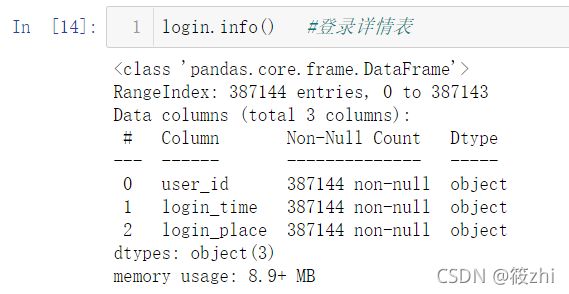
运行结果显示,用户信息表和学习详情表存在缺失值,register_time、rencently_logged、course_join_time以及login_time是object类型,需要转换为标准时间格式。
4.3.1 缺失值处理
通过查看缺失值个数可知,在users表中,user_id缺失值为67,school缺失值为33412,所以对user_id为空的记录进行删除;而school整列的缺失值过多,分析意义不大,因此把该列删除。在study_info表中,price列存在缺失值,结合背景分析,price列存在缺失值说明该门课程没有设置价格,即价格为0。
# 用户信息表
users.isnull().sum() #查看缺失值个数
# 删除user_id为空的记录
users.dropna(subset=['user_id'],axis = 0,inplace = True)
users.drop('school',axis=1,inplace=True)
users.shape # 缺失值处理后数据大小
# (43916,6)
# 学习详情表
study_info.isnull().sum()
study_info['price'].fillna(0,inplace = True)
study_info.shape
# (194974,5)4.3.2 重复值探索与处理
通过重复值探索发现,用户信息表存在重复值,结合背景分析,在用户信息表中,一个用户应该是对应一条数据,因此将user_id重复的值只保留一个。
# 用户信息表
users.shape
# (43916,6)
users.drop_duplicates().shape
# (43909,6)
users.drop_duplicates('user_id',inplace=True) #inplace=True表示在原始数据集生效
# 学习详情表
study_info.shape
# (194974, 5)
study_info.drop_duplicates().shape
# (194974, 5)
# 登录详情表
login.shape
# (387144, 3)
login.drop_duplicates().shape
# (387144, 3)4.3.3 异常值探索与处理
探索发现在用户信息表中存在最近访问时间为“--”的数据,这类数据是注册之后就没有登录过,因此把“--”转换为注册时间。
# 用户信息表
users['recently_logged'].value_counts() # 存在“--”异常数据
# 异常值数据替换
ind = users['recently_logged'] == '--'
# 替换为注册时间
users.loc[ind,'recently_logged'] = users.loc[ind,'register_time']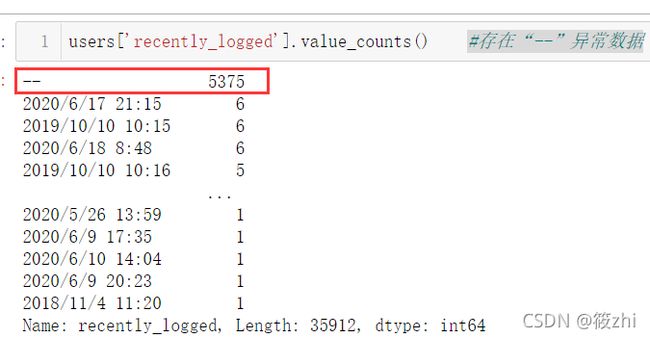
4.4 构建变量
4.4.1 构建省份变量
province = ['新疆','西藏', '青海', '甘肃', '四川','云南','宁夏','内蒙古','黑龙江','吉林','辽宁','河北','北京','天津','陕西','山西','山东','河南','重庆','湖北','安徽','江苏','上海','贵州','广西', '湖南', '江西', '浙江', '福建','广东', '海南','台湾','澳门', '香港']
def get_provice(x):
'''
提取省份数据
param x:用户登录地址
'''
for i in province:
if i in x:
return i
#调用函数提取省份
login['province'] = login['login_place'].apply(get_provice)
login['province']
#查看省份缺失数据占原始数据的比重
len1 = login['province'].isnull().sum()
len2 = login.shape[0]
print('省份缺失数据占原始数据的比重:',len1/len2)
# 省份缺失数据占原始数据的比重: 0.019969313743723266
# 删除省份缺失数据的记录
login.dropna(subset=['province'],axis=0,inplace=True)
#查看处理省份数据后的数据形状
login.shape
# (379413, 7)
4.4.2 构建城市变量
def get_city(x):
