【2022新生学习】第一周要点
1、神经网络的波折。希望同学们知道,深度学习的兴起,经历了很多波折:
(1)Rosenblat 的感知机(1957)
Rosenblatt 于1957年提出感知机,模拟了神经元,但是却因为两个问题被当时的巨头Minsky批评:1、无法解决异或问题;2、巨大的计算量。此后十几年,神经网络进入低潮,相关研究进入冬天。Rosenblatt 本人也没能见到神经网络的复兴。

(2)Hinton的BP算法(1986)和 Lecun 的CNN(1989)
Hinton出生在英国的“书香门第”,家人大都是数学家。他本科学心理学,因此一直对于模拟人脑的神经网络着迷,40多年来一直坚持研究大家普遍不看好的神经网络研究。1986年,Hinton发明了BP算法,解决了异或问题,神经网络研究开始复苏。
法国人Yann Lecun跟Hinton做博后,随后1989年在Bell Lab发明了 LeNet (卷积神经网络,CNN)用于手写数字识别,准确率非常高在美国占了占20%的市场。但是,同事Vapnik的SVM(支持向量机)把CNN又推向了寒冬(1990到2012一直是主导地位,尽管效果差,但是没有更好的方法)。
(3)吴恩达将GPU带入深度学习
2004年,CIFAR开始资助神经网络研究(全球唯一高额资助神经网络研究的机构),Hinton马上把“神经网络”改名为“Deep learning” (名人也是信风水的)
2009年,吴恩达将GPU引入深度学习,发现可以加速70倍。一个亿参数的网络训练时间从2个多月,降到1天!
(4)AlexNet的进击
2009年,普林斯顿的李飞飞构建了ImageNet数据集(320万张图像),2010年起每年组织一次图像分类竞赛。2010年,NEC和UIUC联队使用SVM分类错误率为28%;2011年,Feisher Vector 方法将错误率降到25.7%。
2012年,Hinton 和 Alex Krizhevsky,Illy Sutskever,利用CNN+Dropout+ReLU,使用两个GTX580显卡,错误率降低到15.3%,比第二名低了近10个点
学术界和工业界都沸腾了,这是20多年以来,神经网络首次大幅度击败了SVM,也是人工智能的一个转折点。

(5)Bengio 和 ReLU
2011年,Bengio发明了ReLU激活函数,神经网络收敛更快,错误率更低,有效缓解了“梯度消失问题”,因此获得2018年度的图灵奖。

2019年3月,ACM 宣布,有“深度学习三巨头”之称的 Yoshua Bengio、Yann LeCun、Geoffrey Hinton共同获得了2018年度的图灵奖,这是图灵奖1966年建立以来少有的一年颁奖给三位获奖者。(希望同学们知道每个人的学术贡献)
2、激活函数的作用: 如果没有非线性激活函数,神经网络就是简单的矩阵相乘,没有办法做非线性分类。(http://playground.tensorflow.org/ 可以演示一下使用 linear activation)
3、梯度消失现象: 相当长的一段时间,神经网络都是三层的。如果神经网络过深,就难以准确分类,这是因为存在梯度消失现象。(继续演示梯度消失,ReLU确实收敛的非常快)
4、网络更宽 OR 更深?万有逼近定理说,一个网络中间隐层节点足够多就可以了。前面我们又看到神经网络需要有足够多的层数。有人研究过,深度和宽度对函数复杂度的贡献是不同的,深度的贡献是指数增长的,而宽度的贡献是线性的。因此,当前的主流神经网络都是往更深发展。
5、深度学习的框架:目前 PyTorch 和 TensorFlow 是主流框架,但是学术界应用更多的是 PyTorch,因为代码实现更容易。“Keep it simple, stupid” (PyTorch和TensforFlow的对比有些像 Matlab 和 C++)
6、为什么要使用Softmax? 很多时候我们需要的输出的是一个概率。比如行人检测中,当前框中是行人还是背景?这个概率值可以用于平衡结果(是误检多,还是漏检多)。一般神经网络的最后分类结果,都是要加 Softmax 来归一化。

