北理工慕课 嵩天 Python零基础入门 笔记整理
目录
- 1.python基础语法
-
- 1.1注释
- 1.2实例1:温度转换
- 1.3 python的33个关键字
- 1.4数据类型
-
- 1.4.1字符串的序号
- 1.4.2列表类型
- 1.5 input函数
- 1.6 print函数
-
- 1.6.1print函数不换行
- 1.7 eval函数
- 1.8Debug工具
-
- 1.8.1打断点
- 1.8.2 Debug调试
- 2.python基本图形绘制
-
- 2.1实例2:蟒蛇绘制
- 2.2 turtle(海龟)库的使用
-
- 2.2.1 turtle的绘图窗体
- 2.2.2 turtle的空间坐标系
- 2.2.3 turtle的角度坐标体系
- 2.3 RGB色彩体系???
- 2.4 turtle程序语法程序分析
-
- 2.4.1库引用与import
- 2.4.2 turtle画笔控制函数
- 2.4.3 turtle 运动控制函数
- 2.4.4 for in 与range()函数
- 3.基本数据类型
-
- 3.1 浮点数类型
-
- 3.1.1 round函数
- 3.1.2科学计数法
- 3.2复数类型
- 3.3数值运算操作符
- 3.4数值运算函数
- 3.5 实例3:天天向上
- 3.6 字符串类型
-
- 3.6.1字符串切片
- 3.6.2字符串逆序
- 3.6.3转义字符 \
- 3.6.4字符串操作符
- 3.6.5字符串处理方法
- 3.6.6字符串的格式化.format
-
- (1)槽的概念{}
- (2)字符串输出格式控制
- 3.7 time库
-
- 3.7.1获取时间的三个时间函数
- 3.7.2 时间格式化
- 3.7.3 程序计时
-
- (1)perf_counter()函数
- (2)sleep()函数
- 3.8 实例4:文本进度条
-
- 3.8.1简单版
- 3.8.2单行动态刷新
- 4.程序的控制结构
-
- 4.1分支结构
-
- 4.1.1单分支if
- 4.1.2二分支if...else
- 4.1.3多分支结构if..elif...else
- 4.1.4逻辑 与、或、非
- 4.1.5程序的异常处理
- 4.1.6同时接收多个输入
- 4.2循环结构
-
- 4.2.1遍历循环 for...in...
- 4.2.2 无限循环while
- 4.2.3循环控制break和continue
- 4.2.4循环与else
- 4.3 random库的使用
-
- 4.3.1 基本随机数函数
- 4.3.2 扩展随机数函数
- 4.4 实例6:蒙特卡罗法计算圆周率
- 5.函数与代码复用
-
- 5.1函数的定义与使用
-
- 5.1.1函数的参数
-
- 1.可选参数
- 2.可变参数
- 5.1.2函数的返回值
- 5.1.3全局变量与局部变量
-
- 1.使用规则
- 2.global限定词
- 3.组合数据类型做参数
- 4. lambda函数
- 5.2实例7 七段数码管的绘制
- 5.3递归
-
- 5.3.1递归实现字符串逆序
- 5.4 Pyinstaller库的使用
- 5.5 科赫雪花小包裹(没看)
- 6.组合数据类型
-
- 6.1集合类型
-
- 6.1.1定义
- 6.1.2集合操作符
- 6.1.3集合处理函数
- 6.1.4数据去重
- 6.2序列类型
-
- 6.2.1定义及分类
- 6.2.2元组类型
- 6.2.3列表类型
- 6.3实例9:基本统计值计算
- 6.4字典类型
-
- 6.4.1字典的定义
- 6.4.2字典类型的函数
- 6.5 jieba库的使用
-
- 6.5.1作用及安装
- 6.5.2 jieba分词的使用
- 6.6 实例10:文本词频统计
1.python基础语法
1.1注释
单行注释:井号#
print('hello world') #单行注释
多行注释:三个单引号之间的内容
print('hello')
'''
多行注释
多行注释
'''
加注释的快捷键:Ctrl+/
1.2实例1:温度转换
#Tempconvert.py
TempStr = input('请输入温度值:')
if TempStr[-1] in ['F', 'f']: #TempStr[-1]是倒数第一个字符
C = (eval(TempStr[0:-1]) - 32)/1.8
print("转换后的温度是{: .2f}C" . format(C))
elif TempStr[-1] in ['C', 'c']:
F = 1.8*eval(TempStr[0:-1]) + 32
print("转换后的温度是{: .2f}F" . format(F))
else:
print('error')
1.3 python的33个关键字

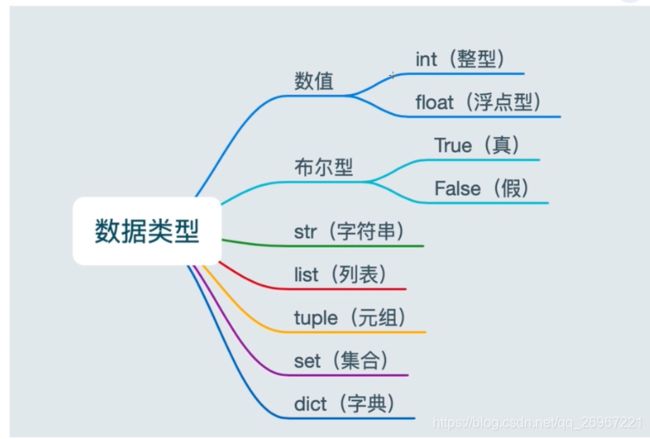
1.4数据类型
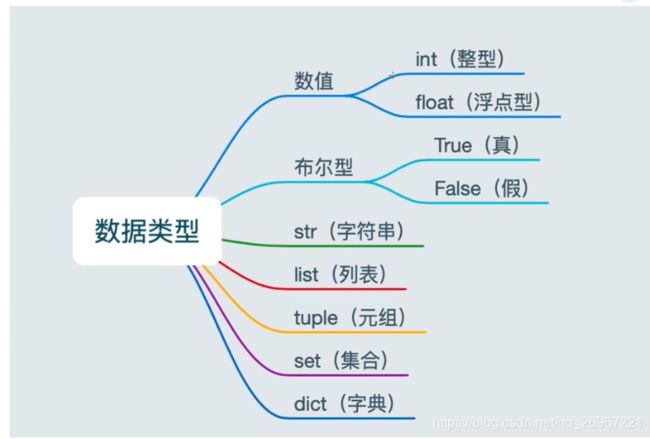
a = [10, 20, 30]
print(type(a)) # 输出 列表类型
b = (10, 20, 30)
print(type(b)) # 输出 元组类型
c = {10, 20, 30}
print(type(c)) # 输出 集合类型
d = {'name':'Tom', 'age':18 } #键值对
print(type(d)) # 输出 字典类型
1.4.1字符串的序号
分为两种:从0开始正向递增 和 从-1开始逆向递减