'''
提取城市数据
param x:用户登录地址
'''
if (x[2:5]=='黑龙江') or (x[2:5]=='内蒙古'):
return x[5:]
else:
return x[4:]
login['city'] = login['login_place'].apply(get_city)
login['city']
#查看城市空数据占原始数据的比重
len1 = (login['city']=='').sum()
len2 = login.shape[0]
print('城市缺失数据占原始数据的比重:',len1/len2)
# 城市缺失数据占原始数据的比重: 0.17364718657505146空值数据占比较大,是因为有些数据的login_place只填写了省份,如下图就是只填了中国贵州。在省份列中可以发现,数据存在有直辖市和行政区的,因此还需进行一下替换。
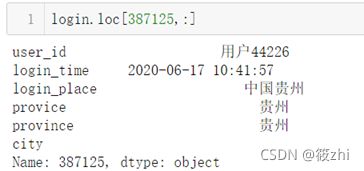
# 将直辖市与行政区的省份名与城市名进行替换
ind = login['province'].str.contains('北京|上海|重庆|天津|澳门|香港')
login.loc[ind,'city'] = login.loc[ind,'province']
#查看城市空数据占原始数据的比重
len1 = (login['city']=='').sum()
len2 = login.shape[0]
print('城市缺失数据占原始数据的比重:',len1/len2)
# 城市缺失数据占原始数据的比重: 0.17364718657505146结果显示,城市缺失数据占原始数据的比重明显下降。
4.4.3 构建时间变量
首先将时间变为datatime64格式,再判断是否为工作日,最后提取登录时间所在小时形成一个hour新列。
# 转换成标准时间格式
login['login_time'] = pd.to_datetime(login['login_time'])
# 根据日历来判断是否为工作日
login['is_workday'] = login['login_time'].apply(is_workday)
# 提取登录时间所在小时
login['hour']=login['login_time'].dt.hour
预处理完成后,将数据进行保存,方便后续继续分析。
# 数据保存
users.to_csv('./users_clean.csv',encoding='gbk',index=False)
study_info.to_csv('./study_info_clean.csv', encoding='gbk', index=False)
login.to_csv('./login_clean.csv', encoding='gbk', index=False)
4.5 用户活跃度分析
4.5.1 绘图各省份登录次数热力图(中国地图)
# 导入处理后的数据
users_clean = pd.read_csv('./users_clean.csv',encoding='gbk')
study_info_clean = pd.read_csv('./study_info_clean.csv',encoding='gbk')
login_clean = pd.read_csv('./login_clean.csv',encoding='gbk')
# 统计各省份的平台登录次数
pro_count = login_clean['province'].value_counts()
# 绘图
(
Map() #实例化类
.add(series_name='',data_pair=[(i,j)for i,j in zip(pro_count.index,pro_count)]) #添加数据,series_name系列名称
.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=20000),
title_opts = opts.TitleOpts('各省份登录次数热力图')) #视觉配置项
).render_notebook() #图表显示绘图结果:
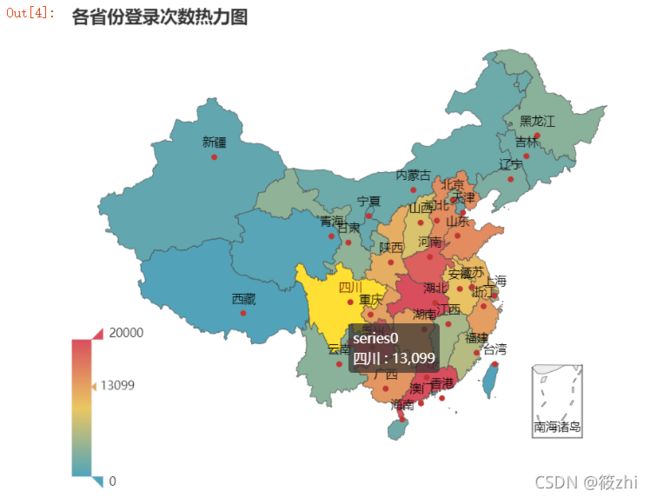
由上图显示,颜色最红(即登录次数最多)的省份为广东省,其次湖北省,再是贵州省。
4.5.2 绘制各城市登录次数热力图
# 统计各城市的平台登录次数
city_count = login_clean['city'].value_counts()
# 绘图
geo = Geo() #实例化类