7、为什么每一个 epoch或 batch 完成以后要 zero_grad? 网上有很多解答,大家可以多看看。梯度累加到一定程度会“梯度爆炸”,需要手动清零
8、SGD 和 Adam 到底哪个更有效?同学们可以自己去知乎,看看 SGD 和 Adam 的基本原理,大多数情况下,使用 Adam 的效果会略好一些。但是在某些情况下,SGD会取得更好的效果,所以在当前的一些顶会论文里,也能看到使用SGD的情况。完全是要看情况,没有最好之分。
螺旋分类代码练习
!wget https://raw.githubusercontent.com/Atcold/pytorch-Deep-Learning/master/res/plot_lib.py
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab是支持GPU的,torch 将在 GPU 上运行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device: ', device)
# 初始化随机数种子。神经网络的参数都是随机初始化的,
# 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的,
# 因此,在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量定义基本变量,模型准备。
X = torch.zeros(N * C, D).to(device)
Y = torch.zeros(N * C, dtype=torch.long).to(device)
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
# visualise the data
plot_data(X, Y)
1、构建一个不含激活函数的3层神经网络
learning_rate = 1e-3
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
if t%100==0:
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
plot_model(X, Y, model) 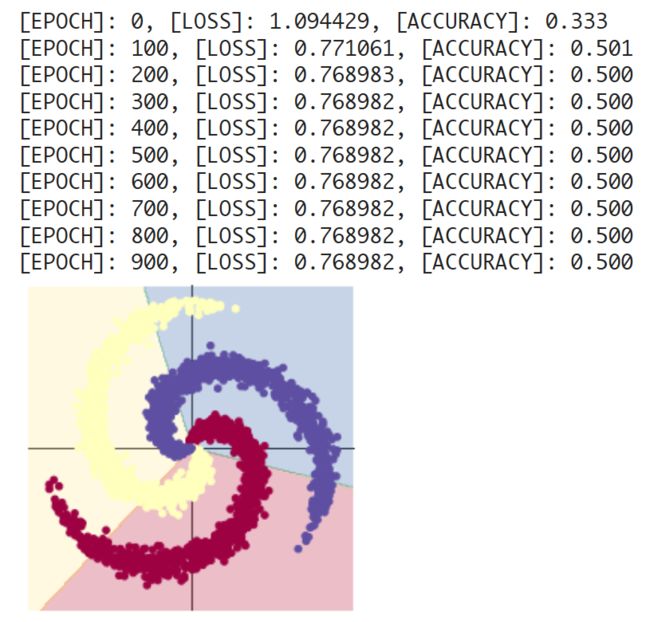
可以看到没有激活函数,神经网络只能做矩阵相乘的线性分类,效果不行。
2、构建一个含 Sigmoid 激活函数的3层神经网络 (收敛很慢,需要更多的训练轮次才能提升准确率)
# 和上面模型不同的是,在两层之间加入了一个 Sigmoid 激活函数
# 其它代码不用变化
model = nn.Sequential(
nn.Linear(D, H),
nn.Sigmoid(),
nn.Linear(H, C)
)

可以看到,Sigmoid收敛很快,增加 epoch 数量,网络也能收敛。
3、构建一个含 ReLU 激活函数的3层神经网络
# 和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
# 其它代码不用变化
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)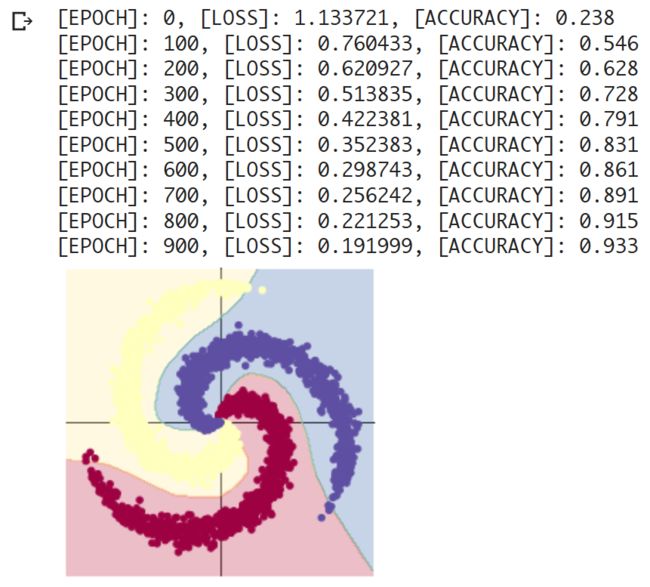
可以看到 ReLU 效果很好,神经网络收敛的很快。
4、观察分类结果,并使用 Softmax
print(Y[500],'\n',Y[1500],'\n',Y[2500])
print(y_pred[500, :],'\n',y_pred[1500,:],'\n',y_pred[2500, :])tensor(0, device='cuda:0')
tensor(1, device='cuda:0')
tensor(2, device='cuda:0')
tensor([ 1.5573, -1.7284, -1.9690], device='cuda:0', grad_fn=
tensor([ 0.2106, 2.1049, -3.4329], device='cuda:0', grad_fn=
tensor([-1.7569, 0.5626, 2.6363], device='cuda:0', grad_fn=
可以看到,结果需要归一化效果才方便得到分类结果属于各个类别的概率。
# 继续改进网络,在最后加一个Softmax,其它代码没有变化
# 注意 dim=1
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C),
nn.Softmax(dim=1)
)再次输出结果,可以看到 Softmax 的效果:
print(Y[500],'\n',Y[1500],'\n',Y[2500])
print(y_pred[500, :],'\n',y_pred[1500,:],'\n',y_pred[2500, :])tensor(0, device='cuda:0')
tensor(1, device='cuda:0')
tensor(2, device='cuda:0')
tensor([0.9457, 0.0393, 0.0151], device='cuda:0', grad_fn=
tensor([0.1280, 0.8704, 0.0016], device='cuda:0', grad_fn=
tensor([0.0081, 0.1042, 0.8877], device='cuda:0', grad_fn=