如:TempStr[0]是正数第一个字符
TempStr[-1]是倒数第一个字符
TempStr[0 : -1]表示从第1个字符到倒数第2个字符(不包括倒数第1个)
TempStr[1 :3]表示从第1个字符到第2个字符(不包括第3个)
1.4.2列表类型
中括号[ 元素1,元素2,… ,元素n]
if TempStr[-1] in ['F', 'f']: #TempStr[-1]是倒数第一个字符,
#此语句意为:字符串TempStr的最后一个字符是否在列表F和f内
1.5 input函数
TempStr = input('请输入温度值:')
>>>123
"请输入温度值"并没有存入TempStr,只是一个提示,真正存在TempStr中的是键盘输入的字符串123,
即TempStr字符串存的是字符串“123”
1.6 print函数
1.6.1print函数不换行
print()函数默认换行,它有个参数end=’\n’,只要使end的参数为’’ 或 ‘空格’ 或其他即可
print('hello world',end='')
print('!!!')
>>>hello world!!!
for i in range(5):
print(i,end='-')
>>>0-1-2-3-4-
1.7 eval函数
作用:去掉参数最外层的引号并执行剩下的语句
>>>eval('1')
输出 1
>>>eval('1+2')
输出 3
>>>eval("'1+2'")
输出 '1+2'
>>>eval("print('hello world')") #相当于执行print('hello world')
输出 hello world
与eval()函数功能相反的函数:str()
1.8Debug工具
1.8.1打断点
单击待debug语句左侧,出现红点。
1.8.2 Debug调试
右击空白区域,选debug
2.python基本图形绘制
2.1实例2:蟒蛇绘制
#PythonDraw.py
import turtle
turtle.setup(650, 350, 200, 200) #窗口宽度650,高度350,左上角坐标(200,200)
turtle.penup()
turtle.fd(-250)
turtle.pendown()
turtle.pensize(25)
turtle.pencolor("purple")
turtle.seth(-40)
for i in range(4):
turtle.circle(40,80)
turtle.circle(-40,80)
turtle.circle(40, 80/2)
turtle.fd(40)
turtle.circle(16,180)
turtle.fd(40 * 2/3)
turtle.done()
2.2 turtle(海龟)库的使用
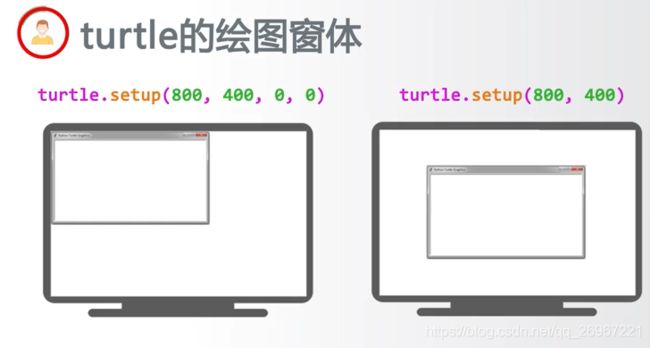
2.2.1 turtle的绘图窗体

屏幕左上角的坐标为(0,0),turtle绘图窗口左上角坐标为(startx,starty)
turtle.setup(宽度,高度,窗口起始横坐标,窗口起始纵坐标)
turtle.setup(宽度, 高度,startx, starty) #若后两个参数不填,则默认窗口在屏幕中间
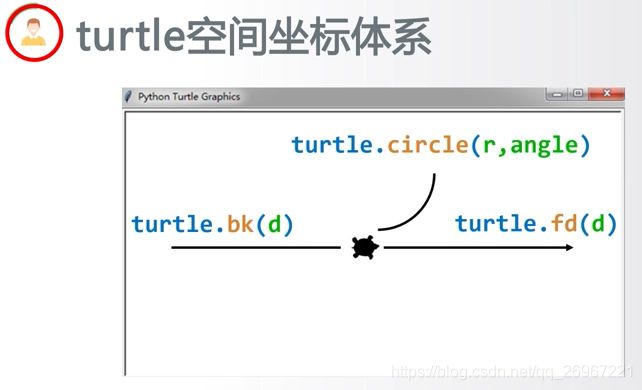
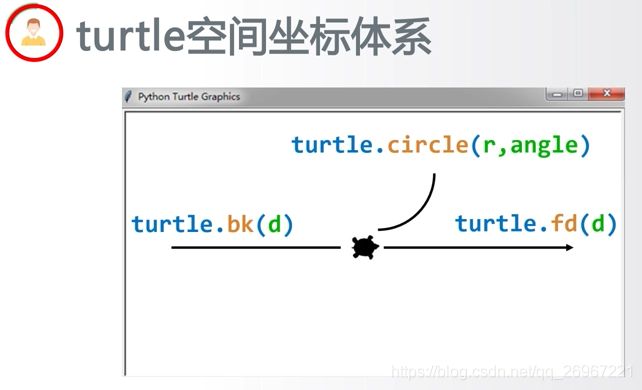
2.2.2 turtle的空间坐标系
海龟行进方向默认是向右的!
turtle.goto(横坐标,纵坐标) #海龟向某坐标行进;
turtle.fd(d)或 turtle.forward(d) #向海龟头的正前方行进长度为d像素的距离;
turtle.bk(d)或 turtle.backward #向海龟头的正后方行进长度为d像素的距离;
turtle.circle(r, 角度) #曲线运行,默认以当前海龟头的左侧,r为半径,曲线行进某某角度

2.2.3 turtle的角度坐标体系
海龟的头默认是向右的,即海龟行进方向默认是向右的!
turtle.seth(角度) #是使海龟的头转到某一角度,只转动方向,不行进!

turtle.left(角度) #以当前方向为准,向左转某某角度,注意:只转动方向,不行进!
turtle.right(角度) #以当前方向为准,向右转某某角度,注意:只转动方向,不行进!