geo.add_schema(maptype='china') # 选择地图类型
for i in range(len(city_count)):
try:
geo.add(series_name='',data_pair=[(city_count.index.tolist()[i],city_count.tolist()[i])],
symbol_size =7
)
except:
pass #忽略错误
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=3000),
title_opts = opts.TitleOpts('各城市登录次数热力图')) #视觉配置项
geo.set_series_opts(label_opts = opts.LabelOpts(is_show=False)) #设置不显示标签
geo.render_notebook() #图标显示 绘图结果:
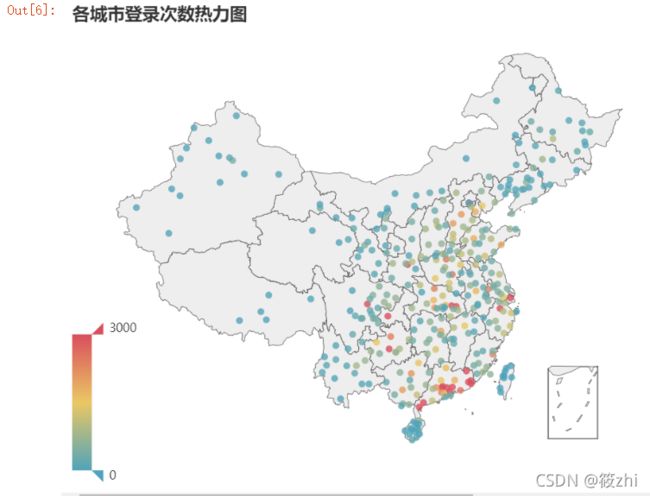
由各城市登录次数热力图显示,登录次数最多的是广州,第二是重庆,第三是汕头,接着是深圳,再是惠州。次数前五中,有4个城市均是广东省的。
4.5.3 绘制工作日各时间段用户登录次数占比图
先把时间划分为时间段,每两个小时为一个时间段。
# 划分时间段
def get_time(x):
'''
实现划分时间段,每两个小时为一个时间段
param x:小时数据
'''
for i in range(0,23,2):
if i<=x<=i+1:
return str(i)+'-'+str(i+1),int(i/2)
# 调用自定义函数实现时间段划分
login_clean['time']=login_clean['hour'].apply(lambda x:get_time(x)[0])
# 调用自定义函数获取时间段id
login_clean['time_id']=login_clean['hour'].apply(lambda x:get_time(x)[1])
# 统计工作日各时间段平台用户登录次数
workday_count = login_clean[login_clean['is_workday'] == True].groupby(by=['time_id','time']).agg({'user_id':'count'}).reset_index()
# 绘图
plt.bar(workday_count['time'],workday_count['user_id']/sum(workday_count['user_id']))
plt.xlabel('时间段')
plt.ylabel('登录次数占比')
plt.title('工作日各时间段登录次数占比图')
# plt.test()
plt.show()可视化结果:
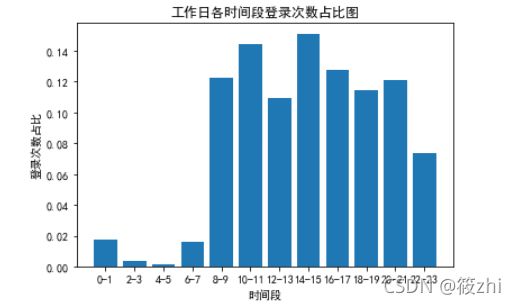
由可视化结果可知,在工作日时,极大部分人的登录时间是上午8点到晚上23点的时间,其中在14点到15点这个时间段的登录次数最多,22点到23点的登录次数最少。
4.5.4 绘制非工作日各时间段用户登录次数占比图¶
# 统计工作日各时间段平台用户登录次数
workday_count = login_clean[login_clean['is_workday'] == False].groupby(by=['time_id','time']).agg({'user_id':'count'}).reset_index()
# 绘图
plt.bar(workday_count['time'],workday_count['user_id']/sum(workday_count['user_id']),)
plt.xlabel('时间段')
plt.ylabel('登录次数占比')
plt.title('非工作日各时间段登录次数占比图')
plt.show()可视化结果:
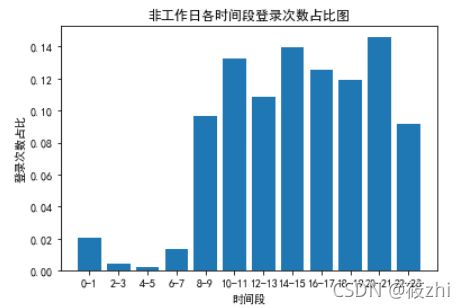
据非工作日各时间段登录次数占比图,登录次数最多的是20点到21点,在8点到23点的时间段中,22点到23点的次数也是最少,但相较于工作日该时间段的登录次数是增多的。
4.5.5 用户流失率分析
针对一个发展较为成熟的教育平台而言,实际上成功发展一位新用户的成本大概率上是维护老用户使用该平台成本的数倍,因此一个平台的用户流失率对于该平台的收益起着决定性的作用,意味着低用户流失率高利润营收。因此在分析用户流失率的过程中,如何理清“流失用户”和“流失率”显得尤为重要。本案例将流失用户定义为δi=Tend一Ti,δi >90天的用户,其中Tend为数据观察窗口截止时间(2020年6月18日),Ti为用户i的最近访问时间。
# 转换为标准时间格式
users_clean['recently_logged'] = pd.to_datetime(users_clean['recently_logged'])
# 判断是否为流失用户
churn_users = (pd.to_datetime('2020-06-18 23:59:59')-users_clean['recently_logged']).dt.days > 90
# 计算用户流失率
print('用户流失率',sum(churn_users)/len(churn_users))
用户流失率 0.5844037533023595
# 转换为标准时间格式
users_clean['register_time'] = pd.to_datetime(users_clean['register_time'])
# 判断是否为老用户(注册时间大于3个月)
old_users = (pd.to_datetime('2020-06-18 23:59:59')-users_clean['register_time']).dt.days > 90
# 计算用户流失率
print('用户流失率:',sum(old_users)/len(old_users))
用户流失率: 0.7829552701102305结果显示,平台用户流失率较高,针对这一现象,建议该教育平台通过相关分析软件对平台用户进行实时动态分析,把未流失的用户分类。根据这部分用户的行为特征,自身的偏好和需求,在平台上投放相关优质产品的信息,激发用户的活跃度,提高用户的忠诚度。
4.6 线上课程推荐
4.6.1 课程欢迎度
对该平台上所有的课程以及每门课程的参与人数进行统计,并按照受欢迎程度公式计算每门课的受欢迎程度,即: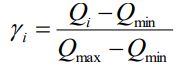
其中,γi为第门课程的受欢迎程度,Qi为参与第门课程学习的人数,Qmax和Qmin分别是该平台上所有课程中参与人数最多的课程所对应的人数和参与人数最少的课程所对应的人数。
# 统计每门课程的参与人数
course_count = study_info_clean['course_id'].value_counts()
# 平台上所有课程中参与人数最多的课程所对应的人数
course_count_max = course_count.max()
# 平台上所有课程中参与人数最少的课程所对应的人数
course_count_min = course_count.min()
# 每门课程的受欢迎程度
course_pop = course_count.apply(lambda x:(x-course_count_min)/(course_count_max-course_count_min))
# 最受欢迎的前10门课程
course_pop_top10 = course_pop.sort_values(ascending = False)[:10]
plt.figure(figsize=(8,6))
plt.bar(course_pop_top10.index,course_pop_top10)
plt.xlabel('课程')
plt.ylabel('受欢迎程度')
plt.title('最受欢迎的前十门课程')
plt.show()结果显示:
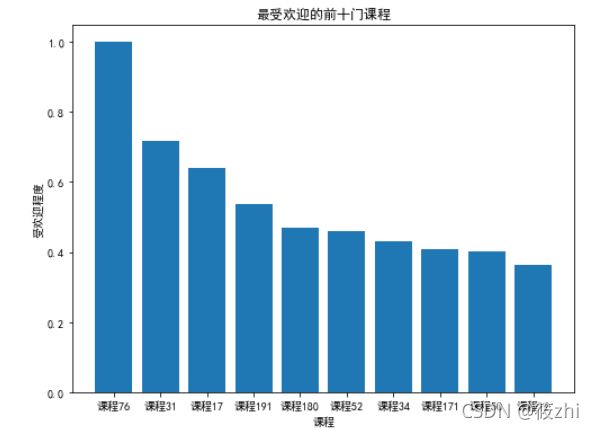
受欢迎程度排名前十门的课程分别是课程76、课程31、课程17、课程191、课程180、课 程52、课程34、课程171、课程50和课程12,其中受欢迎指数的最大值和最小值相差0.6360, 差距较为悬殊。这表明该教育平台上的优质课程呈现出较为明显的两极分化,相关人员在安排课程时应强调均衡发展,在保持特色优质课的同时,提高课程参与人数少的相关课程的质量。
4.6.2 课程推荐
本文采用Collaborative Filtering(协同过滤)算法。协同过滤算法,是基于用户的协同过滤推荐和基于物品的协调过滤推荐。首先需要收集好用户的偏好,再找到相似的用户或物品,最后进行推荐。
基于用户的协同过滤算法:该算法是通过用户的历史行为数据发现用户对商品或内容的喜欢〈如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐。