2.3 RGB色彩体系???
(一笔带过,貌似不重要???)
2.4 turtle程序语法程序分析
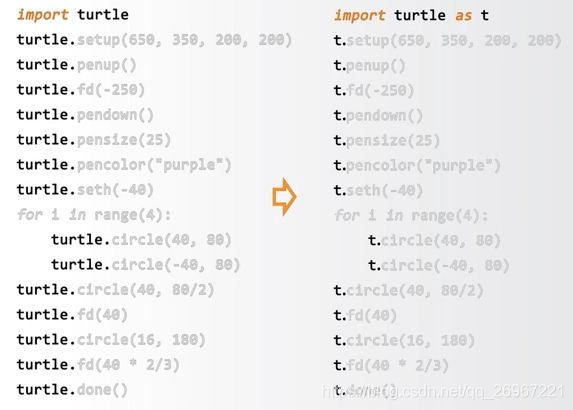
2.4.1库引用与import
import的三种用法
- import 库名
库名.函数名 优点:不会出现函数重名 缺点:繁琐
-
from 库名 import * 优点:简洁 缺点:可能函数重名
-
import 库名 as 库别名

2.4.2 turtle画笔控制函数
turtle.penup 提笔
turtle.pendown 落笔
turtle.pensize(画笔宽度)
turtle.pencolor(“画笔颜色”)或 turtle.pencolor(x,y,z)三个RGB参数
turtle.penup() #提笔
turtle.fd(-250) #海龟倒退250像素
turtle.pendown() #落笔
turtle.pensize(25) #画笔宽度25像素
turtle.pencolor("purple") #画笔颜色为紫色purple
2.4.3 turtle 运动控制函数
海龟行进方向默认是向右的!
turtle.goto(横坐标,纵坐标) #海龟向某坐标行进;
turtle.fd(d) #向海龟头的正前方行进长度为d像素的距离;
turtle.bk(d) #向海龟头的正后方行进长度为d像素的距离;
turtle.circle #曲线运行,默认以当前海龟头的左侧,r为半径,曲线行进某某角度

海龟的头默认是向右的,即海龟行进方向默认是向右的!
turtle.seth(角度) #是使海龟的头转到某一角度,只转动方向,不行进!

turtle.left(角度) #以当前方向为准,向左转某某角度,注意:只转动方向,不行进!
turtle.right(角度) #以当前方向为准,向右转某某角度,注意:只转动方向,不行进!

2.4.4 for in 与range()函数
for i in range(4): #从0到3循环
range(n):产生从0到n-1的数
range(n,m):产生从n到m-1的数
for i in range(4):
print(i)
"""输出:
0
1
2
3
"""
for i in range(2,5):
print(i)
"""输出:
2
3
4
"""
3.基本数据类型
3.1 浮点数类型
3.1.1 round函数
浮点数间运算存在不确定尾数(不属于bug),如0.1+0.2结果为0.3000000xxxxx,并非严格的0.3
round(x, n)表示对x四舍五入,保留小数点后n位
0.1 + 0.2 == 0.3 #False,事实上0.1+0.2结果为0.3000000xxxxx,并非严格的0.3
round(0.1 + 0.2, 1) == 0.3 #True,将相加后的结果保留一位小数,则等于0.3
3.1.2科学计数法
用e或E表示
如 2e3,表示2乘以10^3,结果为2000
4.3e-3 表示4.3乘以10^-3,结果为0.0043
3.2复数类型
z.real 获取实部
z.imag 获取虚部
3.3数值运算操作符
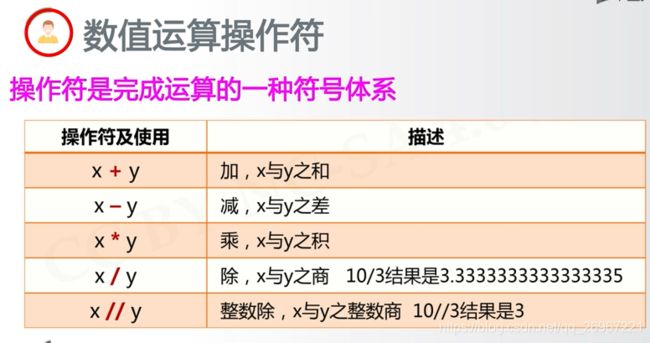

print(10/3) #答案是3.333333333333
print(10//3) #答案是3
print(10%3) #答案是1
指数:用两个星号 **
print(2**3) #答案是2^3=8
#等价于pow(2, 3)
print(2^3) #错误写法
print(4, 0.5) #开方,根号4,结果为2
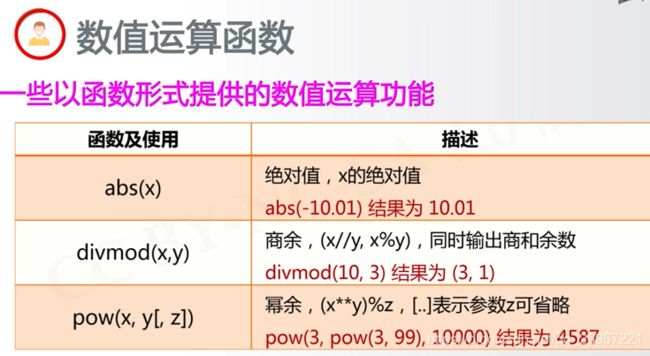
3.4数值运算函数
-
abd(x) 取绝对值
-
divmode(x, y) 同时输出商和余数 如divmode(10, 3) 结果为(3, 1)
-
pow(x, y, [z]) 求幂,并除以z取余 ,(z可以省略,则不用除以z取余)
t = pow(2, 4, 5)
print(t)
#结果为1,内部计算过程为:2的四次,等于16, 16再除以5取余,等于1
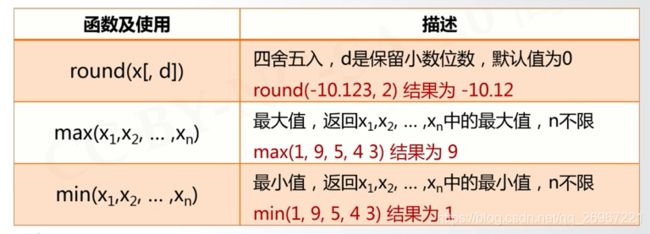
- round(x, [n]) 对x以n位小数四舍五入
t = round(1.584, 1)
print(t)
#结果为1.6
-
max(X1, X2, … , Xn) 取最大值
-
min(X1, X2, … , Xn) 取最小值
3.5 实例3:天天向上
#DayDayUp04.py
def DayUp(df): #def为函数定义标识符,DayUp为函数名,df为参数
dayup = 1
for i in range(365):
if i % 7 in [6, 0]:
dayup = dayup * (1 - 0.01)
else:
dayup = dayup * (1 + df)
return dayup
dayfactor = 0.01
while(DayUp(dayfactor) < 37.78):
dayfactor += 0.001
print("工作日努力参数为{:.3f}". format(dayfactor))
3.6 字符串类型
3.6.1字符串切片

str = '0123456789'
print(str[:3])
print(str[1:3])
print(str[1:8:2]) #从str[1]到str[8],以步长为2切片,即 间隔为2切片
>>>
012
12
1357
3.6.2字符串逆序
str = '123'
print(str[::-1])
#输出:321
3.6.3转义字符 \

3.6.4字符串操作符
3.6.5字符串处理方法


str = 'Aa,Bb,Cc,Dd,aa'
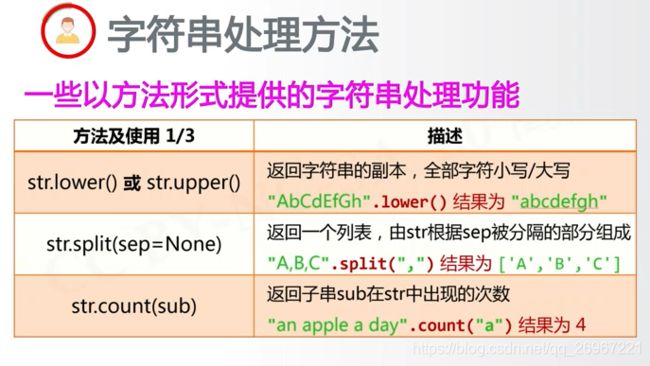
print(str.lower()) #字符全部小写
print(str.upper()) #字符全部大写
print(str.split(",")) #将原字符串以逗号相隔的部分返回成列表
print(str.count ('a')) #返回子串'a'在str中出现的次数
print(str.replace('Aa','Pp')) #将str中'Aa'替换为'Pp',但并没改变原str的值
>>>输出:
aa,bb,cc,dd,aa
AA,BB,CC,DD,AA
['Aa', 'Bb', 'Cc', 'Dd','aa']
3
Pp,Bb,Cc,Dd,aa
str.center(宽度,[填充物]) :
str = 'abc'
print(str.center(10, '*')) #总长10,str居中,其他部分由'*'填充
>>> ***abc****
str.strip()函数:
str = 'ab123aa456ba'
print(str.strip('ab')) #删除字符串首尾的字符a、b,中间的不删
>>>123aa456
str = 'ab123bca'
print(str.strip('abc'))#与顺序无关,只要首尾出现a、b、c 就删掉
>>>123
str.join()函数:
str1 = 'abc'
str2 = "-"
print(str2.join(str1)) #在str1的每个字符之间加一个字符串str2,
>>>a-b-c
str1 = 'abc'
str2 = "12"
print(str2.join(str1)) #在abc的每个字符之间加一个字符串12
>>>a12b12c
3.6.6字符串的格式化.format
(1)槽的概念{}
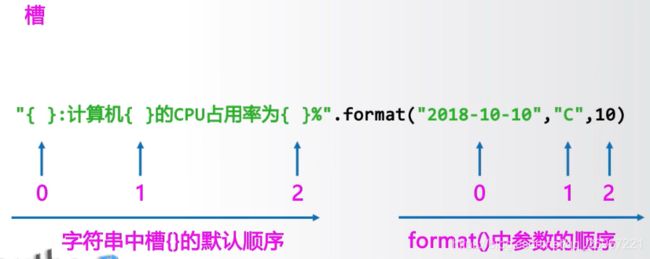
print("{}出生于{}年{}月{}日".format('李华',1997, 9, 15))
print("{1}出生于{0}年{3}月{2}日".format('李华',1997, 9, 15))
#参数顺序 0 1 2 3
>>>李华出生于1997年9月15日
>>>1997出生于李华年15月9日
(2)字符串输出格式控制

可以分类两类:1.填充(单个字符)、对齐、宽度
2. <,> 精度、类型

print("{0:=^10}".format("abcd"))
>>> ===abcd===
print("{0:*>10}".format('abcd'))
>>> ======abcd
print("{0:10}".format("abcd"))
>>> abcd

print("{0:,.2f}".format(12345.6789))
>>>12,345.68
print("{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(425))
>>>110101001,Ʃ,425,651,1a9,1A9
print("{0:e},{0:E},{0:f},{0:%}".format(3.14))
>>>3.140000e+00,3.140000E+00,3.140000,314.000000%
3.7 time库
3.7.1获取时间的三个时间函数
time.time()
time.ctime()
time.gmtime()
import time #输出:
print(time.time()) #1593655860.126274 返回浮点数,不常用
print(time.ctime()) #Thu Jul 2 10:11:00 2020 返回字符串
print(time.gmtime())#time.struct_time(tm_year=2020, tm_mon=7, tm_mday=2, tm_hour=2,tm_min=11, tm_sec=0, tm_wday=3, tm_yday=184,tm_isdst=0)
#返回计算机内部时间格式
3.7.2 时间格式化


strftime()与strptime功能相反!
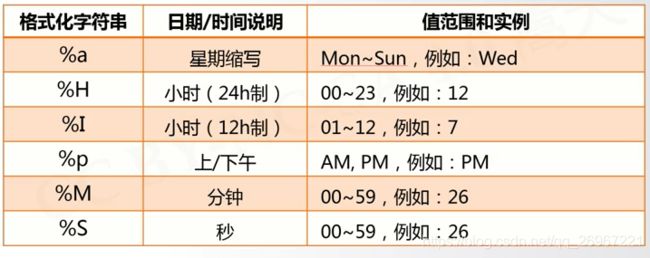
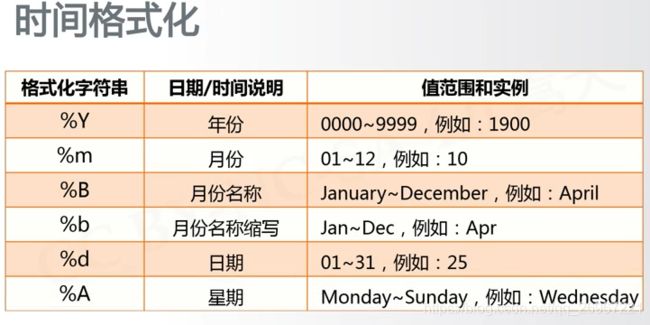
import time
ts = time.gmtime()
print(time.strftime('%A %Y-%m-%d %p %H:%M:%S',ts))
>>>Thursday 2020-07-02 AM 03:59:17
3.7.3 程序计时
(1)perf_counter()函数
(2)sleep()函数
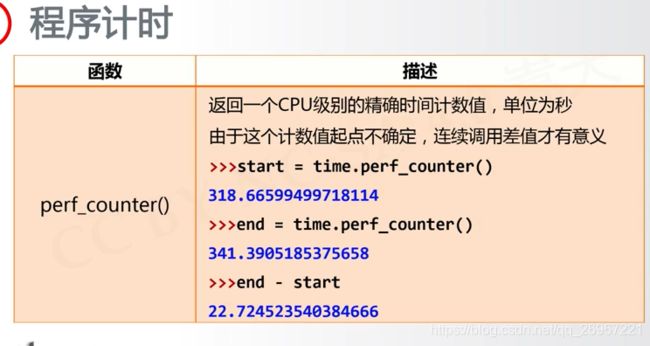

import time
start = time.perf_counter()
for i in range(10):
print(i,end='')
end = time.perf_counter()
print("\n未使用sleep()时所用时间:" + str(end - start) + '秒')
print("perf_counter()函数返回值类型为" + str(type(start)))
start1 = time.perf_counter()
for i in range(10):
print(i,end='') #print(待输出数据,end=‘’)表示不换行
time.sleep(3)
end1 = time.perf_counter()
print("\n使用sleep(3)后所用时间:" + str(end1 - start1) + '秒')
>>>0123456789
未使用sleep()时所用时间:0.10264549600000006秒
perf_counter()函数返回值类型为<class 'float'>
0123456789
使用sleep(3)后所用时间:3.097026212秒
3.8 实例4:文本进度条
3.8.1简单版

import time
scale = 10
print('-----开始执行-----')
for i in range(scale+1):
a = '*' * i
b = '.' * (scale - i)
c = (i/scale) * 100
print("{:^3}%[{}->{}]".format(int(c),a,b))
time.sleep(0.5)
print('-----执行结束-----')
>>>
-----开始执行-----
0 %[->..........]
10 %[*->.........]
20 %[**->........]
30 %[***->.......]
40 %[****->......]
50 %[*****->.....]
60 %[******->....]
70 %[*******->...]
80 %[********->..]
90 %[*********->.]
100%[**********->]
-----执行结束-----
3.8.2单行动态刷新
import time
scale = 100
print('开始执行'.center(14,'-'))
start = time.perf_counter()
for i in range(scale+1):
a = '*' * i
b = '.' * (scale - i)
c = (i/scale) * 100
dur = time.perf_counter() - start
print("\r{:^3}%[{}->{}]已耗时{:.2f}s".format(int(c),a,b,dur),end='')
time.sleep(0.1)
print('\n'+'执行结束'.center(14,'-'))
4.程序的控制结构
4.1分支结构
4.1.1单分支if
不像C语言需要括号,而是通过冒号及缩进来控制。
if True:
print("正确")
4.1.2二分支if…else
紧凑形式:

print("请您猜一个数字:")
guess = eval(input())
print("猜{}了".format('对' if guess==99 else '错'))
4.1.3多分支结构if…elif…else
4.1.4逻辑 与、或、非

if guess > 0 and guess < 99:
print('猜对了')
else:
print('猜错了')
4.1.5程序的异常处理

执行顺序:
先执行try 后的语句块1;
若1发生异常,执行except后的语句块2;
若1不发生异常,执行else后的语句块3;
finally后的语句块4是一定会执行的。
print("请输入一个数字:",end='')
try:
Input = eval(input())
print("{}的平方为{}".format(Input,Input**2))
except:
print("输入有误,不是数字")
else:
print("成功输出了{}的平方".format(Input))
finally:
print("结束")
>>>请输入一个数字:5
5的平方为25
成功输出了5的平方
结束
>>>请输入一个数字:kk
输入有误,不是数字
结束
4.1.6同时接收多个输入
法一:用eval函数
a1, a2 = eval(input("input two number:")) #输入时用逗号隔开
print(a1)
print(a2)
法二:用map函数 和 split函数
注意:中间用各种空字符隔开,包括空格、换行(\n)、制表符(\t)等,不能用逗号隔开!
#只用split,则输入类型默认为str
a1, a2 = input('输入两个数 a1和a2:').split() ##输入时用空格或回车隔开,不能用逗号
print('a1为' + a1 + ',类型为:'+str(type(a1)))
print('a2为' + a2 + ',类型为:'+str(type(a2)))
>>>
输入两个数 a1和a2:1 2
a1为1,类型为:<class 'str'>
a2为2,类型为:<class 'str'>
#引入map,可以改变输入类型
a1,a2 = map(int,input("input two number:").split()) #输入时用空格或回车隔开,不能用逗号
print(a1) #此时a1、b1的类型为int型
print(a2)
print(type(a1))
>>>
input two number:1 2
1
2
<class 'int'>
#若想用逗号隔开,可以改变split()内的参数为split(',')
a1,a2 = map(int,input("input two number:").split(‘,’))
4.2循环结构
4.2.1遍历循环 for…in…
#对数字进行循环
for i in range(2,5):
print('hello:',i)
>>>
hello:2
hello:3
hello:4
#对字符串遍历
for c in 'hello':
print(c,end=',') #将字符串单个输出,并在每个字符后面加逗号
>>>
h,e,l,l,o,
#对列表循环
for item in ['hello',123,'nihao']:
print(item,end='-')
>>>
hello-123-nihao-
4.2.2 无限循环while
a = 3
while a > 0:
print(a)
a = a - 1
>>>
3
2
1
4.2.3循环控制break和continue
break:结束当前整个循环,去执行循环之后的语句。注意:只退出一层循环!
continue:跳过次轮循环,去执行下一轮循环,并没有完全退出循环
for c in 'python':
if c == 'h':
continue #遇到字符'h',跳过此次循环,继续下一轮循环
print(c,end='')
>>>pyton
for c in 'python':
if c == 'h':
break #遇到字符'h',结束整个循环
print(c,end='')
>>>pyt
4.2.4循环与else
如果循环没有被break结束,就奖励执行else语句。

4.3 random库的使用
总共8个函数:

4.3.1 基本随机数函数
random()的作用:随机生成一个0.0~1.0的小数
为什么要加种子:一旦种子确定,每次生成的随机数就是确定的,
如:种子seed(10),每次生成的第一个随机数一定是0.57…
故种子有利于代码重现。
import random
random.seed(10)
for i in range(3):
print(random.random())
>>>
0.5714025946899135
0.4288890546751146
0.5780913011344704
4.3.2 扩展随机数函数
randint(a, b): 生成一个[a,b]之间的整数
uniform(a, b)): 生成一个[a,b]之间的小数
randrange(m,n,[k]):生成一个[m,n)之间以k为步长的整数
getrandbits(k):生成一个k比特(k位)长的整数 注: 1比特(bit)=位;1字节(byte)=8位=8比特
choice(seq):从序列seq中随机选一个元素
shuffle(seq):将序列seq中元素随机打乱,无返回值
import random
print(random.randint(10, 20)) #随机生成一个10到20的整数
print(random.uniform(10, 20)) #随机生成一个10到20的小数
print(random.randrange(10, 80, 10)) #生成一个[10,80)之间以10为步长的整数
print(random.getrandbits(8)) #生成一个8位(比特)的整数
print(random.choice([1,2,3,4,5,6]))#从序列seq中随机选一个元素
s = [1,2,3,4,5,6,7,8]
random.shuffle(s) #因为shuffle函数没有返回值,因此不能直接输出
print(s)
>>>
20
12.180292396424115
60
200
6
[8, 4, 3, 7, 5, 2, 6, 1]
4.4 实例6:蒙特卡罗法计算圆周率
#蒙特卡罗方法计算圆周率
from time import perf_counter
from random import random
start = perf_counter()
NUM = 1000 * 1000 #撒点总数
num = 0 #落在圆内的点数
for i in range(NUM):
x, y = random(), random()#产生两个0-1的数,即该点的横纵坐标
dist = pow(x**2 + y**2, 0.5)#该点到圆心的距离
if dist <= 1: #若该点到原点距离小于1,则认为它落在了圆内
num += 1
pi = num/NUM * 4
print('圆周率是{}'.format(pi))
print('运行时间是{:.5f}s'.format(perf_counter()-start))
>>>
圆周率是3.143676
运行时间是3.88839s
5.函数与代码复用
5.1函数的定义与使用
格式:
def 函数名 (参数):
函数体
return 返回值
5.1.1函数的参数
可有可无
无参数:
def fact():
print('hello world')
fact() #调用函数
有参数:
#求n的阶乘n!
def fact(n):
result = 1
for i in range(1,n+1):
result = result * i
return result
x = fact(3)
print(x)
1.可选参数

格式:
def 函数名(非可选参数,可选参数)
注意:1.非可选参数 必须在 可选参数 之前
2.若可选参数没填,则默认为函数定义时的值;
若可选参数填了,则按调用时的值。
#求n的阶乘,然后除以m 即:n!//m
def fact(n, m = 1): #第二个参数是可选的
s = 1
for i in range(1, n+1):
s = s * i
return s//m
print(fact(10)) #第二个参数没填,则按定义时的m=1
print(fact(10, 5)) #第二个参数填了,则按m=5
print(fact(n=10,m=5))
print(fact(m=5,n=10)) #利用参数名来对应
>>>
3628800
725760
725760
725760
2.可变参数
参数的数量不确定时用可变参数
(略)
5.1.2函数的返回值
返回值可有可无
return可以返回0个值,也可以返回多个值(逗号隔开)
def fact(n, m = 1):
s = 1
for i in range(1, n+1):
s = s * i
return n, m, s//m #返回值有三个
print(fact(10, 5)) #直接输出三个返回值
a,b,c = fact(10, 5) #将三个返回值分别赋值给a,b,c
print(a,b,c) #输出a,b,c
>>>
(10, 5, 725760) #直接输出三个返回值,会以元组形式输出,即 加括号,逗号隔开
10 5 725760
5.1.3全局变量与局部变量
1.使用规则


2.global限定词
不加global限定词的局部变量:
n, s = 10, 100
def fact(n):
s = 1
i = 1
while i <= n:
s = s * i
i = i + 1
return s
print(fact(n), s)
>>>3628800 100

在函数体内参数前加global限定词,声明为全局变量。
n, s = 10, 100
def fact(n):
global s # s成了全局变量
i = 1
while i <= n:
s = s * i
i = i + 1
return s
print(fact(n), s) #fact(n)与s值一样
>>>3628800 3628800
3.组合数据类型做参数
若局部变量是组合数据类型,且未在函数内创建,则等同于全局变量。
#ls是组合数据类型,且未在函数内创建,则为全局变量
ls = ['a', 'b']
def func(a):
ls.append(a) # append函数是给ls增加一个元素
return
func('c')
print(ls)
>>>
['a', 'b', 'c'] #ls等同于全局变量,所以函数外也加了元素'c'
#################################
#ls是组合数据类型,但在函数内又创建,则为局部变量
ls = ['a', 'b']
def func2(a):
ls = []
ls.append(a)
return
func2('c')
print(ls)
>>>
['a', 'b'] #ls等同于局部变量,所以出了函数,内部的ls被销毁,所以并没有加元素'c'
4. lambda函数
<函数名> = lambda <参数> :<表达式>
f = lambda x , y : x + y
f = lambda x, y : x + y
print(f(1, 2))
>>>3
f1 = lambda : 'hello world'
print(f1())
>>>hello world
ls = ['a', 'b']
f2 = lambda a : ls.append(a)
f2('c')
print(ls)
>>>['a', 'b', 'c']
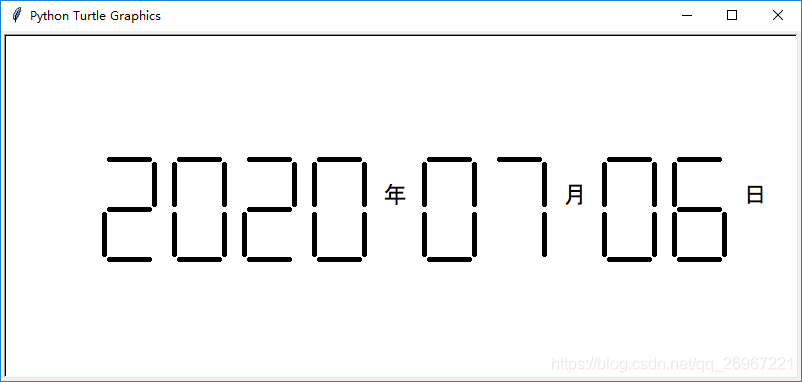
5.2实例7 七段数码管的绘制

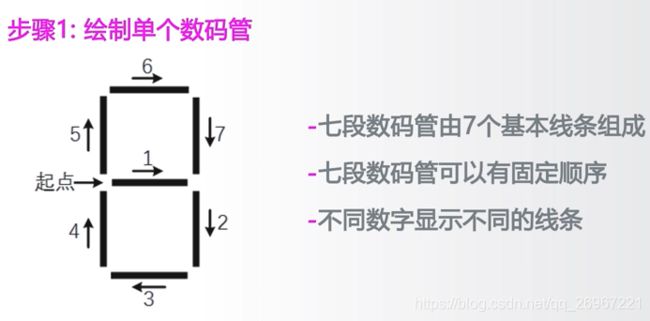
import turtle
import time
def drawGap(): #绘制数码管间隔
turtle.penup()
turtle.fd(5)
def drawLine(draw): #绘制单条线,参数为真则落笔画实线,参数为假则抬笔画虚线
drawGap()
if draw:
turtle.pendown()
else:
turtle.penup()
turtle.fd(40) #每一条线,长度为40像素
drawGap()
turtle.right(90) #画完每一笔后,都将海龟头右转90度
def drawDigit(Digit): #绘制一个数字Digit,分了七步,每步画一条线
if Digit in [2,3,4,5,6,8,9]: #第一条线,如果数字是[2,3,4,5,6,8,9],则画实线,否则画虚线
drawLine(True) #以下的从第二条线开始,用了if...else的紧凑形式,功能是一样的
else:
drawLine(False)
drawLine(True) if Digit in [0,3,4,5,6,7,8,9] else drawLine(False) #if...else的紧凑形式
drawLine(True) if Digit in [0,2,3,5,6,8] else drawLine(False)
drawLine(True) if Digit in [0,1,2,6,8] else drawLine(False)
turtle.left(90)
drawLine(True) if Digit in [0,1,4,5,6,8,9] else drawLine(False)
drawLine(True) if Digit in [0,2,3,5,6,7,8,9] else drawLine(False)
drawLine(True) if Digit in [0,2,3,4,7,8,9] else drawLine(False)
turtle.left(180) #画完最后一条线后,海龟头左转180度,即 准备下一个数字的绘制
turtle.penup() #抬笔,向前(实际是向右)移动20像素,准备画下一个数字
turtle.fd(20)
def drawDate(date): #画一个完整的时间,其中参数为时间字符串,格式为'%Y-%m=%d+',
#则遇到'-'绘制汉字'年',遇到'='绘制汉字'月',遇到'+'绘制汉字'日'
for i in date:
if i == '-':
turtle.write('年', font=('Arial', 18, 'normal'))
turtle.fd(40)
elif i == '=':
turtle.write('月', font=('Arial', 18, 'normal'))
turtle.fd(40)
elif i == '+':
turtle.write('日', font=('Arial', 18, 'normal'))
else:
drawDigit(eval(i)) #用eval将时间字符串的每个字符转化成整型,才能作为drawDigit的参数
def main(): #主函数
turtle.hideturtle() #隐藏画笔形状
turtle.setup(800, 350, 200, 200)
turtle.penup()
turtle.fd(-300)
turtle.pensize(5)
t = time.gmtime() #获取时间,格式为计算机内部时间格式
ts = time.strftime('%Y-%m=%d+', t) #利用strftime函数,进行格式化,使时间格式为‘%Y-%m=%d+’
drawDate(ts)
turtle.done()
main()
5.3递归
5.3.1递归实现字符串逆序
##递归实现字符串逆序
def reverse1(s):
if s == '': #若s为空,则返回自己
return s
else: #若s不为空,则把第一个元素放在其他元素逆序之后的后面
return reverse1(s[1:]) + s[0]
def reverse2(s):
if s == '':
return s;
else: #若s不为空,则把最后一个元素放在其他元素逆序之后的前面
return s[-1] + reverse2(s[:-1])
s = '12345'
print(reverse1(s))
print(reverse2(s))
>>>54321
>>>54321
5.4 Pyinstaller库的使用
可以将 *.py 文件转化为可执行文件 *.exe
5.5 科赫雪花小包裹(没看)
6.组合数据类型
6.1集合类型
6.1.1定义
用大括号表示,逗号隔开,集合元素是唯一、不重复的,且没有先后顺序。
A = {1, 2, '12', (1, 2, '12')}
print(A)
>>>{1, 2, '12', (1, 2, '12')}
B = set('1233') # set函数新建一个集合,参数是字符串,返回该字符串拆开的单个字符组成的字符串,并去掉重复元素
print(B)
>>>{'1', '2', '3'}
C = {'python', 123, 'python', 123}
print(C)
>>>{123, 'python'} #自动去掉重复的元素
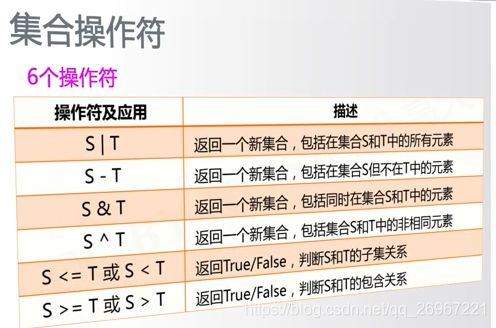
6.1.2集合操作符

6.1.3集合处理函数


遍历集合函数:
def trave1(A):
for item in A:
print(item, end=',')
def trave2(A):
try:
while True:
print(A.pop(), end=',') #pop函数,返回集合中的一个元素并将其删除,当集合为空时报错,转向执行except语句
except:
pass #pass是一条空语句,但此处不加pass还不行.
A = {1, 2, '12', (1, 2, '12')}
trave1(A)
trave2(A)
>>>12,1,2,(1, 2, '12'),
>>>12,1,2,(1, 2, '12'),
6.1.4数据去重
利用了集合中无重复元素的特点
ls = ["1", "2","1", "A", "A", "B"]#列表ls有重复元素
print(ls)
s = set(ls) #用set函数将列表转化成集合,则自动去除了重复元素
print(s)
ls = list(s)#再将集合转化成列表
print(ls)
>>>
['1', '2', '1', 'A', 'A', 'B']
{'1', '2', 'B', 'A'}
['1', '2', 'B', 'A']
6.2序列类型
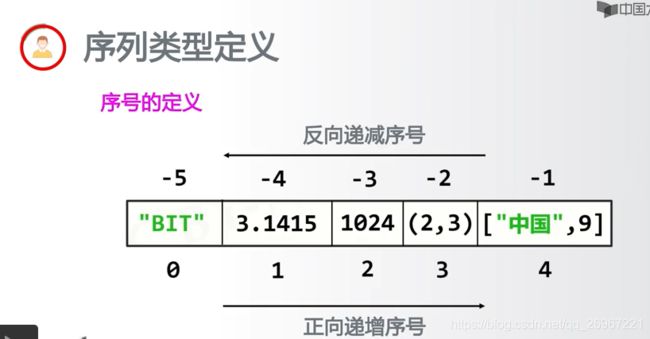
6.2.1定义及分类
序列类型扩展出:字符串类型、元组类型、列表类型
序列类型的操作符:
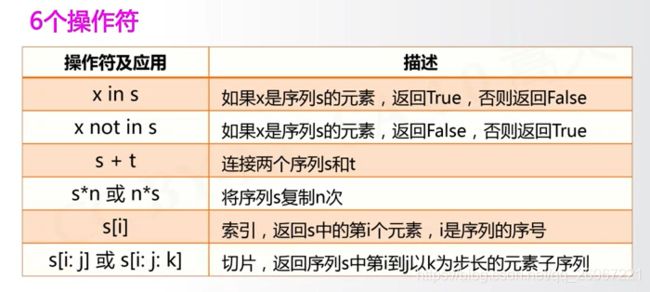
序列类型的函数:
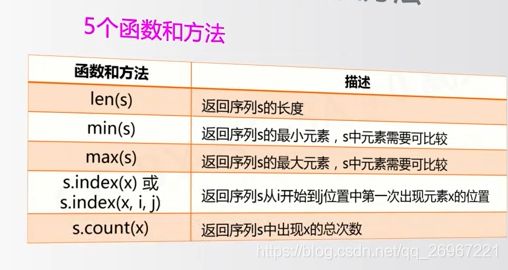
s = "python123.io"
print(max(s))
>>> y #字母之间的大小是通过字母序比较的,y是此字符串中最大的
6.2.2元组类型

animal = "cat", "dog", "pig"
print("元组animal: {}".format(animal))
A = (0x001100, "blue", animal) #元组的嵌套,A元组有三个元素,第三个元素也是一个元组
print("元组A: {}".format(A))
print(A[-1][1]) #两层索引,首先A[-1]是A元组的最后一个元素animal,然后animal[1]是animal元组的第1个元素dog
>>>元组animal: ('cat', 'dog', 'pig')
>>>元组A: (4352, 'blue', ('cat', 'dog', 'pig'))
>>>dog
animal = "cat", "dog", "pig"
A = animal[::-1] #animal元组本身元素顺序不变
print(animal)
print(A)
('cat', 'dog', 'pig')
('pig', 'dog', 'cat')
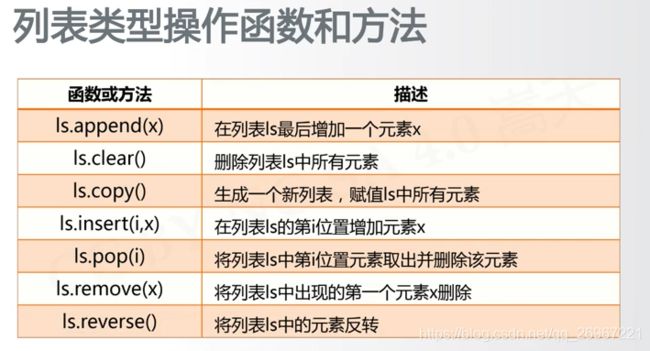
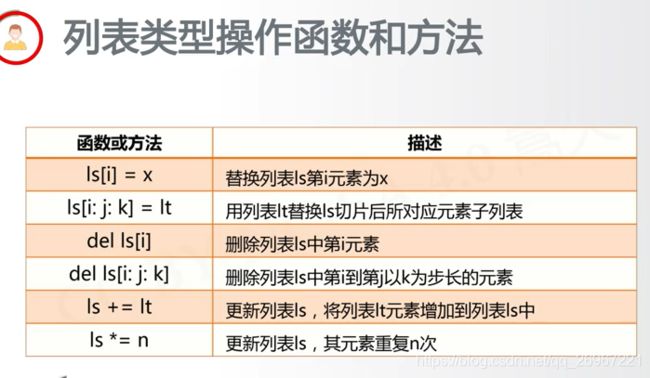
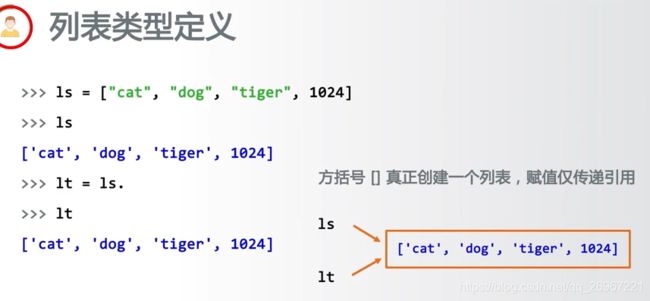
6.2.3列表类型
类似于C语言的数组,用方括号和逗号[a0, a1, …, an]
ls = ["cat", "dog", "tiger"]
print(ls)
ls1 = ls #并不是重新定义一个列表,而是同一个列表,有两个名字
print(ls1)

6.3实例9:基本统计值计算
##基本统计值计算
def getNum(): #获取输入数据
nums = []
iNumStr = input("请输入数字(回车退出):")
while iNumStr != "": #当输入不为空,即不是只敲了回车时,循环:
nums.append(eval(iNumStr)) #input返回值默认是str,所以需要eval转换
iNumStr = input("请输入数字(回车退出):")
return nums
def Avg(nums): #求平均值
s = 0.0
for num in nums:
s = s + num
return s/len(nums)
def dev(nums, avg): #求方差
sdev = 0.0
for num in nums:
sdev = sdev + (num - avg)**2
return pow(sdev/len(nums), 0.5)
def median(nums): #求中位数
sorted(nums) #python自带的排序函数
size = len(nums)
if size % 2 == 0:
med = (nums[size//2-1] + nums[size//2])/2
else:
med = nums[size//2]
return med
nums = getNum()
avg = Avg(nums)
print("平均值:{}, 方差:{:.2}, 中位数:{}\n".format(avg, dev(nums, avg), median(nums)))
6.4字典类型
6.4.1字典的定义
d = {} #新建一个空的字典
print(type(d))
>>><class 'dict'> # 大括号{}为空时,默认是字典,而不是集合。要建立空集合,用set函数


6.4.2字典类型的函数
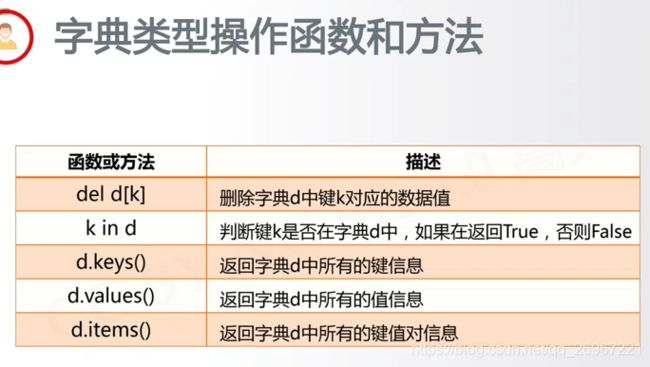
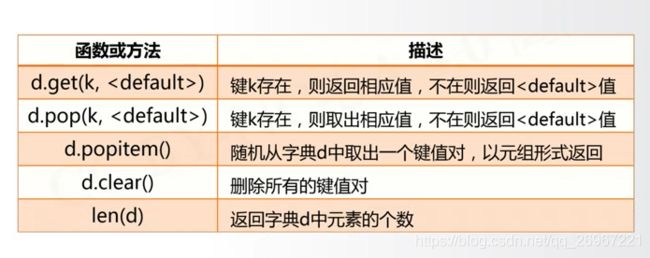
d = {1:"LL", "age":25}
print(d[1])
print(d.keys())
print(d.values())
print(d.items())
LL
dict_keys([1, 'age'])
dict_values(['LL', 25])
dict_items([(1, 'LL'), ('age', 25)])

6.5 jieba库的使用
6.5.1作用及安装

6.5.2 jieba分词的使用




import jieba
s = jieba.lcut("中国是一个伟大的国家") #返回值类型是列表形式
print(s)
>>>['中国', '是', '一个', '伟大', '的', '国家'] #返回值类型是列表形式
6.6 实例10:文本词频统计
1.哈姆雷特词频统计
# CalHamletV1.py
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_\'{}|~':
txt = txt.replace(ch, "")
return txt
hamletText = getText()
words = hamletText.split() # 以空格为分界线分割,存入一个列表
counts = {} # 空字典
for word in words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
2.三国演义词频统计
#CalThreeKingdomsV2.py
import jieba
txt = open("三国演义.txt","r",encoding="utf-8").read()
excludes={"将军","却说","荆州","二人","不可","不能","如此"}
words = jieba.lcut(txt)
counts ={}
for word in words:
if len(word)== 1:
continue
elif word=="诸葛亮"or word=="孔明曰":
rword="孔明"
elif word =="关公"or word =="云长":
rword="关羽"
elif word=="玄德"or word=="玄德日":
rword="刘备"
elif word=="孟德"or word=="丞相日":
rword="曹操"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))