基于物品的协同过滤算法与基于用户的协同过滤算法很像,将商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。这里的评分代表用户对商品的态度和偏好。简单来说就是如果用户A同时购买了商品1和商品2,那么说明商品1和商品2的相关度较高。当用户B也购买了商品1时,可以推断他也有购买商品2的需求。
用户物品矩阵:
# 新增聚合列score列
study_info_clean['score']=1
# 数据透视表,构建用户课程矩阵
user_course = pd.pivot_table(study_info_clean,index='user_id',columns='course_id',
values='score',fill_value=0)
user_course结果显示:
计算课程之间的相似度:
def simlarity(x):
'''
计算物品之间的相似度
param x:用户物品矩阵
'''
sim = pd.DataFrame(columns = x.columns,index=x.columns)
for i in x.columns:
for j in x.columns:
matv = np.mat(user_course[[i,j]]).T
sim.loc[i,j] = 1 - dist.pdist(matv, 'jaccard')[0] # 杰卡德相似系数求得课程之间的相似度
return sim
#调用自定义函数构建课程相似度矩阵
sim = simlarity(user_course)
sim 结果显示:

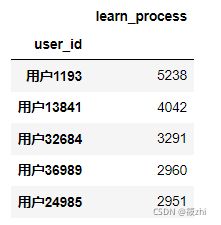
课程总学习进度前5学员id:
# 提取学习进度
study_info_clean['learn_process'] = study_info_clean['learn_process'].apply(lambda x:int(re.sub('\D','',x)))
# 统计各用户学习总进度
learn_count = study_info_clean.groupby('user_id').agg({'learn_process':'sum'})
# 筛选总学习进度前5的数据
learn_count_top5 = learn_count.sort_values(by = 'learn_process',ascending = False)[:5]
learn_count_top5结果显示:
提取总学习进度前5的用户及其对应课程:
ind = study_info_clean['user_id'].isin(learn_count_top5.index)
rem = study_info_clean.loc[ind,['user_id','course_id']]课程推荐:
# 课程推荐
for i in rem.index:
course = rem.loc[i,'course_id'] #所看课程
ind = sim.columns != course # 剔除掉要推荐的课程
rem.loc[i,'rem'] = sim.loc[course,ind].astype('float').idxmax() # 相似度最高的课程名称
rem.loc[i,'score'] = sim.loc[course,ind].max() # 相似度最高的
rem 结果显示,
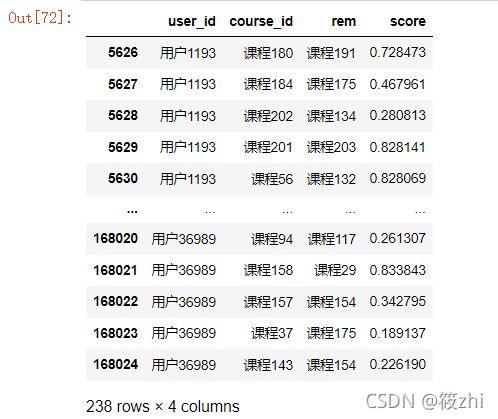
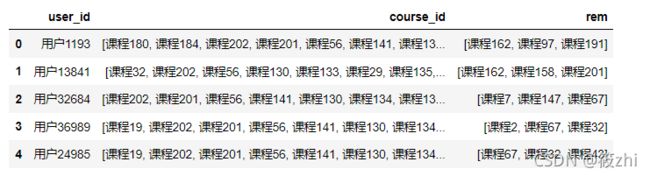
选取用户推荐相似度排在前3 的课程:
# 用户推荐相似度排在前3的课程
tuijian = []
# learn_count_top5.index是用户名
for i in learn_count_top5.index:
rem_user = rem[rem['user_id'] == i]
tui = rem_user.sort_values(by = 'score',ascending = False)['rem'].drop_duplicates() # 所有推荐课程
tui = [i for i in tui if i not in rem_user['course_id'].tolist()] # 剔除掉用户已经观看过的课程
dic = {}
dic['user_id'] = i # 用户
dic['course_id'] = rem_user['course_id'].tolist() # 已经看过的课程
dic['rem'] = tui[:3] # 推荐相似度排在前3的课程
tuijian.append(dic)
tuijian = pd.DataFrame(tuijian)
tuijian结果显示: